












本文经AI新媒体量子位(公众号ID:QbitAI)授权转载,转载请联系出处。
2019年,自然语言处理(NLP)都取得了哪些突破?
提到NLP,BERT可以说是家喻户晓。
在情感分析、问答、句子相似度等多个 NLP 任务上都取得了优异的成绩。
而且,无论是在类似于Kaggle这样的竞赛,或者媒体报道中,也总能看到它的身影。
它发表于2018年末,自那之后的一年,NLP和NLU(自然语言理解)领域有了较大的发展。
那么,以BERT的发布作为时间节点,本文便梳理了一下在此之前和之后,NLP领域的重要项目和模型。
BERT之前的一些主要 NLP 项目时间表
在提出BERT模型之前,NLP领域中的主要项目按时间排序,如下图所示:

Word2Vec模型发布于2013年1月,至今也是非常流行。
在任何NLP任务中,研究人员可能尝试的第一个模型就是它。
https://arxiv.org/abs/1301.3781
FastText和GloVe分别于2016年7月和2014年1月提出。
FastText是一个开源的、免费的、轻量级的库,它允许用户学习文本表示和文本分类器。
https://fasttext.cc/
GloVe是一种无监督的学习算法,用于获取单词的向量表示。
https://nlp.stanford.edu/projects/glove/
Transformer于2017年6月提出,是一种基于 encoder-decoder 结构的模型。
在机器翻译任务上的表现超过了 RNN,CNN,只用 encoder-decoder 和 attention 机制就能达到很好的效果,最大的优点是可以高效地并行化。
https://ai.googleblog.com/2017/08/transformer-novel-neural-network.html
ELMo于2018年2月提出,利用预训练好的双向语言模型,然后根据具体输入从该语言模型中可以得到上下文依赖的当前词表示,再当成特征加入到具体的NLP有监督模型里。
https://allennlp.org/elmo
还有一个叫Ulmfit,是面向NLP任务的迁移学习模型,只需使用极少量的标记数据,文本分类精度就能和数千倍的标记数据训练量达到同等水平。
https://arxiv.org/abs/1801.06146
值得注意的是,ELMo和Ulmfit出现在BERT之前,没有采用基于Transformer的结构。
BERT
BERT模型于2018年10月提出。
全称是Bidirectional Encoder Representation from Transformers,即双向Transformer的Encoder(因为decoder不能获取要预测的信息)。

△论文地址:https://arxiv.org/abs/1810.04805
模型的主要创新点都在pre-train方法上,即用了Masked LM和Next Sentence Prediction两种方法分别捕捉词语和句子级别的表示。
谷歌甚至开始使用BERT来改善搜索结果。
奉上一份较为详细的BERT模型教程:
http://jalammar.github.io/illustrated-bert/
预训练权重相关内容可以从官方 Github repo 下载:
https://github.com/google-research/bert
Bert 也可以作为 Tensorflow hub 模块:
https://tfhub.dev/google/collections/bert/1
文末还会奉上各种非常实用的库。
BERT之后的一些主要 NLP 项目时间表
在谷歌提出BERT之后,NLP领域也相继出了其他较为突出的工作项目。

Transformer-XL
Transormer-XL是Transformer的升级版,在速度方面比Transformer快1800多倍。
