













【51CTO.com快译】在边缘技术领域,那些从事制造业、自动化行业、航空、物流、以及零售等行业应用的开发人员经常会思考的一个问题是:到底应该在边缘处,还是应该在“真实”的数据中心、或是在公共云基础架构中部署Apache Kafka?
在本文中,我们将向边缘计算领域的开发者介绍Kafka在物联网(IoT)边缘处的不同用例和架构用法。文末,我们还会讨论Kafka作为事件流平台,是如何在边缘处对其他IoT框架及产品进行补充,进而实现大规模的实时数据集成与边缘处理。
常态化的多个Kafka群集
如今,Apache Kafka的多集群和跨数据中心的部署方式,已成为了业界的某种规范。虽然“边缘处Kafka(Kafka at the edge)”可以被部署为一个独立的项目;但是在大多数情况下,它处于整个Kafka架构中的一部分。许多企业会根据如下原因,来创建多个Kafka集群:
- 独立的项目需求。
- 混合式的集成方法。
- 边缘计算。
- 组件聚合。
- 平台移植。
- 灾难恢复。
- 区域或洲际通信所需的全球架构。
- 跨企业之间的沟通。
什么是“边缘”或“边缘计算”?
在考虑部署边缘处Kafka之前,让我们先来了解一下与“边缘技术”相关的定义。维基百科上说:“边缘计算是一种分布式的计算范式。它通过让计算本身和数据存储更加靠近所需的位置,从而缩短了响应的时间并节省了带宽”。同时,它的其他优势还包括:降低成本,提高系统的灵活性,以及分离关注点。
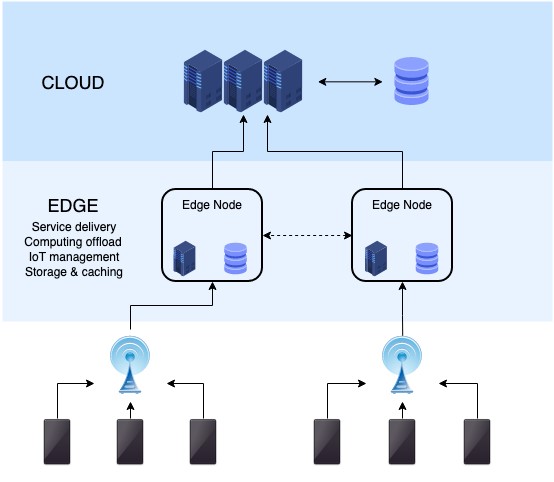
边缘的Apache Kafka
目前,业界对如何将Kafka应用于边缘计算有着不同的见解,其中包括:
- 仅在边缘客户端:Kafka客户端运行在边缘处;而Kafka集群则被部署在数据中心或公共云的环境中。
- 一切都在边缘:将Kafka集群和Kafka客户端都部署在边缘处(例如工厂里的各种传感器上)。
- 边缘与远端:Kafka集群被部署在边缘;而Kafka客户端(例如该地区的智能手机)则运行在接近边缘处。
可见,边缘处Kafka具有比较灵活且广泛的使用范围,其中包括:
- 工业物联网(Industrial Internet of Things,IIoT)车间边缘处的Kafka客户端可以由C语言来编写,并部署到传感器的微控制器中。此类传感器通常只有几千个字节的内存,而且可以“服役”一定的年限。
