












过去几年,越来越多科技巨头推出了自己的 AutoML 服务,市场对于此类服务的关注度与认可度也一直在不断提升。数据科学家们一直面临着灵魂拷问:AutoML 会取代我们吗? 本文,四位数据科学家两两一组通过两个数据集与 AutoML 服务正面较量,最终证明:AutoML 取代工程师,缓缓吧!
目前存在哪些 AutoML 平台?
要了解 AutoML,我们先得谈谈机器学习项目的生命周期,具体涵盖数据清洁、特征选择 / 工程、模型选择、参数优化以及最终模型验证。尽管技术快速发展,传统数据科学项目当中仍然包含大量既耗时又重复的手动操作流程。
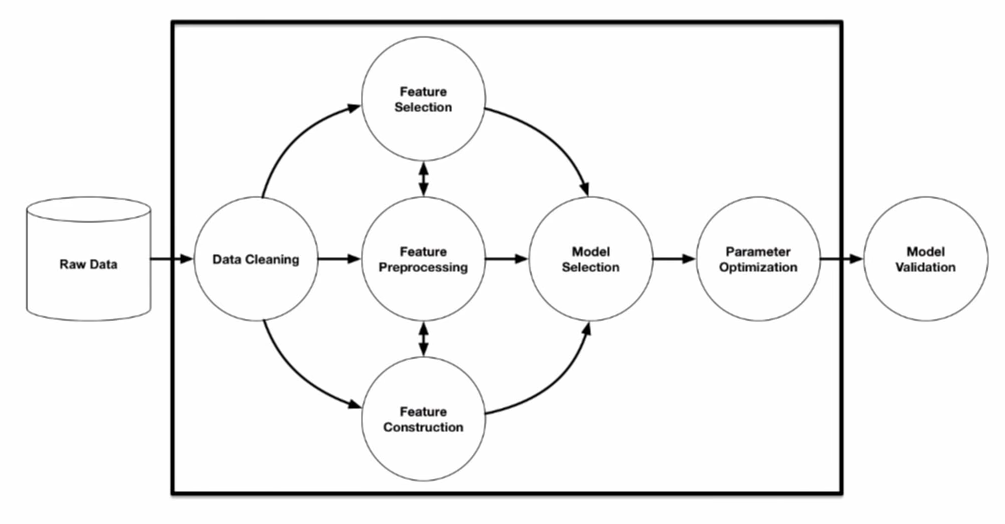
图片来源:R. Olson 等(2016 年),《在自动化数据科学场景下,对 TPOT(基于树形结构的流水线优化工具)的评估》
AutoML 能够自动完成从数据清洁到参数优化的整个流程,凭借着出色的时间与性能改进效果,为各类机器学习项目带来巨大价值。
1. Google Cloud AutoML
诞生于 2018 年的 Google Cloud AutoML 凭借其友好的用户界面与极高的性能表现,很快在市场上得以普及。下图所示,为 Google 与其他 AutoML 平台之间的性能比较(蓝色柱形为 Google AutoML)。
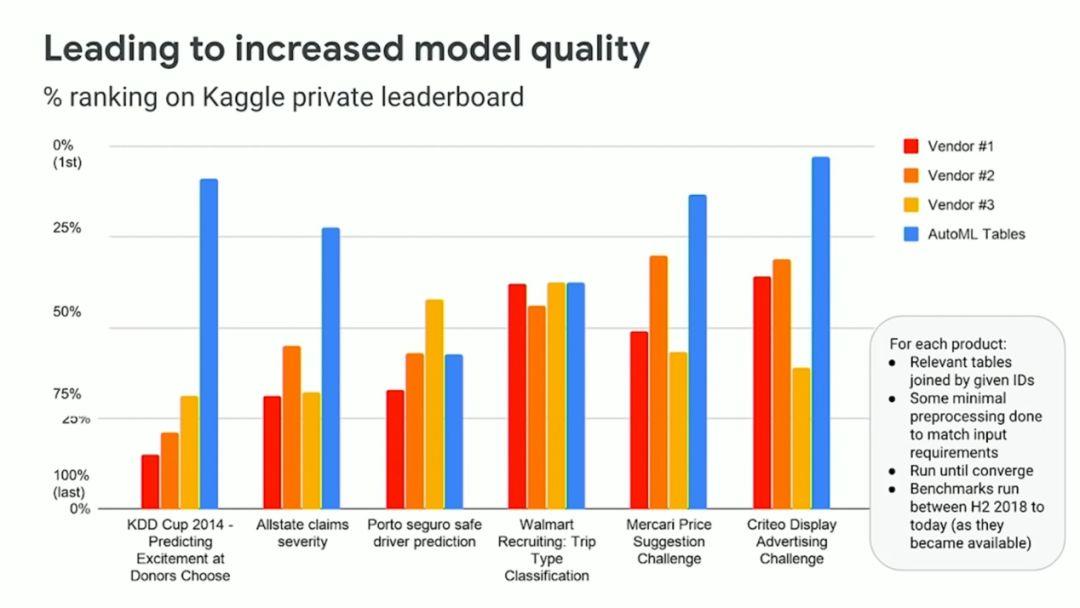
片来源:《在结构化数据上利用 AutoML 解决高价值业务问题》,2019 年 Cloud Next 大会
2. 微软 Azure AutoML
同样诞生于 2018 年的 Azure AutoML,为不熟悉编程知识的用户们带来高透明度模型选择流程。
3. H2o.ai
“H2O 已经成为大规模模型构建领域的重要驱动力。面对数十亿级别的参数规模,任何现成的标准开源技术都显得无能为力。” — H2o.ai