这里的XL,指的是extra long,意思是超长,表示Transformer-XL在语言建模中长距离依赖问题上有非常好的表现。同时,也暗示着它就是为长距离依赖问题而生。
长距离依赖问题,是当前文本处理模型面临的难题,也是RNN失败的地方。
相比之下,Transformer-XL学习的依赖要比RNN长80%。比Vanilla Transformers快450%。
在短序列和长序列上,都有很好的性能表现。
https://arxiv.org/abs/1901.02860
GPT-2
GPT-2可以说是在BERT之后,媒体报道最为关注的一个NLP模型。
这是OpenAI发布的一个“逆天”的语言AI,整个模型包含15亿个参数。
无需针对性训练就能横扫各种特定领域的语言建模任务,还具备阅读理解、问答、生成文章摘要、翻译等等能力。
而且,OpenAI最初还担心项目过于强大,而选择没有开源。但在10个月之后,还是决定将其公布。
https://cdn.openai.com/better-language-models/language_models_are_unsupervised_multitask_learners.pdf
ERNIE
ERNIE是基于百度自己的深度学习框架飞桨(PaddlePaddle)搭建的,可以同时利用词汇、句法和知识信息。
实验结果显示,在不同的知识驱动任务取得了显著的改进,同时在其它常见任务上与现有的BERT模型具有可比性。
当前,ERNIE 2.0版本在GLUE排行榜上排名第一。
https://github.com/PaddlePaddle/ERNIE
XLNET
XLNet 是一个类似BERT的模型,是一种通用的自回归预训练方法。
它不使用传统 AR 模型中固定的前向或后向因式分解顺序,而是最大化所有可能因式分解顺序的期望对数似然。
其次,作为一个泛化 AR 语言模型,XLNet不依赖残缺数据。
此外,XLNet还改进了预训练的架构设计。
https://arxiv.org/abs/1906.08237
RoBERTa
RoBERTa由Facebook提出。
它在模型层面没有改变谷歌的BERT,改变的只是预训练的方法。
在模型规模、算力和数据上,与BERT相比主要有以下几点改进:
更大的模型参数量:模型使用 1024 块 V100 GPU 训练了 1 天的时间。
更大bacth size:RoBERTa在训练过程中使用了更大的bacth size,尝试过从 256 到 8000 不等的bacth size。
更多的训练数据:包括CC-NEWS 等在内的160GB纯文本。
https://arxiv.org/abs/1907.11692
Salesforce CTRL
CTRL全名是Conditional Transformer Language,包含16亿个参数。
它具有强大且可控的人工文本生成功能,可以预测哪个训练数据子集对生成的文本序列影响最大。
通过识别模型中最有影响力的训练数据来源,为分析大量生成的文本提供了一种潜在的方法。
CTRL还可以通过微调特定任务或转移模型已学习的表示形式来改进其他NLP应用程序。
https://blog.einstein.ai/introducing-a-conditional-transformer-language-model-for-controllable-generation/
ALBERT
ALBERT是谷歌发布的轻量级BERT模型。
比BERT模型参数小18倍,性能还超越了它,在SQuAD和RACE测试上创造了新的SOTA。
前不久,谷歌还对此进行了升级,发布了ALBERT 2和中文版本。
在这个版本中,“no dropout”、“additional training data”、“long training time”策略将应用到所有的模型。