- 在电信业务中边缘处,完整的分布式Kafka集群,可以运行在StarlingX上(https://www.starlingx.io/)。StarlingX是一个基于Kubernetes的开源私有云架构栈,可被用于IIoT、电信、视频交付、以及其他具有超低延迟等苛刻要求的应用边缘环境中。
- 通过部署,衔接传统银行或保险公司的核心硬件与边缘硬件。
可见,在大多数情况下,边缘处Kafka就是指:部署在系统边缘处的Kafka集群。而对应的Kafka客户端程序既可以在本地运行,也可以在附近运行。当然在某些情况下,“附近”可能在指几英里开外。
边缘处Kafka的用例
下面,我们来讨论一下边缘处Kafka在许多不同企业中的运行用例。
- 工业物联网:实时边缘集成与处理,是现代物联网架构成功的关键。在工业4.0中,此类用例比比皆是,包括:预测性维护、质量保证、流程优化、以及网络安全等方面。其中使用Kafka来构建数字孪生(Digital Twin,译者注:在虚拟空间中仿真、映射并反映对应的实体设备的整个生命周期过程)就是最常见的场景之一。
- 零售:无论是沃尔玛这样的零售商,还是星巴克之类的咖啡店,抑或亚马逊Go之流的潮店,数字化转型都会带来许多方面的创新。其中包括:客户的360度体验,商家与消费者之间的交叉销售,以及与其他合作供应商的协作等方面。
- 物流:大规模的实时数据关联,是改变任何物流场景的关键元素。其中包括:端到端的包裹跟踪和交付,无人机(或自动驾驶)与本地自助服务站的通信,物流中心的加速处理,共享汽车的协调和计划,以及智慧城市中的交通信号灯管理等方面。
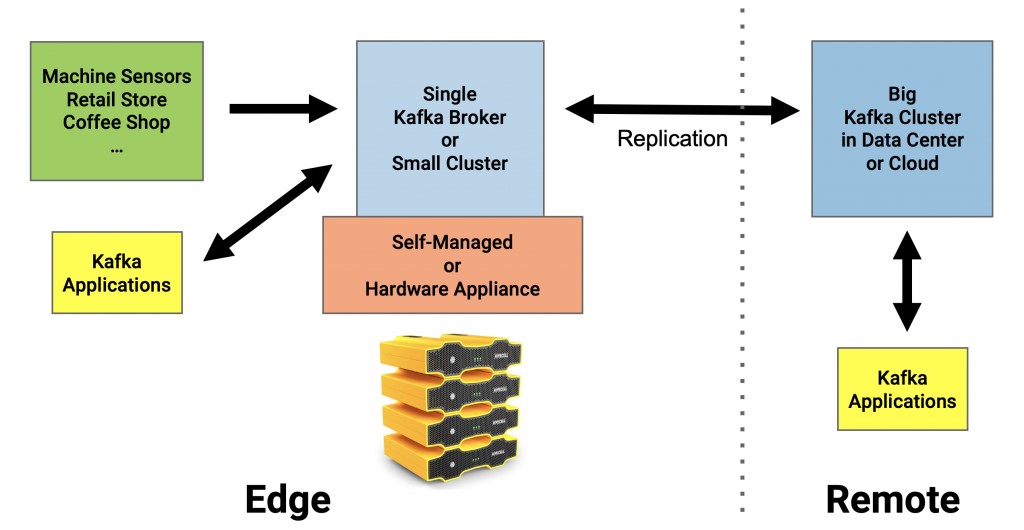
无论是上述哪种用例,边缘处Kafka的通用架构都会如下图所示:
边缘计算的挑战
在企业试图将各种创新的实时应用引入工厂、零售店、咖啡店等场景,并将数据分发到边缘站点时,往往会遇到如下的挑战:
- 由于不良的网络状态和许多其他方面的限制,边缘处的各种硬件、机器、以及设备难以顺畅实现集成。
- 许多用例都要求进行大规模的、且实时的处理。而这些处理都必须在现场边缘处实施,而不是在远端的数据中心、或几百英里开外的云端进行。
- 各种技术和协议都必须在边缘处集成。而且各种传统或专有的协议,必须通过隧道,与另一端的大数据工具进行通信。
- 有限的硬件资源与人员。鉴于成本的考虑,IT专家无法到达每一个边缘站点,进行硬件的运维。
- 各种数据必须大规模地在本地进行实时存储和处理。同时,这些数据需要被复制到数据中心或云端,以便进一步汇总、处理与分析。另外,为了实现由单一节点以发送命令或事件的方式控制各个边缘站点,各种通信最好是双向的。