H2o 诞生于 2012 年,同时提供开源软件与商业 AutoML 服务(Driverless AI)两种选项。自面世以来,H2O 已经在金融服务与零售等行业得到广泛应用。
4. TPOT
TPOT(基于树形结构的流水线优化工具)由宾夕法尼亚大学开发完成,是一款可免费使用的 Python 软件包。该软件虽然完全免费,但功能方面不打一点折扣,而且在各类数据集上均拥有出色性能表现:Iris 数据集准确率约为 97%,MNIS 数字识别数据集准确率 98%,波士顿房屋价格预测为 10 MSE。
AutoML 对阵数据科学家
现在,我们已经了解了 AutoML 的基本定义及其可用选项。下面来看核心问题:这些平台会全面取代人类数据科学家吗?
为了找到令人信服的答案,我们将通过一场黑客马拉松,客观评估 AutoML 与人类之间的分析能力差异。
成本比较
根据 Indeed.com 网站的统计,美国数据科学家的平均年薪为 12 万 1585 美元。而 如果一家企业全年持续使用 AutoML(每周 40 小时,每年 52 周),则费用每年在 4160 美元到 41600 美元之间,具体视实际平台选项而定。
诚然,这样的直接比较并不合理,因为我们都知道数据科学家在模型操作之外还有其他工作需要处理。但在另一方面,这种快速简单的方法,仍能在一定程度上体现数据科学家与 AutoML 的成本差异。
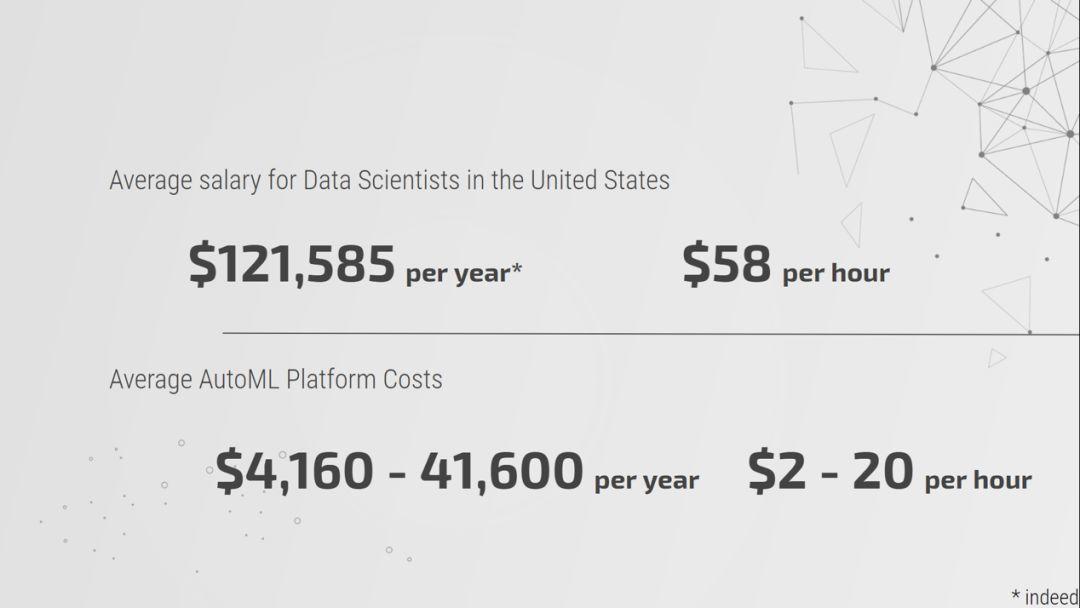
数据科学家与 AutoML 之间的成本比较
性能比较:黑客马拉松
下面,我们将组织一场涵盖两套数据集的黑客马拉松,进一步比较人类数据科学家与 AutoML 平台之间的性能差异。每套数据集,对应一支人类数据科学家小组以及多个 AutoML 平台。双方将同步进行数据处理、特征选择 / 工程、模型选择以及参数调整,并最终努力给出符合预定性能指标的最佳预测结果。

