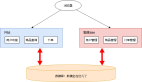
我从业之初便开始扮演“救火队员”角色,经常去线上执行“救火”、止损、攻关等应急工作,再通过分析、推理、验证…
“抽丝剥茧”的找出背后的根本原因,仿佛自己是个“经验丰富、从容冷静、思维缜密”的侦探。
以前我一直认为线上问题定位、分析处理能力是架构师的“看家功底”并常引以为傲。
但最近这两年我开始思考,其实“防火”比“救火”更重要,正如一句古话“上医治未病,中医治欲病,下医治已病”。下面我将为大家分享稳定性治理经验和阿里的稳定性保障体系。
阅读本文,你将会收获:
- 高并发、大流量场景的常见问题和应对手段
- 知名互联网公司的高可用架构和稳定性保障体系
稳定性治理的常见场景
突发大流量
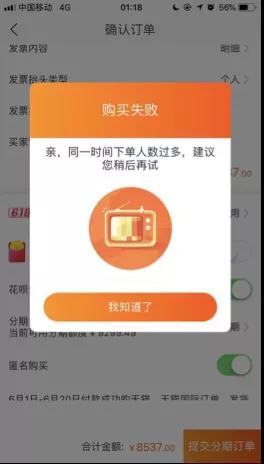
相信大家对上图并不陌生,尤其在刚刚过去的双 11、双 12 中。这是电商大促场景中执行了最常用的自动预案 - “限流保护”,并非很多朋友说的“宕机”、“崩溃”。

“限流”是应对高并发或者突发大流量场景下的“三板斧”之一,不管是在电商大促、社交媒体突发热点事件(例如:遇到“知名女星出轨”),还是在常态下都是非常有必要的保护手段。
本质上就是检查到当前请求量即将超出自身处理能力时,自动执行拒绝(或者执行“请求排队”),从而防止系统被彻底压垮。
不稳定服务

讲到“限流”,那就不得不提另外一板斧“降级”。除了我们之前所提到的 “开关降级”(关闭次要功能或服务)、兜底、降低一致性等之外,在技术层面最常用就是“自动熔断降级”。
“限流”是为了防止大流量压垮系统,而“熔断”是为了防止不稳定的服务引发超时或等待,从而级联传递并最终导致整个系统雪崩。
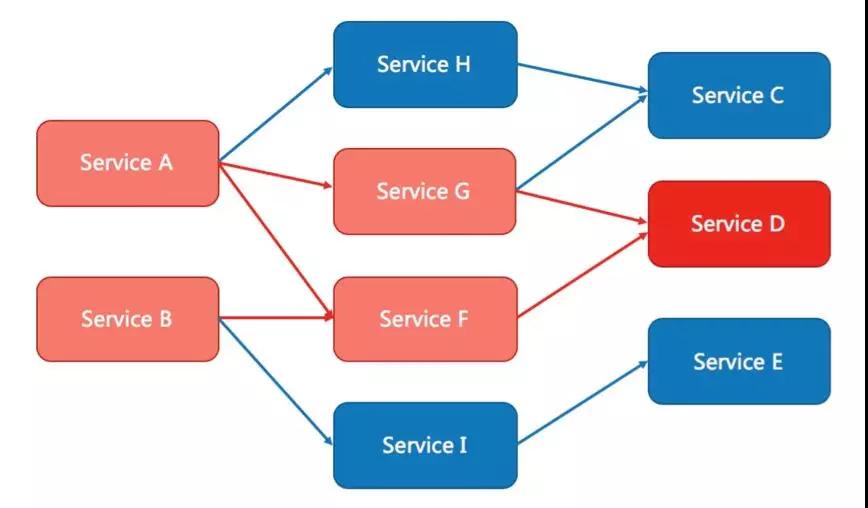
如图所示,假设服务 D 此时发生了故障或者 FullGC 等,则会导致上游的服务 G、F 中产生大量等待和异常,并级联传递给最上游的服务 A、B。
即便在服务 G、F 中设置了“超时”(如果没有设置“超时”那情况就更糟糕了),那么也会导致线程池中的大量线程资源被占用。