用于边缘计算的Kafka架构
在开始讨论有哪些边缘处Kafka的部署方案之前,我们需要事先搞清楚的一个问题是:到底是否需要高可用性的边缘架构。
其实,边缘计算并不一定需要具有高可用性。如果您的确需要的话,就请部署传统的Kafka集群;而如果不需要的话,则只需在边缘处设置一个简单、且低成本的Kafka Broker即可。而且如果需要在上百个站点进行部署的话,那么现成的硬件设备会更加容易实现。
下图展示了三个边缘站点。每个站点上都部署了一个Kafka集群,而每个集群里都包括有不同的Kafka组件。

通过三个以上的Kafka Broker在边缘实现弹性部署
Kafka及其生态系统旨在确保即使某一单个节点发生故障,也能实现系统的高可用性和零停机时间。如下图所示,为了部署一套分布式的系统,您至少需要三个Kafka节点和三个Zookeeper节点。而其他组件则需要至少两个节点,才能确保操作的可靠性和数据的防丢失。
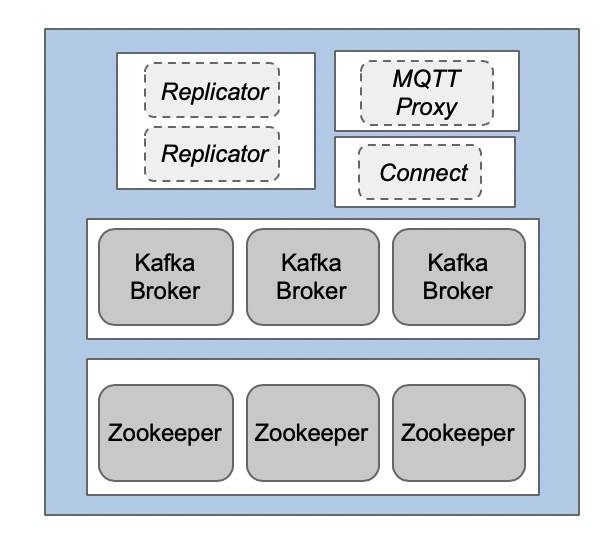
您可以参考《Apache Kafka与Confluent平台参考架构》一文,以了解部署的最佳实践。当然,由于流量负载和吞吐量通常在边缘处都比较低,因此如果SLA允许的话,较少的内存与磁盘空间也就足够了。
通过一个Kafka Broker在边缘实现非弹性部署
如今,在边缘处部署“轻量级的Kafka群集”,然后与更大的中央Kafka群集同步或复制数据的需求已日益增多。不过,由于硬件本身的限制、以及SLA对于高可用性的要求并不高,因此在边缘处仅部署一个Kafka Broker加上一个Zookeeper即可。如下图所示,您甚至可以将整个Kafka的环境只部署在一台服务器上。
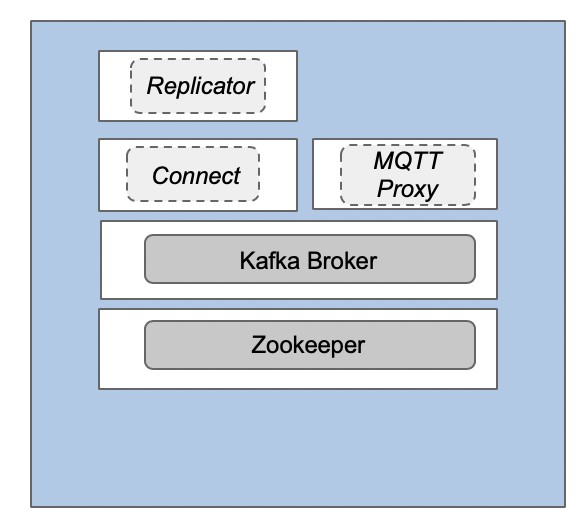
不过,该部署方案存在着一个明显的缺陷:由于没有数据之间的复制,当该节点或网络出现故障而造成停机时,您的数据就有丢失的风险。当然,此类单节点式的Kafka部署方案仍具有如下方面的优势:
- 实现了producers与consumers之间的解耦。
- 能够有效地处理背压(back-pressure)。
- 即使只有一个Broker,也能实现实时地处理大容量数据。
- 在磁盘上进行存储。
- 能够重新处理数据。
- Kafka Connect可用于集成,Kafka Streams或ksqlDB可用于流处理,Schema Registry可用于管理,真可谓Kafka本地组件的“全家桶”。