黑客马拉松数据集 1:快速分类

黑客马拉松数据集 2:ASHRAE(回归)
数据集 1:快速分类数据集
数据集概述
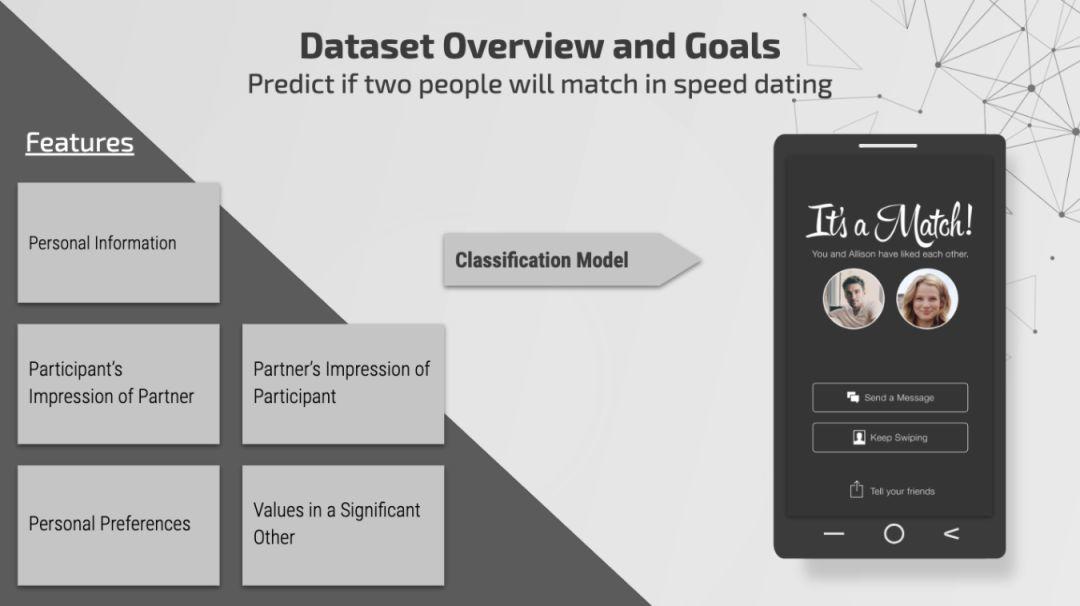
该数据集收集自参与实验性快速约会活动的人群。在这些活动中,参与者会填写一份调查表,其中包括个人信息以及他们理想中的伴侣所应具备的特征。例如,他们会以从 1 到 10 几个等级评论自己、自己从事的工作,以及希望伴侣表现出哪些特质。这套数据集的目标,在于根据个人喜好预测其能否找到适合自己的匹配对象。这是一个典型的分类问题,我们将“match”变量作为因变量。
数据科学家的数据预处理与特征工程
为了获得优于 AutoML 平台的结果,人类数据科学家需要对数据集进行特征设计、处理类失衡问题、处理缺失值,并对分类变更执行独热编码。由于数据收集自调查问卷,因此必须存在严重的值缺少问题——这是因为如果采访者不愿意回答某个问题,则可直接留空。这些缺失值只能通过适当估算均值、中位数或者众数等方式解决。由于数据在某些自变量之间具有共线性,因此某些变量会被删除。在所有标签当中,只有 29% 的二进制值为 1,其他部分的二进制值则为 0。为了解决这个问题,我们采用 SMOTE(合成少数过采样技术)。SMOTE 能够从少数类当中创建合成样本,而非简单复制数据。独热编码在谷歌平台上往往难于实现,这是因为该平台无法以有意义的方式对提取到的信息进行分组。
现在,我们将利用原始与特征工程处理后的数据,对 Azure 及谷歌的 AutoML 平台进行整体有效性分析。
数据科学家对阵 AutoML 平台

数据科学家: 我们尝试了多种不同模型,而后发现 XGBoost 与神经网络模型的性能最好。我们在其中主要关注 AUC ROC 评分,以便将模型结果与 AutoML 平台创建的模型进行比较。XGBoost 模型的 AUC ROC 得分为 0.77,神经网络模型的 AUC ROC 得分则为 0.74。
