俗话说,计算机编程的任何问题,都可以通过增加一个抽象层来解决,这句话用在我身上就太合适了。
我是缓存(Cache),今天我给大家聊聊我这个抽象层是怎么工作的。
提到我的名字,你可能立刻会想到到Redis, 因为它实在是太普及了,但是如果你只想到Redis,那视野未必有点狭窄,Redis仅仅是我在应用层小试牛刀而已。
Wikipedia上说我是一种用来保存数据的硬件或者软件,这样以后的访问请求就可以更快地返回。
这个定义还真是挺抽象的,抽象的东西让人感觉不好理解,我得给大家举几个例子。
为了突出我的位置, 在下面的图片中,缓存都用蓝色来表示。
首先来看大家日常使用很多,但是又不太在意的浏览器缓存。
浏览器缓存
浏览器面对的问题是网络访问的速度远远低于本地访问的速度,每次都访问网络开销太大。
于是它就请我增加了一个中间层:开辟“缓存”区域,缓存JS, HTML, CSS,图片等各种文件。
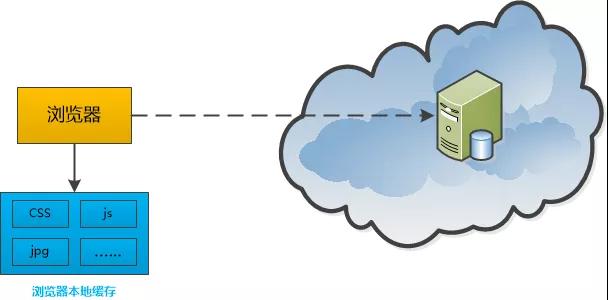
当然,浏览器这家伙也不能乱来,得遵循一定的规则来判断什么时候用缓存中的文件,什么时候不辞辛苦地去访问服务器的新文件。
这其中的关键点就是HTTP协议:
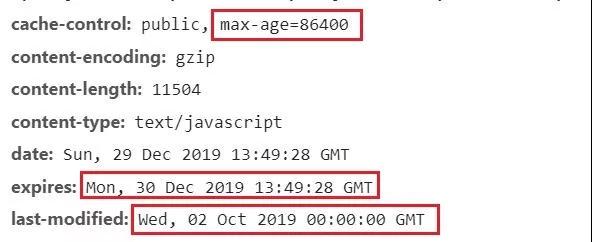
在服务器发给浏览器的响应中,有expires, max-age, last-modified, Etag等Header, 粗略来说,expires 和 max-age 定义了一个资源的过期时间, last-modified和Etag用来检查一个资源在服务器端有没有变化。
对于它们的含义和详细用法,网上资料多如牛毛,我这里就不再展开了。
我觉得有趣的事情是这些:
1. 当你在地址栏中输入网址,按回车以后 浏览器会使用Expires,max-age来查看本地缓存的内容是否失效,如果没有,就直接使用
2. 当你按F5或者按浏览器刷新按钮的时候 浏览器不再考虑Expires,max-age, 而是把Last-Modified / ETag 发到服务器去,问问服务器,这个文件有更新没有?如果没有,那就用本地缓存的文件,如果有更新,用服务器端最新的。
3. 当你用Ctrl + F5强制刷新的时候 不使用任何缓存,向服务器发出全新请求。
CDN
说起CDN,可能很多人都意识不到它的存在,这也难怪,它对于大家来说几乎是透明的,魔法发生在DNS的域名解析的过程。
但是CDN也是不折不扣的缓存。 由于网络情况复杂,如果客户端离服务器比较远,网速慢,体验会很差;海量的用户给后端服务器带来巨大压力,所以CDN就采用了就近访问的方案:
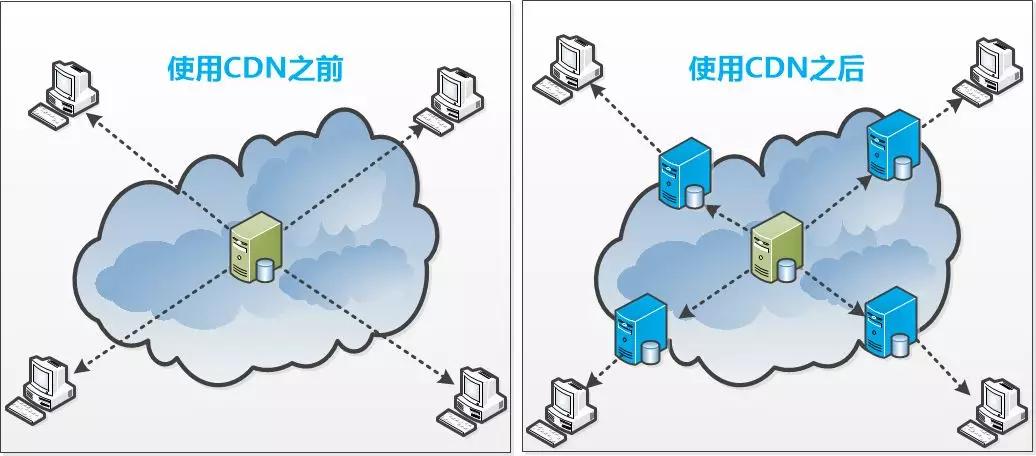
把后端服务器的数据数据复制多份,挪到离客户端比较近的“边缘”服务器中,就近访问,不但减少了访问的时间,还大大降低了 “中央”服务器的负载。
浏览器缓存和CDN是配合使用的, 浏览器的本地缓存失效以后,就需要向后端服务器来获取了,但是如果一个系统有CDN,那浏览器还可以就近访问CDN。
Linux Page Cache
在操作系统的世界中,时间是按纳秒,微秒为单位的,虽然内存和硬盘都在同一台机器中,没有网络开销,但是硬盘实在是太慢,比内存慢几万倍, 内存等不及。
