













大家好,我是鸭血粉丝(大家会亲切的喊我 「阿粉」),是一位喜欢吃鸭血粉丝的程序员,之前给大家总结了线上 OOM 的情况,相信大家也能从中学到一些东西,身为一名有追求的程序员,阿粉我的理解是光会吃老本是不行的,所以我一直也在学习,今天大家就跟我一起来了解一下 Redis 的 SDS 吧(不是 SOS 哦~)。
01、SDS 数据结构
Redis 底层是基于 C 语言来开发的,但是它没有采用 C 语言传统的字符串表示方式,而是自定义了一种叫做 SDS(Sample Dynamic String,简单动态字符串)的数据结构来表示字符串。传统的 C 语言的字符串是采用空字符(\0)作为结尾的字符数组,SDS 的数据结构稍微复杂一点,整个结构包含三个部分,是 Redis 的基础。(阿粉猜测这里就是传说中的青出于蓝而胜于蓝)。
1.1、数据结构
在源码 sds.h/sdshdr 结构体中定义了 SDS 的数据结构,包括三个部分,free,len,buf[],依次含义如下
- buf[]:字节数组,用于存放实际的字符串;
- len:记录 buf 数组中已经使用的字节数量,等同于 SDS 所保存的字符串的长度;
- free:记录 buf 数组中未使用的字节的数量。
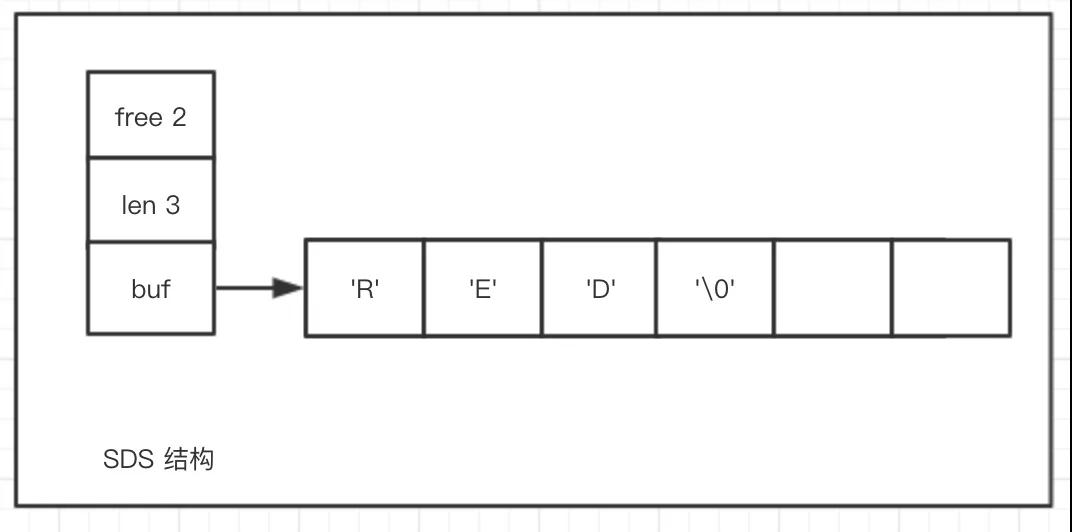
说明
上图中的 SDS 表示一个存放了 'RED' 字符串,已经使用的长度为 3,未使用的长度为 2(这里用空白格表示未使用),其中的 '\0' 表示的是字符串的结束,不计算在 SDS 的 len 中,并且由 SDS 底层函数自动添加,对使用者来说是透明。这里统一采用空字符(\0)结尾是为了复用 C 语言的相关函数。这个相信大家也很能理解,毕竟有祖宗可以靠,没必要全靠自己那么辛苦~。
02、为什么采用 SDS
2.1、SDS 与 C语言字符串的区别
在说明 Redis 为什么要自定义 SDS 之前,阿粉觉得我们应该先看一下 SDS 与传统的 C 语言的字符串有什么区别,知道了具体的区别我们才能知道这样实现的原因是什么。
2.1.1、O(1) 获取字符串的长度
传统的 C 语言字符串如果要获取字符串的长度,则需要遍历整个字符串,直到遇到 '\0' 字符,才知道整个字符串的长度是多少,操作复杂度是 O(n) 的。但是在 SDS 中,由于我们记录了字符串的长度,所以在获取字符串长度的时候是可以直接获取的,整个操作为 O(1)。
如上面的示例,我们可以直接获取字符串的长度是 3,而不需要遍历,另外字符串 Key 在 Redis 的底层实现就是采用 SDS 的,所以这个特性就保证了我们在计算 Key 的长度的时候不会出现任何瓶颈,对系统的性能不会有任何影响。
2.1.2、动态扩容
由于 SDS 中记录了未使用的空间大小,所以如果出现对已有字符串进行修改或者赋值时,SDS 底层函数会自动检测剩余空间是否能满足此次修改,如果 free 空间足够则直接修改;如果 free 空间不够则会先进行动态扩容达到能满足的空间大小,然后再执行修改动作。整个扩容的动作是 SDS 底层函数自动完成,对使用者无感。
而对于传统的 C 语言字符串,如果在修改前忘记手动扩容则会导致字符串后面的数据被覆盖。这里阿粉就不得不说一句了,为了方便大众程序员,另一些骨灰级程序员(嗯,仿佛看到了未来的阿粉)也是操碎了心啊~
2.1.3、减少内存分配次数
在传统的 C 语言的字符串,我们每次对字符串的修改都会涉及到字符串内存的重新分配,不管是增加还是减少字符串的长度。这种情况下,如果我们多次对字符串的长度进行调整的时候就会导致多次的内存重新分配。
而在 SDS 中我们在对一个 SDS 初始化的时候会根据实际 buf[] 字符串的长度进行预先空间分配,并且标记为 free。这种方式叫做空间预分配,在很大程度上可以减少增加字符串长度导致内存重新分配的情况。free 的空间分配的策略是根据 buf[] 大小来决定的,如果 buf[] 大小小于 1MB,则 len 多大 free 就多大;如果 buf[] 大小大于 1MB,则 free 固定设置为 1MB。
上面说的是SDS 字符串的长度增加,另外如果 SDS 的字符串长度减少,那么 SDS 会将减少的长度存放到 free 中,而不是直接回收,这样可以方便下次如果再次使用,减少内存重新分配。这种策略叫做惰性空间释放。
同样的上面两种操作对使用者是完全无感的,阿粉觉得这种方案还是很合理的,不知道“元芳”你怎么看?