移除ZooKeeper将有助于边缘处Kafka
和诸如Hadoop、Spark等其他分布式系统类似,由于过分依赖于ZooKeeper,因此Kafka不但在操作上有一定的难度,而且扩展性也比较差。那么对于大多数物联网项目而言,由于整体部署的耗时较长,我们建议您通过移除ZooKeeper,而使得Kafka更轻量级,更易于操作。
将Kafka作为边缘设备和云服务之间的网关
在某些配置中,您可能希望边缘设备与本地的网关进行通信。此时,您就可以使用网关式的Kafka架构方案。例如,在工厂中,多台机器或生产线被视为边缘设备。它们需要与各自的Kafka群集相集成,实现将数据发送给作为网关的Kafka群集。据此,在Kafka集群网关上,您可以直接在本地进行分析,通过过滤或转换数据,最终发送并聚合到远程大型的Kafka集群中。
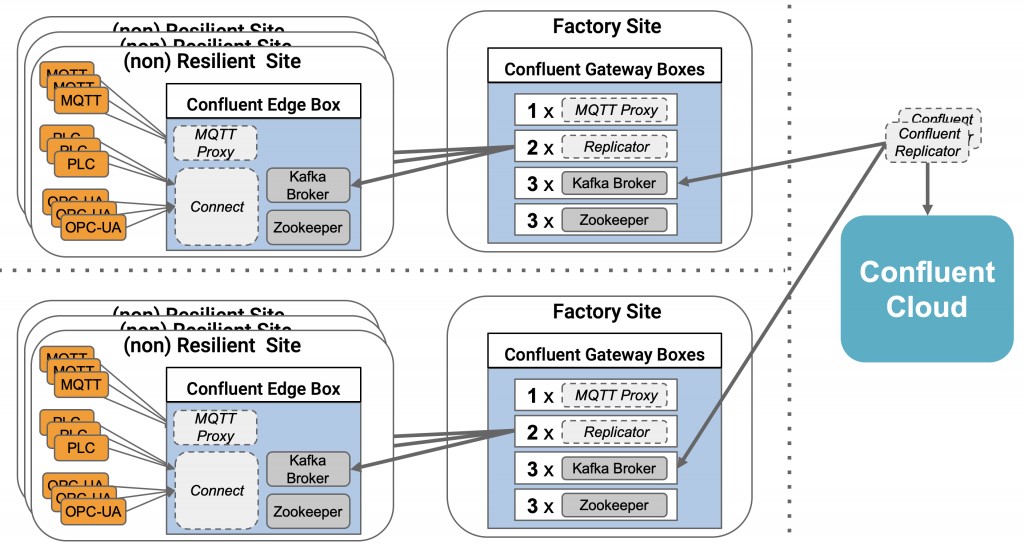
如上图所示:首先,两个独立的工厂分别在各处部署了非弹性的单一Kafka Broker,以实现数据的本地处理。然后,由一个弹性Kafka群集网关聚合三个Kafka Broker,并在工厂的本地处理各项数据。接着,只有那些重要、且经过预处理的数据才会被转发到远程的Kafka群集中(在图中体现为Confluent Cloud)。最终,该云中的Kafka集群聚集了来自不同工厂的数据,以便与其他业务应用或分析工具相集成。
边缘处Kafka作为OEM或硬件组件
企业在边缘处安装硬件,会比在本地数据中心、或公共云端要复杂且麻烦得多。如果我们在边缘处采用标准化的Kafka组件安装方法,则会大幅减少工作量与潜在的风险。
目前,已有数十家硬件供应商可以协助您构建OEM的硬件设备。当然,您也可以通过远程管理并使用某些DevOps工具,来安装所有必需的软件组件。
为了简化安装和操作边缘处Kafka集群,以Hivecell(https://hivecell.io/)为代表,公司推出了预装有Kubernetes、Kafka生态系统、Confluent Operator(https://www.confluent.io/confluent-operator/)工具、以及其他业务应用的产品盒子。它能够简化并自动化边缘处Kafka环境中的各项操作。用户只需将一个或多个产品盒子运到边缘站点。在将其连接到本地WiFi之后,其他所有的操作都可以在远程进行实现。该公司甚至号称:能够让客户不再需要技术人员,即可在边缘部署和维护软件。