所以Linux也增加了一个抽象层:Page cache , 把慢如蜗牛的硬盘的文件缓存在其中。
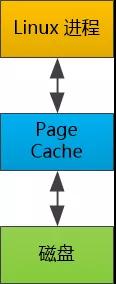
有了这个抽象层, 在Linux当中,几乎所有的文件读写操作都依赖Page Cache,在向硬盘写入文件的时候,并不是直接把文件内容写入硬盘以后才返回的,而是写入到内核的Page Cache就直接返回了。
这个Page Cache会被标记为“Dirty”,随后由内核线程写入硬盘(也可以通过手工用sync命令写入)。
各位看官可以想想,如果Page cache 的数据还没有写入硬盘,就断电了,会发生什么事情? 该怎么处理?
当从硬盘读取文件时,也不是直接把数据从硬盘复制到用户态的内存,而是先复制到内核的Page Cache ,然后再复制到用户态的内存。
正是由于这样复制来复制去,在多个进程中间进行数据传输很麻烦,例如(一个进程读取文件,然后通过Socket发送) ,所以后来就出现了零复制技术。
应用程序缓存
终于来到了大家熟悉的应用程序缓存, 这个就不用我多说了, 因为数据库访问速度慢,无法应对大量的并发访问,所以增加一个缓存中间层,把热点数据从数据库中取出,放到可以快速访问的内存当中。

大名鼎鼎的Redis干的就是这个活。
可是应用程序的缓存也是个双刃剑,提升了访问的效率, 但是带来了很多复杂性:
1. 代码变复杂
2. 需要处理缓存和数据库之间的数据一致性的问题
3. 处理缓存的穿透,雪崩等问题
4. 应用程序缓存现在已经变成了分布式的集群形式,数据的管理越来越麻烦。
CPU缓存
前面刚说到内存比硬盘快几万倍, 可是在CPU面前,内存也只能屈居下风,CPU比内存快100多倍,数据和指令必须从内存加载到CPU才能执行, 这次轮到CPU等不及了。
那就在CPU内增加缓存中间层,不过这次必须用硬件来实现。
CPU的缓存包括L1,L2, L3这三级Cache,把最热点的数据和指令放入到其中。
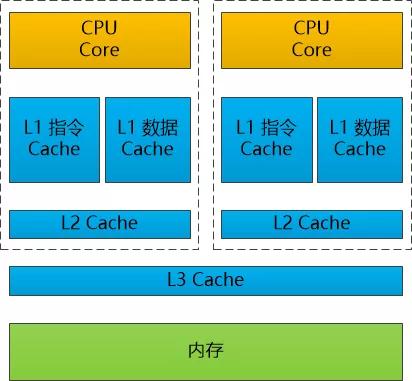
我猜CPU Cache可能是最“底层”的Cache了。
在L1 Cache 最靠近CPU,速度最快,可以分为指令Cache (CPU要执行的指令)和数据Cache(指令要操作的数据)。
CPU Cache 和上面提到的各种Cache比起来,小得可怜,也就是几百K到几M。 所以这些Cache要想发挥真正的作用,必须得依赖上帝的规矩局部性原理:
(1) 时间局部性:如果程序中的某条指令一旦执行,则不久之后该指令可能再次被执行;如果某数据被访问,则不久之后该数据可能再次被访问。
(2) 空间局部性:指一旦程序访问了某个存储单元,则不久之后。其附近的存储单元也将被访问。
最后总结一下放置在我这里的数据的特点,大家可以感受下:
(1)对数据的读操作远大于写操作
(2)数据可能是之前的计算结果(计算过程比较耗时)
(3)数据是某个(速度较慢的)数据源的数据备份。
(4)数据访问遵循上帝的规矩“局部性原理”
如果你在工作中也遇到了问题,不妨考虑一下,看看能不能用我来解决问题:增加一个中间层, 用空间来换取时间。

【本文为51CTO专栏作者“刘欣”的原创稿件,转载请通过作者微信公众号coderising获取授权】