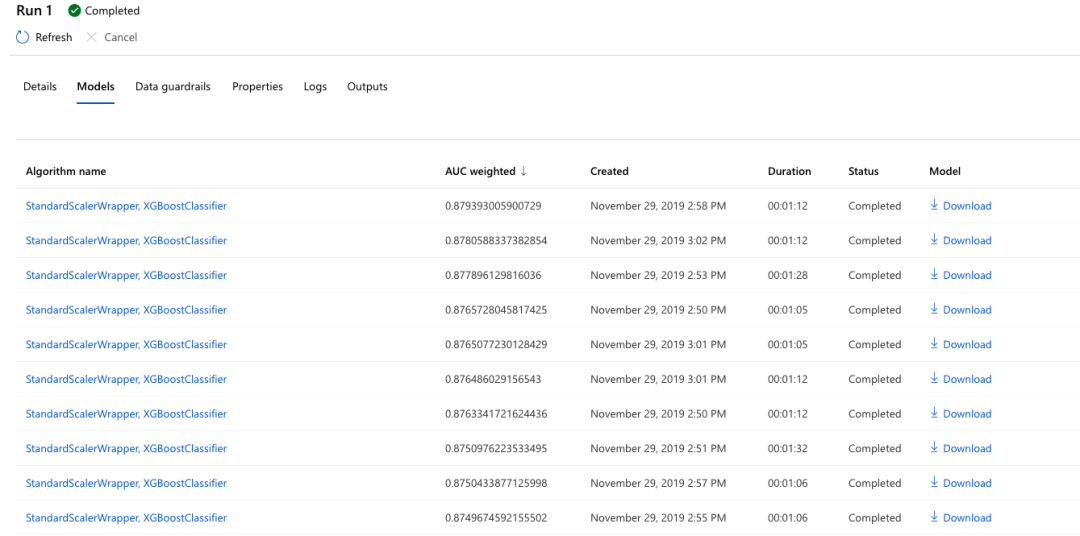
使用原始数据的 AutoML 平台: 同样采用 XGBoost,谷歌的性能水平要比 Azure 了一些。谷歌的 AUC ROC 得分为 0.881,Azure 则为 0.865。由于相关信息被划定为专有信息,因此我们无法得知谷歌平台到底选择了哪种模型。另一方面,Azure 则会准确告知其运行了多少个模型,每个模型的得分是多少,以及训练各个模型所花费的时间。
使用处理后数据的 AutoML 平台: 现在,我们希望测量经过特征工程处理的数据集又将在 AutoML 上拥有怎样的性能表现。我们注意到:谷歌的性能有所下降,Azure 性能则得以改善。如前所述,谷歌 AutoML 在处理独热编码方面存在问题,其设计思路在于自主进行特征工程。因此,以独热码变量的形式提供特征工程数据,反而会导致其整体性能下滑。在这轮测试中,Azure 的性能由 0.865 提升到了 0.885。
下图所示,为 Azure 在数据集上运行的各套模型:
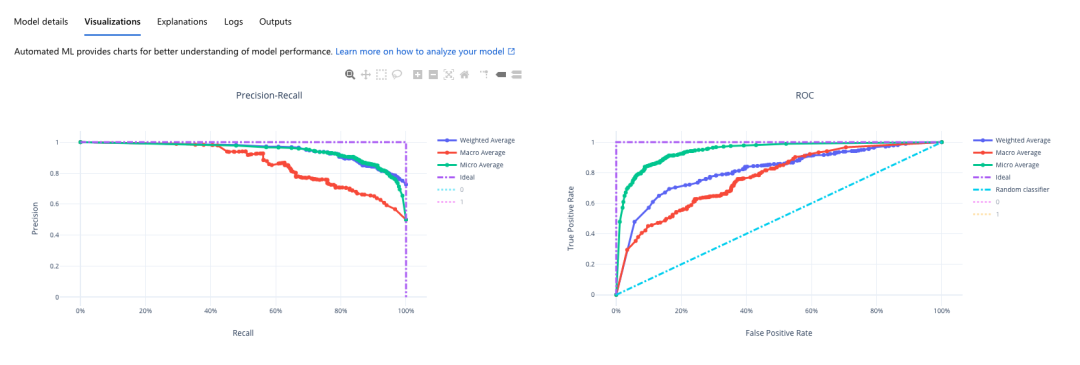
我们也可以看到谷歌与 Azure 平台上的 Precison-Recall 图、ROC 图、混淆矩阵以及特征重要度图:
快速(约会)分类数据集测试结论:
- 数据科学家能够向 AutoML 平台提供特征工程数据集,从而提高该平台的性能水平。
- Azure 在具体使用模型方面更为透明;谷歌平台则拒绝公开模型创建与选择信息。
- 谷歌无法很好地处理独热码变量。
数据集 2: ASHRAE
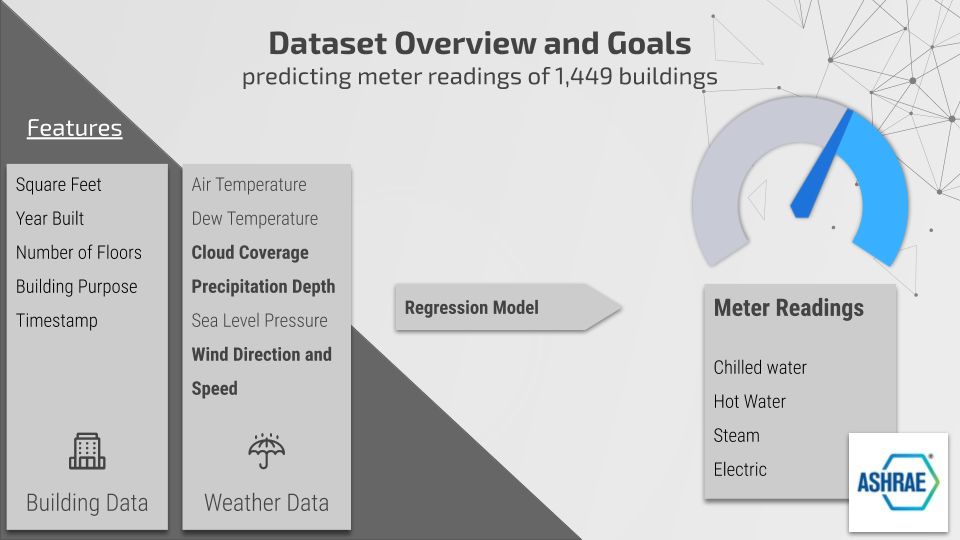
数据集概述
