新代码在自家芯片上运行状况如何?英特尔自己都没有别人家的新工具清楚。
这就是MIT耗时一年提出的研究成果,名为Ithemal,核心功能也非常简单:
能够分析数以百万计自动描述的基本块(计算指令的基本片段),来确切了解不同的芯片机构如何执行计算。

效果也非常惊艳。
MIT News透露,传统基于人工设计的模型,预测代码在芯片上的运行速度,与实际运行速度之间的错误率高达50%。
就算是芯片供应商,比如英特尔预测代码在自己芯片上的运行速度,错误率也达到20%。而Ithemal,错误率仅为10%。
性能是传统方法的5倍,英特尔的2倍。
整个过程都是自动化的,不需要人为干预,就能够快速分析数十万或数百万个基本块。
并且通用,它可以快速学习代码在任何新的芯片架构的性能速度,无论是机器学习炼丹,还是加密技术上链、还是编译器优化等等,都能hold住。
研究人员分享了这样的一个使用场景:
如果你想在一个新的芯片架构上训练一个模型,比如谷歌的TPU,你只需要从这个架构中收集数据,经过分析器运行后,去训练Ithemal,你可以得到一个可以预测其性能的模型。”
对于充分发挥芯片性能,让代码运行更有效率,这是具有突破性意义的一项进展。
基于神经网络,避开“盲人摸象”
通常情况下,为了让代码能够在芯片上高效地运行,开发者会结合编译器设计一个性能模型,模拟代码在芯片架构上的运行情况。
开发者会根据这些信息进一步优化代码,进一步提高代码运行效率,突破芯片的性能瓶颈。
这种思路虽然没什么问题,麻烦出在如何设计性能模型上,传统的方法是一小部分专家来人工设计。
面对错综复杂的芯片架构,这多少有些“盲人摸象”的感觉,就英特尔一家,描述其芯片架构的文档, 多达3000页。
而且这些内容也不一定完整,考虑到商业竞争以及技术保密上的考虑,英特尔也会去刻意忽略一些内容,这无疑又加大了困难——盲人摸到的象,可能缺胳膊少腿。
更别提现代的芯片架构设计了,不仅不透明,而且及其复杂,难以理解。想要得到一个性能模型,很难;想要得到一个更精确的性能模型,更难。
MIT的方法中,一开始就绕开了“盲人摸象”的困境,而是建立神经网路,从“数据”中学习。
这个数据,就是芯片执行“基本块”所需的平均周期数,不需要手动添加任何特征。
就算输入之前没有“看到”过的基本块和芯片架构,训练好的模型也能够给出数字,来更准确地预测芯片执行代码的速度。
正所谓冰冻三尺,并非一日之寒。
MIT这款强大工具的诞生也是Step By Step。
第一步:用“基本块”训练标记数据
首先,研究人员提出了一种神经网络工具——以“基本块”的形式训练标记数据。
这样做的目的就是可以自动预测给定芯片中,执行基本块所需要的时间。
结果表明,比起传统的手工调整模型,精确度上要高得多。
这个工具叫做Ithemal,研究还发表在了ICML 2019上。

Ithemal的全名叫做“Instruction THroughput Estimator using MAchine Learning”。
受深度神经网络的灵感,它采用了一种新型的数据驱动方法来预测一条指令块的吞吐量。
Ithemal将吞吐量估计问题建模为一个回归任务,并利用DNN使用大量标记数据集将序列映射为实际值的吞吐量,以此来学习如何预测。
更具体点来说,Ithemal使用分层多尺度RNN,让每条指令生成一个独立的嵌入,然后依次结合指令嵌入来预测吞吐量。
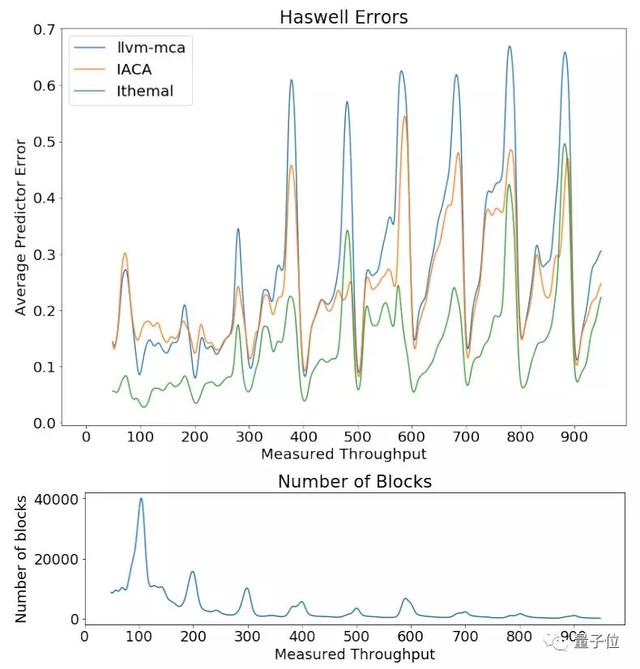
在所有基准测试中,平均绝对百分误差(MAPE)降低了50%以上,同时仍然提供了较快的估计速度。
在生成高质量的预测时,Ithemal只需要训练数据和ISA的规范,包括指令规范及其显式和隐式操作数。
并且与分析模型不同,Ithemal不需要任何明确的规范或建模,只需要学习有助于提高吞吐量的任何显著的微体系结构细节即可。
研究人员还将Ithemal相关资源开源在了GitHub上:
https://github.com/psg-mit/Ithemal
第二步:推出性能模型验证套件
接着,在去年11月的IEEE International Symposium on Workload Characterization大会上,研究人员提出了一个基准测试套件。

