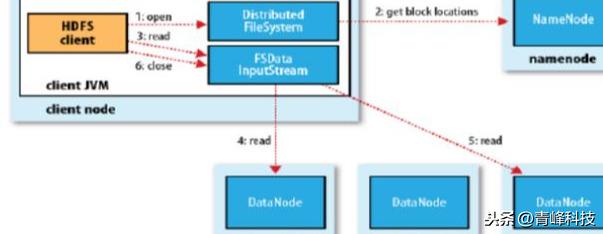
读数据
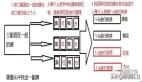
- 跟namenode通信查询元数据,找到文件块所在的datanode服务器
- 挑选一台datanode(就近原则,然后随机)服务器,请求建立socket流
- datanode开始发送数据(从磁盘里面读取数据放入流,以packet为单位来做校验)
- 客户端以packet为单位接收,现在本地缓存,然后写入目标文件
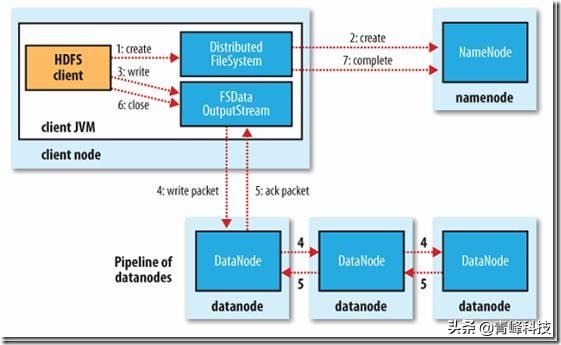
写数据
- 根namenode通信请求上传文件,namenode检查目标文件是否已存在,父目录是否存在
- namenode返回是否可以上传
- client请求第一个 block该传输到哪些datanode服务器上
- namenode返回3个datanode服务器ABC
- client请求3台dn中的一台A上传数据(本质上是一个RPC调用,建立pipeline),A收到请求会继续调用B,然后B调用C,将真个pipeline建立完成,逐级返回客户端
- client开始往A上传第一个block(先从磁盘读取数据放到一个本地内存缓存),以packet为单位,A收到一个packet就会传给B,B传给C;A每传一个packet会放入一个应答队列等待应答
- 当一个block传输完成之后,client再次请求namenode上传第二个block的服务器。
网络故障,脏数据如何解决?
DataNode 失效等问题,这些问题 HDFS 在设计的时候都早已考虑到了。下面来介绍一下数据损坏处理流程:
- 当 DataNode 读取 block 的时候,它会计算 checksum。
- 如果计算后的 checksum,与 block 创建时值不一样,说明该 block 已经损坏。
- Client 读取其它 DataNode上的 block。
- NameNode 标记该块已经损坏,然后复制 block 达到预期设置的文件备份数 。
- DataNode 在其文件创建后验证其 checksum。
读写过程,数据完整性如何保持?
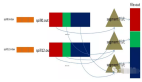
通过校验和。因为每个chunk中都有一个校验位,一个个chunk构成packet,一个个packet最终形成block,故可在block上求校验和。
HDFS 的client端即实现了对 HDFS 文件内容的校验和 (checksum) 检查。当客户端创建一个新的HDFS文件时候,分块后会计算这个文件每个数据块的校验和,此校验和会以一个隐藏文件形式保存在同一个 HDFS 命名空间下。当client端从HDFS中读取文件内容后,它会检查分块时候计算出的校验和(隐藏文件里)和读取到的文件块中校验和是否匹配,如果不匹配,客户端可以选择从其他 Datanode 获取该数据块的副本。
HDFS中文件块目录结构具体格式如下:
- ${dfs.datanode.data.dir}/
- ├── current
- │ ├── BP-526805057-127.0.0.1-1411980876842
- │ │ └── current
- │ │ ├── VERSION
- │ │ ├── finalized
- │ │ │ ├── blk_1073741825
- │ │ │ ├── blk_1073741825_1001.meta
- │ │ │ ├── blk_1073741826
- │ │ │ └── blk_1073741826_1002.meta
- │ │ └── rbw
- │ └── VERSION
- └── in_use.lock
in_use.lock表示DataNode正在对文件夹进行操作
rbw是“replica being written”的意思,该目录用于存储用户当前正在写入的数据。
Block元数据文件(*.meta)由一个包含版本、类型信息的头文件和一系列校验值组成。校验和也正是存在其中。