在此之前我们介绍了数据库的分库分表问题,分库分表可以给我们带来非常好的扩展性与性能上的提升,但也随之带来一些问题,例如数据的主键ID分配问题。我们以Mysql为例,通常我们使用的是数据库的自增主键,我们在分表的时候也尽量保证业务上不需要跨表查询数据,但是难免会遇到这样的场景,这个时候我们就会面临这样一个问题,如果两张表上面的主键ID重复,那么业务就会出错,带来不可估量的后果。
那么我们如何解决主键唯一的问题呢?这里我们介绍几种常见的方法,以及他们的优缺点。
方法一
首先我们可以利用随机方法生成主键,通常,只要随机算法合理,适当地加点盐,生成的64位的主键ID,重复的概率极低(几乎可以不用考虑碰撞),这种方法的优点是实现非常简单,但是存在什么问题呢?首先是ID的长度会非常的长,我们都知道,在数据库中,主键ID过长会降低索引的性能。其次,随机生成主键ID是无序的,这就意味着插入新的数据的时候,都需要插入索引,我们都知道Mysql的索引是B+树,B+树如果不停地插入无序的数据,性能会大大降低,造成的结果就是插入性能降低。聪明的同学可能已经想到了,我们也可以生成有序的随机数,例如使用Twitter公司的SnowFlake,可以一定程度上避免B+树插入带来的影响。
方法二
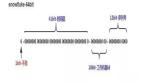
第二种方法,我们还是可以利用数据库的主键递增特性。在Mysql数据库中,是可以设置主键递增的步长,也就是我们不必在1,2,3这样递增,假如我们设置步长为10,开始为10,那就是10,20,30了。假如我们分了10张表,那么我们可以让每个表的起始分别是0到9,然后步长设置为10,这样子就可以保证十张表里面的数据不会重复了。这种方法的优点同样非常简单,只需要简单的配置而已,那么它存在什么问题呢?首先是扩展非常的不方便,如果我们想要把分表从10改成20呢?会给我们带来一定的麻烦。
方法三
第三种方法,我们可以维护一个ID分配器,我们可以使用Redis等相关组件,将提前分配好的ID放在Redis的队列当中,每次业务要插入的时候,先从预分配的队列中取一个元素出来,然后再插入数据库当中。当然这种做法需要一定的开发量,可以相对保证主键id的顺序,扩展也相对的简单。
总结
那么哪一种方法好呢?在计算机程序设计中,没有绝对的好也没有绝对地差,只要能够贴近业务,保证系统平稳运行,又不需要较大的开发与维护成本,那就是好方法,需要根据自己的业务与现在的开发运维经验进行选择。欢迎大家关注我,共同学习,共同进步。大家的支持是我继续唠嗑的动力。