这套数据集来自 ASHRAE Energy Prediction Kaggle 竞赛,要求参赛者们开发出一套面向 1449 处建筑物内热水、冷水、蒸汽以及仪表计数的预测模型。这些数据源自建筑物的一系列相关元数据,包括占地面积、建成时间以及楼层总数;仪表类型与时间戳读数;带有时间戳的天气数据,包括气温、云量、降水量、风速、风向以及海平面压力等。天气数据由建筑物所在地附近的气象站提供。
数据科学家的数据预处理与特征工程
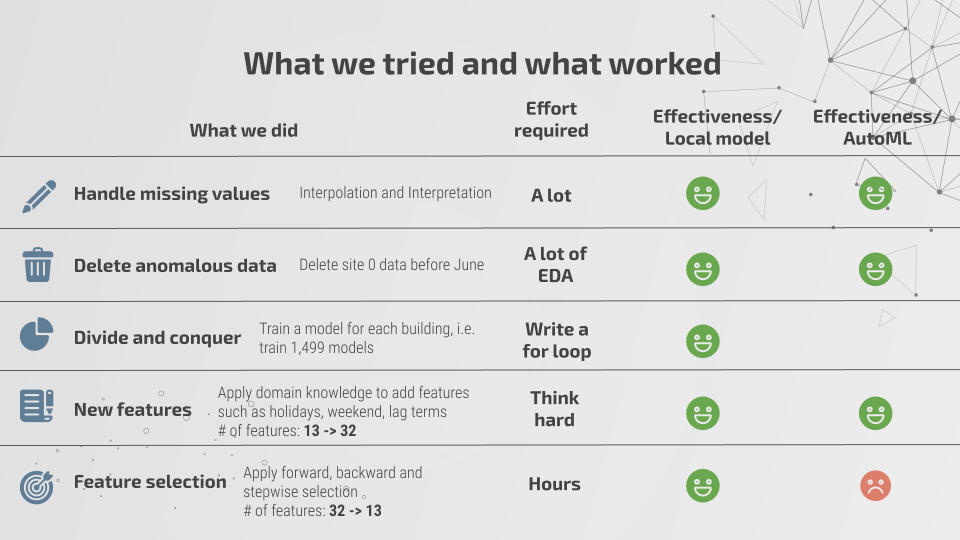
天气数据集当中同样存在着严重的值缺失问题,可以看到云量与降水量这两项特征分别存在 50% 与 35% 的缺失比例。部分气象站甚至压根不提供云量与降水量数据。为了克服这一障碍,数据科学家们尝试对气温、露水温度、风速以及海平面压力等特征进行整理,借此为缺失部分建立插值,并利用这些插值为云量与降水量建立预测模型。
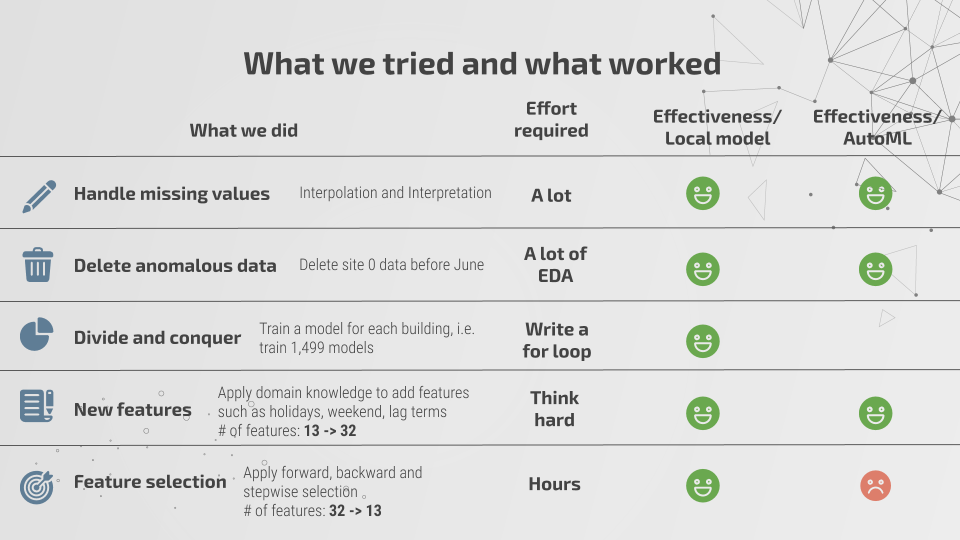
我们利用 10 倍交叉验证为各项特征选定插值方法,并将其应用于训练与测试数据。我们运行了一系列模型以预测云量与降水量,但始终未能找到可准确生成缺失值的理想模型。风向测量存在间隔,因此我们将每组数据重构为一组分类变量;由于存在明显的右偏分布,我们对风速结果进行了对数转换。此外,我们还构建起其他一些特征,包括假期和周末,同时引入了影响滞后因素。总而言之,我们额外构建起 19 项特征,再加上 13 项原始特征,总计 32 个变量。
最后,我们删除了一条由气象站收集到的异常天气数据,而后利用正向、反向与逐步回归找出最佳预报特征,因此预测中实际使用的变量为 13 个。
数据科学家对阵 AutoML 平台

数据科学家: 我们并没有为所有建筑物构建通用模型,而是为数据集内的每栋建筑物构建起对立的光梯度增强模型,确保训练与测试集内包含相同建筑物的信息。通过这种方法,我们获得了 0.773 RMSLE。