这个套件由来自不同领域的基本块组成,包括机器学习、编译器、密码学和图形,可以用来验证性能模型。
值得注意的是,这项研究是和谷歌合力完成。
他们将30多万个数据块汇集到了BHive,这是对x86-64基本块的性能模型进行系统验证的基准。
研究人员使用BHive评估了四个现有的性能模型:IACA,llvm-mca,Ithemal和OSACA。
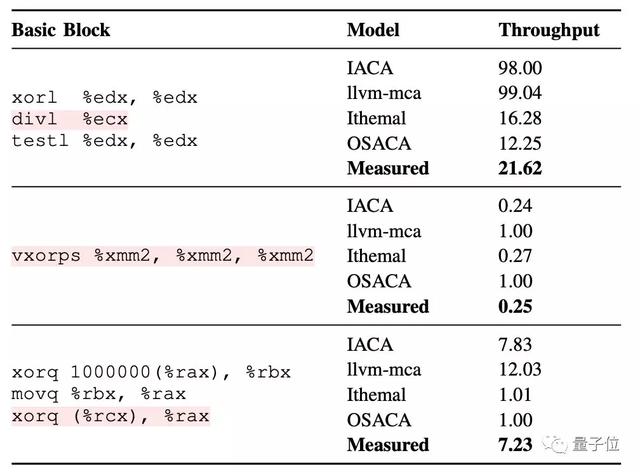
△基本块和它们的预测吞吐量
在他们的评估中,Ithemal预测英特尔芯片运行代码的速度,要比英特尔自己建立的性能模型还要快。
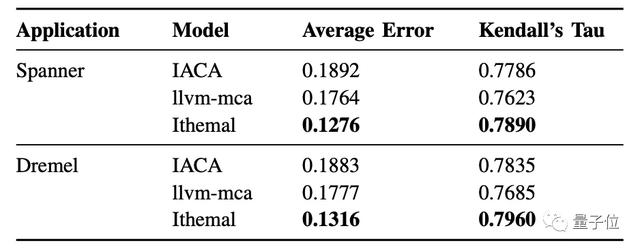
并且,研究人员的数据集很好地捕捉了两个Google应用程序的基本属性:Spanner和Dremel。
到了这一步,开发人员和编译器可以使用该工具来生成代码,这些代码可以在多样化“黑盒子”芯片设计上更快,更高效地运行。
电子工程与计算机科学(EECS)系助理教授Michael Carbin表示:
现代的计算机处理器不透明,复杂得可怕,难以理解。编写对这些处理器执行得尽可能快的计算机代码也面临着巨大的挑战。
这个工具是朝着对这些芯片的性能进行完全建模,以此来提高效率的重要一步。
第三步:自动生成编译器优化
最后,在去年12月份的NeurIPS 会议上,研究人员提出了一种自动生成编译器优化的新技术。
具体来说,他们自动生成一个算法,称为Vemal,将特定的代码转换为向量,可用于并行计算。
相对于 LLVM 编译器(业界流行的编译器)中使用的手工矢量化算法,Vemal 的性能要更好。
这项主要就是探讨了拟合一个图神经网络策略来模拟由其(整数线性规划)ILP解所做出的最优决策是否可行。
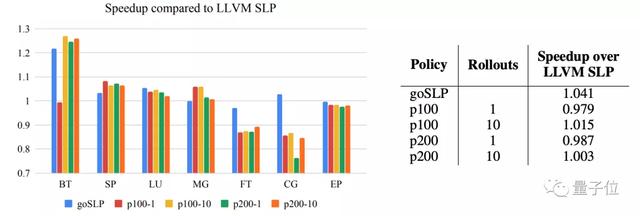
结果表明,该策略生成的矢量化方案在静态度量和运行时性能上都优于行业标准的编译启发式算法。
来自MIT计算机科学与人工智能实验室
这三篇论文,都是出自MIT人工智能研究重地——计算机科学与人工智能实验室,简称CSAIL。
核心人物为Charith Mendis,三篇论文中,有两篇他是一作。
他出生于斯里兰卡,读硕士的时候来到麻省理工,是ACM Fellow、CSAIL学术带头人Saman Amarasinghe的关门弟子——最后一名博士生。
2015年名称在微软雷蒙德研究院实习,主要的研究方向就是编译器、程序分析与机器学习。
他希望,未来大多数编译器优化将自动生成和学习,而不是手动编写。它们不仅会产生更快的代码,而且将更易于开发和维护。
而现在一系列的工作,就是在朝着这个方向发展。
而眼前的下一步,他们将会发力研究使模型可解释的方法,来弄清楚为什么特定的模型会做出预测。
传送门
博客地址:
http://news.mit.edu/2020/tool-how-fast-code-run-chip-0106
Ithemal论文地址:
http://proceedings.mlr.press/v97/mendis19a/mendis19a.pdf
BHive论文地址:
http://groups.csail.mit.edu/commit/papers/19/ithemal-measurement.pdf
自动生成编译器优化论文地址:
http://papers.nips.cc/paper/9604-compiler-auto-vectorization-with-imitation-learning.pdf