一直以来Python性能是遭人诟病的问题之一,抱怨执行慢,没法用。虽然再性能上语言的差异确实存在着明显差异,但是我认为一个非常流行的语言,运行的快慢不会成为阻扰人们使用的因素。如果是的话,可能是由于编写的程序有问题,需要优化。本文虫虫就给大家介绍一下如何调试Python应用的性能,以及怎么对其进行优化。
Python性能调试
要进行Python性能,前提条件是要找出程序中的性能瓶颈。找出程序中影响程序性能的代码。有经验的开发者一般都能很容易能找出程序的瓶颈,但对于普通码农找出系统的问题代码则很难,为了能快捷有效的发现程序的性能瓶颈就需要进行性能调试,此处我们以一个实际例子进行介绍,以下程序是计算e的x(1..n)次的幂,其代码如下:
- # performance.py
- from decimal import *
- def exp(x):
- getcontext().prec += 2
- i, lasts, s, fact, num = 0, 0, 1, 1, 1
- while s != lasts:
- lasts = s
- i += 1
- fact *= i
- num *= x
- s += num / fact
- getcontext().prec -= 2
- return +s
- print(exp(Decimal(150)))
- print(exp(Decimal(400)))
- print(exp(Decimal(3000)))
最简单的调试
最简单且实用的调试性能调试的方法是使用Linux的time命令,time可以计算程序执行的时间:
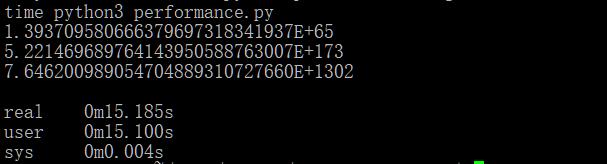
- time python3 performance.py
- 1.393709580666379697318341937E+65
- 5.221469689764143950588763007E+173
- 7.646200989054704889310727660E+1302
- real 0m15.185s
- user 0m15.100s
- sys 0m0.004s
计算前两个数的(150,400)很快,而第三个大一点时会很慢,总共要15秒多才算完,是有点卡顿(慢)。
time虽然很便捷有用,但是不能给我们详细的代码性能细节。
详细性能分析cProfile
性能分析另一个常用的方法是使用cProfile,它可以提供很多性能信息
- python3 -m cProfile -s time performance.py
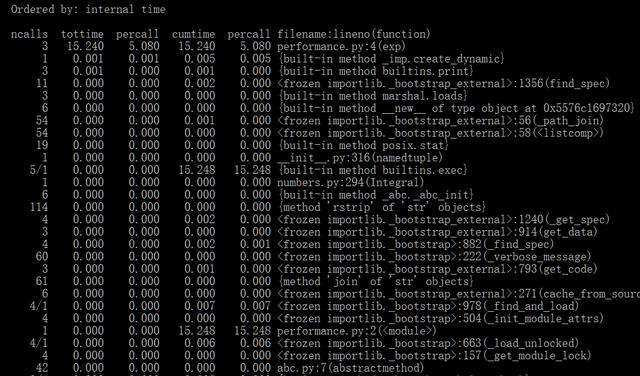
例子中,我们使用了cProfile模块和time参数运行测试脚本,以便按内部时间(cumtime)对行进行排序。如上图所示,使用cProfile可以给很多内部的具体信息,通过我们可以知道主要耗时是由exp函数导致。知道了程序的性能瓶颈所在,我们就再说明Python性能分析和优化。
优化特定功能
知道了将性能的瓶颈所在(实例中是exp函数),我们为了进一步具体问题具体分析,我们使用一个简单装饰器,以便跳过其他代码,专门分析性能瓶颈所设计的函数。然后使用装饰器进行测试,具体代码如下:
- def timeit_wrapper(func):
- @wraps(func)
- def wrapper(*args, **kwargs):
- start = time.perf_counter() # Alternatively, you can use time.process_time()
- func_return_val = func(*args, **kwargs)
- end = time.perf_counter()
- print('{0:<10}.{1:<8} : {2:<8}'.format(func.__module__, func.__name__, end - start))
- return func_return_val
- return wrapper
我们用这个装饰器来测试exp:
- @timeit_wrapper
- def exp(x):
- ...