2.1.4、二进制安全
我们都知道 Redis 是可以存储各种类型数据的,不仅是字符串也可以存储图片,视频等二进制数据流。这是由于 Redis 不依赖一 '\0' 空字符作为结束字符。C 语言之所以不支持就是因为二进制流中会携带 '\0' 字符,导致无法知道字符串真实的结束位置。这就带来了另一个 Redis 特性,就是二进制的安全性。
2.2 为什么使用 SDS
通过上面阿粉提到的内容我们知道了 SDS 比传统的 C 语言的字符串有很多优势,也正是这些必不可少的优势才促成了 SDS的存在。Redis 是一个高性能的内存数据库,所以在性能方面要求特别高,这种设计方式虽然浪费了一定的空间,但是为了达到性能的要求也是值得的。有空间换时间的这种方式,在软件设计的领域还是很多的。
2.3 SDS 常用 API
上面阿粉说的都是一些原理,下面从源码上给大家展示一下。在 2.1 中提到有获取长度 len 和释放空间 free 的动作,那么对应在 SDS 底层必定会有提供支持的 API,下面我们通过源码来看几个常用的 API。
1.源码 sds.c 文件中 sdsfree 函数定义如下:
- /* Free an sds string. No operation is performed if 's' is NULL. */
- void sdsfree(sds s) {
- if (s == NULL) return;
- s_free((char*)s-sdsHdrSize(s[-1]));
- }
2.在源码 sds.h 文件中 sdslen 函数定义如下:
- static inline size_t sdslen(const sds s) {
- unsigned char flags = s[-1];
- switch(flags&SDS_TYPE_MASK) {
- case SDS_TYPE_5:
- return SDS_TYPE_5_LEN(flags);
- case SDS_TYPE_8:
- return SDS_HDR(8,s)->len;
- case SDS_TYPE_16:
- return SDS_HDR(16,s)->len;
- case SDS_TYPE_32:
- return SDS_HDR(32,s)->len;
- case SDS_TYPE_64:
- return SDS_HDR(64,s)->len;
- }
- return 0;
- }
上面两个是 SDS 底层对应的 sdsfree 和 sdslen 函数,用于释放 SDS 空间和获取 SDS 的长度。
3.在源码 sds.c 文件中创建 sds 的函数定义如下:
- /* Create an empty (zero length) sds string. Even in this case the string
- * always has an implicit null term. */
- sds sdsempty(void) {
- return sdsnewlen("",0);
- }
- /* Create a new sds string starting from a null terminated C string. */
- sds sdsnew(const char *init) {
- size_t initlen = (init == NULL) ? 0 : strlen(init);
- return sdsnewlen(init, initlen);
- }
上面两个是 SDS 底层对应的 sdsempty 和 sdsnew 函数,顾名思义就是创建空的 SDS 和创建一个新的 SDS 字符串。
03、总结
这篇文章阿粉跟大家介绍了一下 Redis 的 SDS 和 SDS 底层的组成结构,并且与 C 语言传统字符串进行的详细的对比,阐述了 SDS 出现解决了哪些问题,最后带大家从源码中简单的看了几个底层的函数实现。
在走向骨灰级程序员的道路上,阿粉我从不懈怠,充满斗志,那么你呢?是否跟阿粉一样,对未来充满期待!
今天是 2020 年的第一个周末,所以你想怎么过能?欢迎加入到我们 Java 极客技术的知识星球中进行留言,我们共同进步成长。
04、参考文档
https://github.com/antirez/redis
https://redis.io/
《Redis 设计与实现(第二版)》——黄建宏



