使用原始数据的 AutoML 平台: 经过一个小时的训练,谷歌云获得了 1.017 RMSLE;再训练三个小时,RMSLE 又进一步提升了 0.011。在这轮测试中,谷歌轻松超越 Azure,后者的 RMSLE 为 2.22。当然,这一比较并不算完全公平,因为我们要求 Azure 强制使用随机森林以返回 RMSLE 结果。
使用处理后数据的 AutoML 平台: 我们通过谷歌云运行处理后的数据。在经过四个小时的训练后,谷歌云的 RMSLE 为 1.7,这让我们相当惊讶。经过进一步调查,我们发现自己的特征选择方法限制了 AutoML 的性能,因为 AutoML 平台希望执行自己的特征选择。我们再次通过两套平台运行处理后的数据,且使用全部 32 个变量——而非之前提到的 13 个。这一次,两套平台的性能都得到了改善。经过一个小时的训练,谷歌云的 RMSLE 为 0.755,四小时训练后的 RMSLE 进一步达到 0.656——这远远超过了数据科学家们拿出的结果!经过一个小时的训练,Azure 的 RMSLE 为 3.826,四小时训练后的结果则为 3.653。
ASHRAE 数据集测试结论:
尽管 AutoML 是一款强大的预测工具,但仍无法像人类那样有效进行数据预处理。
将训练周期延长几个小时,可以大大提高 AutoML 平台的性能表现。
必须允许 AutoML 平台自行选择特征,否则可能会严重影响其性能表现。
将数据科学家在业务问题上的专业知识,同 AutoML 强大的特征选择、特征预处理、模型选择以及超参数调优功能相结合,将迸发出强大的能量,为我们带来宝贵的洞察见解与理想的预测结果。
结论
最后,我们用三个问题来结束此番讨论。
AutoML 能替代数据科学家吗?
答案是否定的。