- print('{0:<10} {1:<8} {2:^8}'.format('module', 'function', 'time'))
- exp(Decimal(150))
- exp(Decimal(400))
- exp(Decimal(3000))
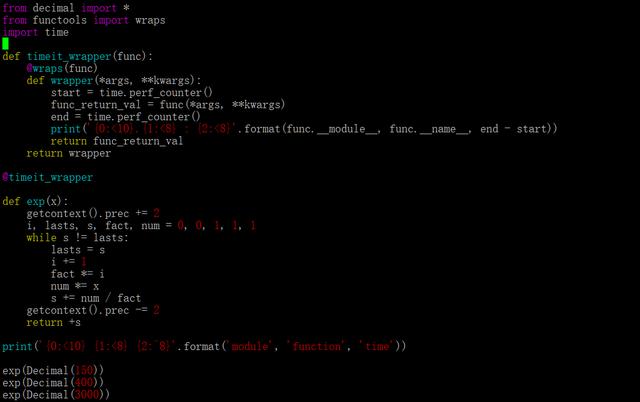
结果:
- module function time
- __main__ .exp : 0.00920036411844194
- __main__ .exp : 0.09822067408822477
- __main__ .exp : 15.228459489066154
代码中,我们用到了time包提供time.perf_counter函数,它还提供了另外一个函数time.process_time。两者的区别在于perf_counter返回的绝对时间,包括Python程序进程未运行时的时间,它可能会受到计算机负载的影响。而process_time仅返回用户时间(不包括系统时间),这仅是程序过程时间。
性能优化
最后是Python程序的性能优化,为了让Python程序运行得更快,我们提供一些可供参考的性能优化构想和策略的,通过这些策略我们一半可以提高应用的运行速度,最高情况下可以让你的应用快30%。
使用内建数据类型
很明显,内建数据类型非常快,尤其是与自定义类型相比,比如树或者链表。因为内建程序是用C实现的,所以其性能优势是Python代码所无法比拟的。
使用lru_cache缓存/记忆
很多时候缓存非常有效,可以极大的提高性能,尤其在数值计算和涉及大量重复调用(递归)时。考虑一个例子:
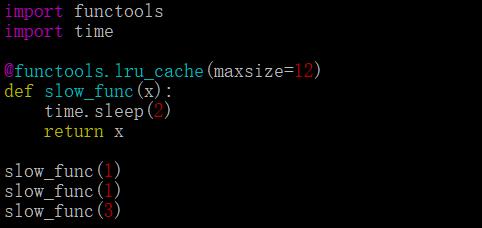
上面的函数使用time.sleep(2)模拟一个耗时的代码。第一次使用参数1调用时,它将等待2秒,然后返回结果。再次调用时,由于结果已被缓存,将跳过函数的执行,直返回。用3调用时候由于参数不一样会耗时2秒,总体耗时应该为4s,我们用time 验证:
- real 0m4.061s
- user 0m0.040s
- sys 0m0.015s
这和我们设想的一致。
使用局部变量
基于变量作用域中查找速度相关,在函数的局部变量具有很高的速度。其次是类级属性(如self.name)和最慢的是全局变量,如time.time(最慢)。所以我们可以通过避免使用不必要的全局变量来提高性能。
使用函数
这似乎有点出乎意料,因为涉及函数的内存占用都在堆栈上,而函数返回也会有开销。但是使用函数,可以避免使用全局变量,可以提高性能。因此,可以通过将整个代码包装在main函数中只调用一次来加速代码。
避免使用属性
另一个可以是影响程序性能的操作是点运算符访问对象属性。点运算符使用__getattribute__触发会字典查找,会在代码中产生额外的开销。我们可以通过一些使用函数而不是类方法的方式避免点操作,比如下面例子
#慢代码:
- import re
- def slow_func():
- for i in range(10000):
- re.findall(regex, line)
#快代码
- from re import findall
- def fast_func():
- for i in range(10000):
- findall(regex, line)
使用f-string
在循环中使用格式符(%s)或.format()时,字符串操作可能会变得非常缓慢。为了进行性能优化,我们应该使用f-string。它是Python 3.6引入的很具可读性,简洁性和最快的方法。比如:
- s + ' ' + t
- ' '.join((s, t))
- '%s %s' % (s, t)
- '{} {}'.format(s, t)
- Template('$s $t').substitute(s=s, t=t) # 慢代码
- f'{s} {t}' # 快代码
总结
性能的调试和优化是非常重要的码农技术之一。本文中,我们提供了Python应用性能调试和优化的技巧和策略,希望能对大家有所帮助。