通信、连接、集成、数据处理
正如上述各图所展示的那样,Kafka的环境中并不仅仅包括了Kafka Broker与Zookeeper。无论是在云端、本地、还是在边缘处,通信、连接、集成、以及数据处理都是Kafka基础架构中的重要组件。
具体而言,在Kafka Broker与Kafka客户端之间,从边缘处到远程的通信流程为:设备->边缘处Kafka->复制->数据中心与云端的Kafka群集->数据分析与实时处理。通常,此类通信是双向的。那么对于Kafka原生的各个组件而言,您只需要管理一个Kafak的后台,即可进行大规模的实时通信、集成和数据处理。其中涉及如下方面:
- Kafka Connect:包括MQTT(消息队列遥测传输)、OPC-UA、FTP、CSV、PLC4X(一组传统与专有IIoT协议,例如Modbus、Siemens S7、Beckhoff、Allen Bradley四种可编程序控制器,即PLC)。
- Mirror maker与Confluent Replicator:实现两个Kafka群集之间的单向或双向复制。
- Kafka客户端(Producers/Consumers):支持Java、Python、C++、C、Go、Javascript等语言。
- 数据处理:使用Kafka Streams或ksqlDB进行流处理(包括无状态流的ETL和其他有状态的应用)。
- 代理:使用REST proxy进行HTTP(S)通信,使用MQTT proxy进行MQTT集成。
- 架构注册表:负责治理与模式的实施。
可见,由于边缘处硬件资源的受限,我们应当在开始时就规划好整体架构和数据通信,让Kafka全栈能够真正满足边缘的需求。
混合架构
物联网的实际需求往往是五花八门的。面对24小时/7天的实时部署,零数据量的丢失,以及无延迟的实时处理,我们光靠Kafka架构有时会力不从心。此时,我们就需要结合使用其他的IoT框架或方案,来实现与Kafka的端到端集成。
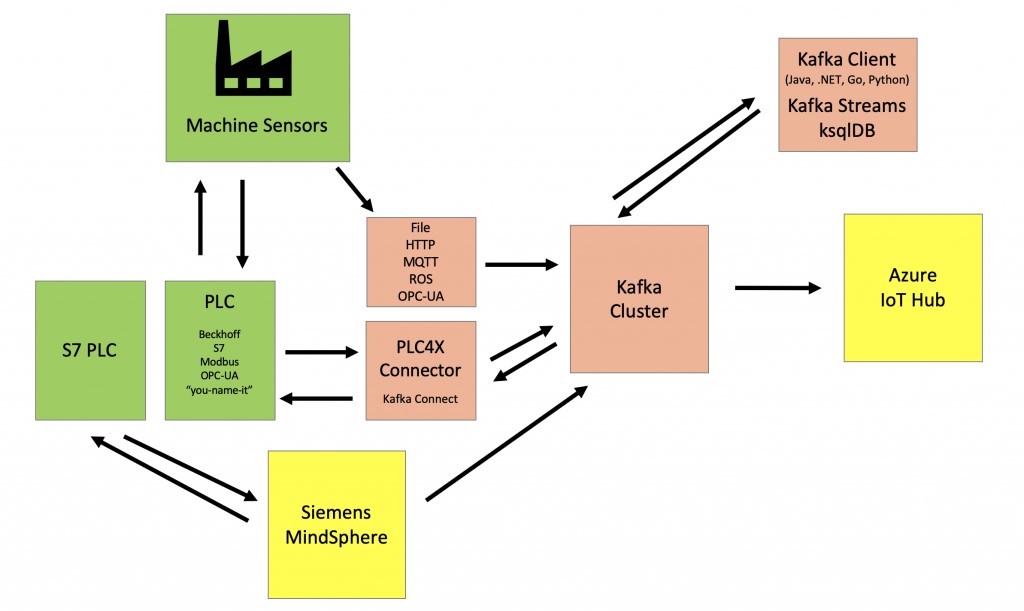
如上图所示,我们可以在工厂车间里使用西门子的MindSphere(这是一种功能强大,适用范围广泛,但也复杂且昂贵的物联网解决方案),来作为网关或代理。当然,我们可以将HiveMQ(译者注:一种企业级的MQTT Broker)部署为可扩展的MQTT集群,以连接到机器和设备。
