计算机视觉正在加速行业中几乎每个领域的发展。 在计算机视觉技术的帮助下,组织正在彻底改变机器以前的工作方式。 现在,全球各地的大型技术都在利用计算机视觉技术领域,例如医疗保健和自动驾驶等。 为了建立强大的计算机视觉深度学习模型,必须在训练阶段应用高质量的数据集。

在本文中,我们将列出10个可用于Computer Vision项目的高质量数据集。
1 | CIFAR-10

CIFAR-10是Alex Krizhevsky,Vinod Nair和Geoffrey Hinton收集的一种流行的计算机视觉数据集。 该数据集用于对象识别,由10类60,000张32×32彩色图像组成,每类6,000张图像。 它分为五个训练批次和一个测试批次,每个批次具有10,000张图像,这意味着有50,000个训练图像和10,000个测试图像。
2 | Cityscapes

Cityscapes是Computer Vision项目的开源大规模数据集,其中包含来自50个不同城市的街道场景中记录的各种立体视频序列。它包括5,000个帧的高质量像素级注释,以及20,000个弱注释帧的较大集合。 该数据集主要用于训练深度神经网络和评估视觉算法对语义城市场景理解的主要任务的性能。
3 | Fashion MNIST

Fashion-MNIST是用于Computer Vision的图像数据集,包含60,000个示例的训练集和10,000个示例的测试集。 在此数据集中,每个示例都是一个28×28灰度图像,与来自10个类别的标签关联。 有一个基于Scikit-learn的自动基准测试系统,该系统涵盖129个具有不同参数的分类器。
4 | ImageNet
ImageNet是计算机视觉项目最受欢迎的数据集之一,它提供了一个可访问的图像数据库,该数据库根据WordNet层次结构进行组织。WordNet中有超过100,000个同义词集,其中ImageNet提供平均1,000个图像来说明WordNet中的每个同义词集。 它为WordNet层次结构中的大多数概念提供了数千万个干净排序的图像。
5| IMDB-Wiki Dataset

IMDB-Wiki数据集是使用性别和年龄标签进行训练的最大的开放式人脸图像数据集之一。此数据集中总共有523,051张面部图像,其中从IMDB的20,284名名人和维基百科的62,328名名人获得了460,723张面部图像。
6 | Kinetics-700
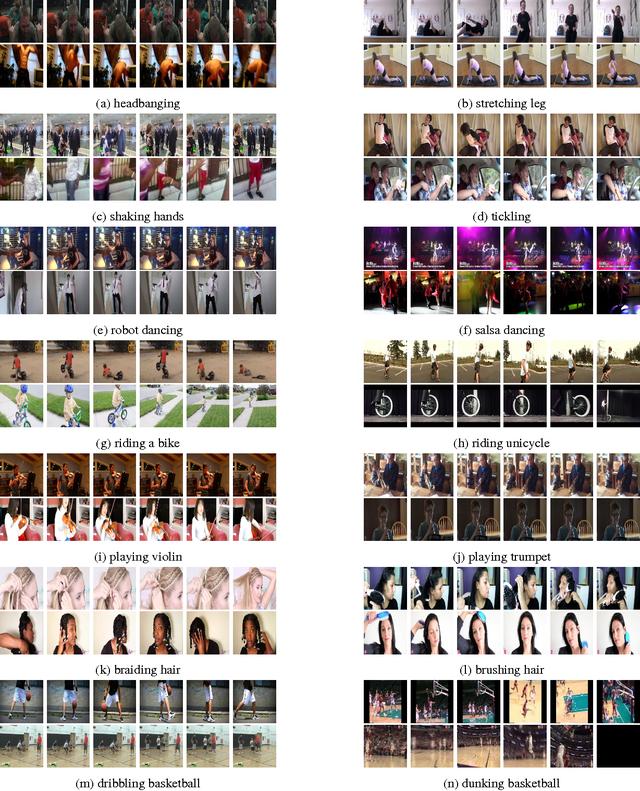
Kinetics-700是YouTube视频URL的大规模高质量数据集,其中包括各种以人为中心的动作。 数据集包括大约650,000个视频剪辑,涵盖700个人类动作类,每个动作类至少包含600个视频剪辑。 在这里,每个剪辑持续约10秒钟,并标有一个类别。
7 | MS Coco

COntext中的COCO或Common Objects是大规模的对象检测,分割和字幕数据集。 数据集包含91个对象类型的照片,这些照片易于识别,并且在328k图像中总共有250万个带标签的实例。
8| MPII Human Pose Dataset

MPII Human Pose数据集用于评估关节式人体姿势估计。 该数据集包含约25K图像,其中包含超过4万名带注释的人体关节的人。 在这里,每张图片都是从YouTube视频中提取的,并带有未标注帧之前的an和an。 总体而言,数据集涵盖410种人类活动,并且每个图像都带有活动标签。
9| Open Images
此Open Images数据集是现有的最大的带有对象位置注释的数据集之一。 它由大约900万幅图像组成,这些图像带有图像级标签,对象边界框,对象分割蒙版和视觉关系。 数据集包含190万幅图像上600个对象类别的1600万个边界框。
10| The 20BN-something-something Dataset V2

20BN-Something-Something数据集是大量带有密集标签的视频剪辑的集合,这些视频剪辑向人们展示了人类对日常对象执行的预定义基本动作。 它是由大量的人群工作人员创建的,它允许ML模型对物理世界中发生的基本动作有更细致的了解。 视频总数包括220,847,其中168,913是训练集,24,777是验证集,27,157是测试集。
Model Play是面向全球开发者的AI模型资源平台,内置多样化AI模型,与钛灵AIX(一款集计算机视觉与智能语音交互两大核心功能为一体的人工智能硬件)结合,基于Google开源神经网络架构及算法,构建自主迁移学习功能,无需写代码,通过选择图片、定义模型和类别名称即可完成AI模型训练。