从性能的比较来说,对于ALBERT-base、ALBERT-large和ALBERT-xlarge,v2版要比v1版好得多。
说明采用上述三个策略的重要性。
https://arxiv.org/abs/1909.11942
性能评测基准
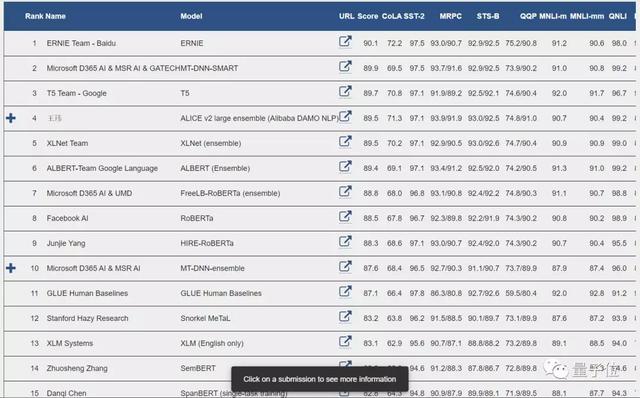
评估这些语言模型的方法之一是Glue Benchmark。
它包括评估模型的各种NLP任务,如分类、问答等。
在Glue Benchmark刚刚发布的时候,BERT模型的性能位居榜首。
但截至2020年1月2日,在仅仅1年时间内,BERT已经排名到了19位。
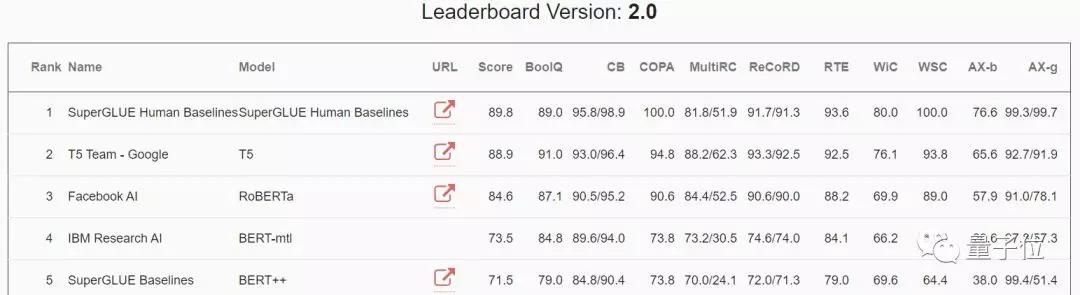
现在还有一个 SuperGlue 基准测试,它包含了更难理解的语言任务。
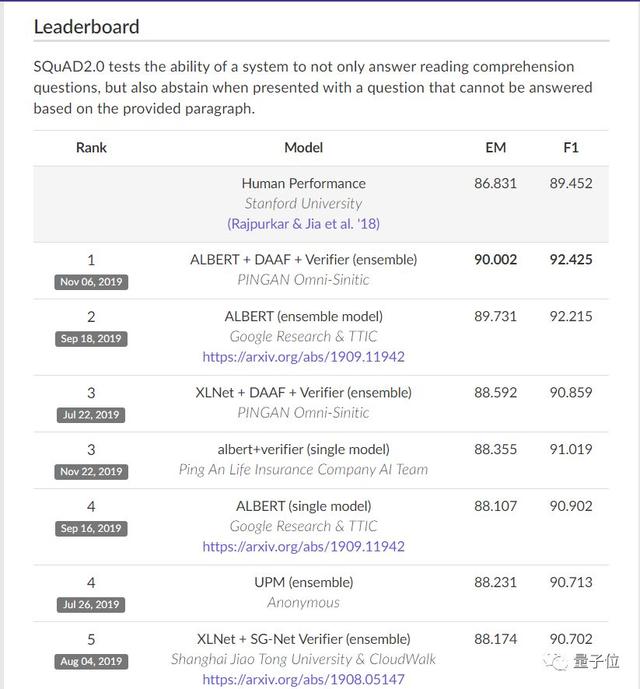
对于评估问题回答系统,SQuAD是较为常用的。
BERT和基于transformer模型在此处的性能是较好的。
其它与BERT相关项目
DistilBERT
DistilBERT是HuggingFace发布的小型NLP transformer模型,与BERT的架构类似,不过它仅使用了 6600 万参数,但在 GLUE 基准上实现了BERT 95% 的性能。
https://arxiv.org/abs/1910.01108
Megatron-LM
Megatron-LM是英伟达发布的NLP模型。
英伟达用自己的硬件与并行计算软件相结合,当时创下了三项纪录:
训练速度只需53分钟;
推理速度只需2.2ms;
包含83亿参数。
https://github.com/NVIDIA/Megatron-LM
BioBERT
BioBERT是用于生物医学文本挖掘的预训练生物医学语言表示模型。
在生物医学语料库上进行预培训时,它在各种生物医学文本挖掘任务上的表现,在很大程度上超过了BERT和之前的先进模型。
https://github.com/dmis-lab/biobert
CamemBERT
CamemBERT是一种基于RoBERTa 结构的法语语言模型。
https://camembert-model.fr/
NLP库
下面是作者认为需要了解的一些NLP库。
Spacy
Spacy 是一个流行的、快速的NLP程序库,可以处理各种自然语言处理任务,如标记、词性等。它还提供了预先训练的NER等模型。
https://spacy.io/
HuggingFace Transformers
它是首批提供 BERT Pytorch实现的库之一,最初被称为“ Pytorch-pretrained-BERT”。
后来,他们增加了更多的模型,如GPT-2,XLNET等。
在不到一年的时间里,它已经成为最流行的 NLP 库之一,并且使得BERT和其他模型的使用变得更加容易。
https://github.com/huggingface/transformers
AllenNLP
AllenNLP是来自艾伦人工智能研究所(Allen Institute of AI)的NLP库,基于PyTorch。
https://allennlp.org/
Flair
Flair也是一个带有 NER、 POS 等模型的 NLP 库,还支持 BERT、 ELMO、 XLNET 等嵌入。
https://github.com/flairNLP/flair
GluonNLP
GluonNLP是Apache MXNet 上的NLP工具包,是最早包含预先训练的BERT嵌入式的库之一。
https://gluon-nlp.mxnet.io/
那么,在2020年,NLP又会怎样的突破呢?
传送门
https://towardsdatascience.com/2019-year-of-bert-and-transformer-f200b53d05b9




