在某些情况下,Kafka也可以被直接用作IoT的网关或代理,以连接PLC或分布式控制系统(Distributed Control System,DCS)。同时,Kafka也可连接诸如AWS IoT或谷歌云的MQTT Bridge等IoT解决方案,实现进一步的处理和分析。
由于数据通信往往是双向的,因此无论您选择哪一种架构,都必须能够从车间或其他IoT设备中提取数据,通过实时的处理与关联,最后将控制类事件发回给机器。例如:在预测分析中,您首先需要使用TensorFlow之类的云端工具训练分析模型,然后才能在边缘处部署分析模型,以进行实时预测。
可见,通过与其他物联网框架或解决方案的结合,Kafka生态系统不但得到了有效的补足,而且各自都能够专注于不同的功能用例之中。例如:Kafka可专注于设备管理,模型训练。主流的云提供商能够为设备管理提供IoT服务、云端代理、以及分析工具。而开源的框架Eclipse则可以用于构建数字孪生。
慎用过多的分布式系统组合
当然,如果您想为边缘计算和混合架构构建可扩展的、可靠的流式结构,并且达到不会造成任何宕机或数据丢失的效果,这实际上很难在集成了多种中间件工具的环境中实现。也就是说:参与组合的工具越多,服务中断或数据丢失的风险也就越高。例如:NiFi(译者注:Apache的NiFi项目是一种实时数据流处理系统)有着自己的分布式基础架构,那么您必须保证从producer通过NiFi和Kafka能够最终到达consumer,这整个过程都具有24小时/7天的端到端正常运行时间。同理,诸如Kafka Connect和Kafka Streams之类的原生工具,使用Kafka Topic在后台提供高可用性时,您也需要保障此类24小时/7天的无宕机或数据丢失。因此,请慎用“传感器ABC -> NiFi(捕获) -> Kafka Topic A -> NiFi(转换) -> Kafka Topic B -> NiFi(加载) -> 应用程序XYZ”之类的管道架构,来进行无数据丢失的大规模实时处理。
总结
边缘计算往往只是整个体系结构的一部分,但是作为该领域的“黑马”,边缘处Kafka可以通过混合架构的部署方式,提高数据的处理速度,降低网络的传输成本,并且能给整个系统带来更好可扩展性、可靠性和健壮性。
原文标题:Apache Kafka Is the New Black at the Edge in IoT Projects,作者:Kai Wähner
【51CTO译稿,合作站点转载请注明原文译者和出处为51CTO.com】

