虽然 AutoML 确实擅长构建模型,但仍然无法胜任大部分数据科学家所熟悉的工作内容。我们需要仰仗数据科学家来定义业务问题,需要他们运用自己的专业知识构建更多具有实际意义的特征。如今,AutoML 还只能处理有限几种问题类型,例如分类与回归问题;换言之,它们还无法建立推荐与排名模型。更重要的是,我们仍然需要由数据科学家从数据当中整理出可行洞察,这是单凭 AutoML 所无法做到的。
但是,AutoML 仍能帮助数据科学家为利益相关方创造出巨大的价值。因此,接下来要回答的问题是:我们何时该使用 AutoML?又该如何使用?
数据科学家该如何充分利用 AutoML 平台?
在这里,我们可以参考以下几个潜在用例。
性能比可解释性更重要时:
有时候,利益相关方可能只关注模型精度,而不要求模型必须拥有明确的可解释性。根据我们的实验,保证 AutoML 具有合理的特征工程发挥空间似乎有助于性能提升。但在示例当中,两套平台只在特征重要度方面体现出一点点可解释性。换句话说,如果只了解特征重要度就够了,那么 AutoML 可能会成为实现更高分析精度的理想选项。
生产速度非常重要时:
谷歌与 Azure 都提供将模型部署至生产环境中的便捷方法。例如,谷歌云允许用户通过几次点击快速实现批量与在线预测。它还允许用户通过 API 将模型部署至自有网站。这些功能,将使得数据科学家显著加快生产速度并减少实际工作量。
时间较为紧迫时:
数据科学家肩上的担子可不轻,所以时间对他们来说无比宝贵。在日常工作中,数据科学家需要没完没了地参加由产品经理、业务负责人、员工以及客户组织的会议,维护现有模型、进行数据收集 / 清洁、为下一次会议做准备等等等等。因此,AutoML 将成为节约时间的重要工具,几次点击再几块小钱,就让帮助我们训练出具备一定性能的模型。如此一来,大家就能专注于处理那些最具价值回报的关键任务(有时候,把 PPT 做得漂亮一点,可能要比把模型精度提升 1% 重要得多)。

