如果服务 H、I 和服务 G、F 在同一个应用中且默认共用同一个线程池,那么也会因为资源耗尽变得不可用,并最终导致最上游的服务 A 和服务 B 整体不可用,全部链路都将异常,线上核心系统发生这种事故那就是灾难。
假如我们在检查到服务 G 和服务 F 中 RT 明显变长或者异常比例增加时,能够让其自动关闭并快速失败,这样 H 和 I 将不会受影响,最上游的服务 A 和服务 B 还能保证“部分可用”。
举个现实生活中更通俗的例子,当你们家的电器发生短路时空气开关会自动跳闸(保险丝会自动 “熔断”)。
这就是通过牺牲你们家的用电而换回小区的正常供电,否则整个线路都会烧毁,后果会不堪设想。
所以,你得结合实际业务场景先找出哪些接口、服务是可以被“降级”的。
架构单点
这个事件大概发生在 2015 年,被载入了支付宝的“史册”,也推动了蚂蚁金服整体 LDC 架构(三地五中心的异地多活架构)的演进。
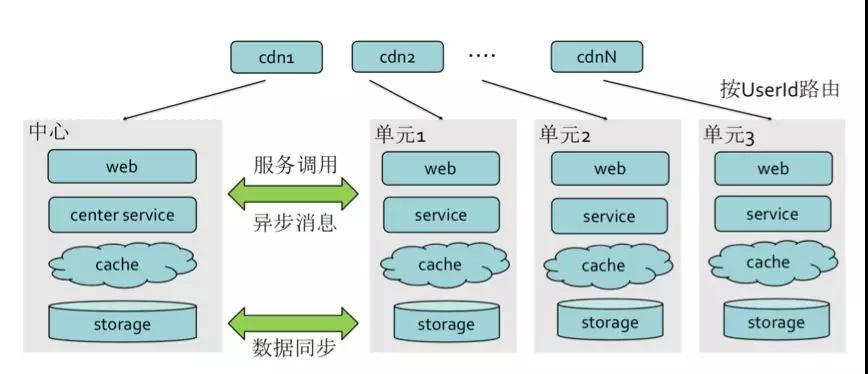
异地多活架构:
- 突破单机房容量限制
- 防机房单点,高可用
内建质量
根据以往的经验,60% 以上的故障都是由变更引起的,请牢记变更“三板斧”:
- 可回滚/可应急
- 可灰度
- 可监控
预防质量事故的常用手段:
- 做好分析、设计、评审,容量评估,规避风险
- 制定规范,控制流程,加入代码扫描和检查等
- 阉割做好 Code Review
- 测试用例覆盖(通过率、行覆盖率、分支覆盖率),变更全量回归
- 尽可能的自动化,避免人肉(易出错),关键时刻执行 Double Check
高可用架构的基石:稳定性保障体系
从故障视角来看稳定性保障,如下图:
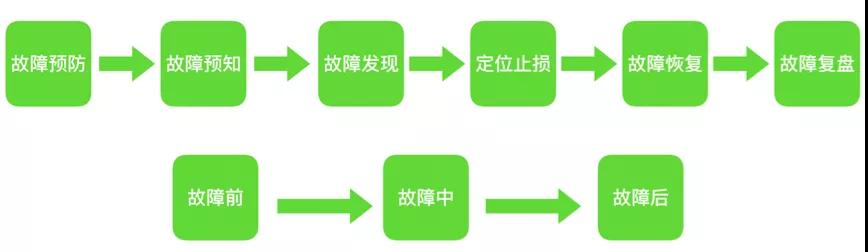
稳定性保障的核心目标如下:
- 尽早的预防故障,降低故障发生几率。
- 及时预知故障,发现定义故障。
- 故障将要发生时可以快速应急。
- 故障发生后能快速定位,及时止损,快速恢复。
- 故障后能够从中吸取教训,避免重复犯错。
仔细思考一下,所有的稳定性保障手段都是围绕这些目标展开的。
稳定性保障体系
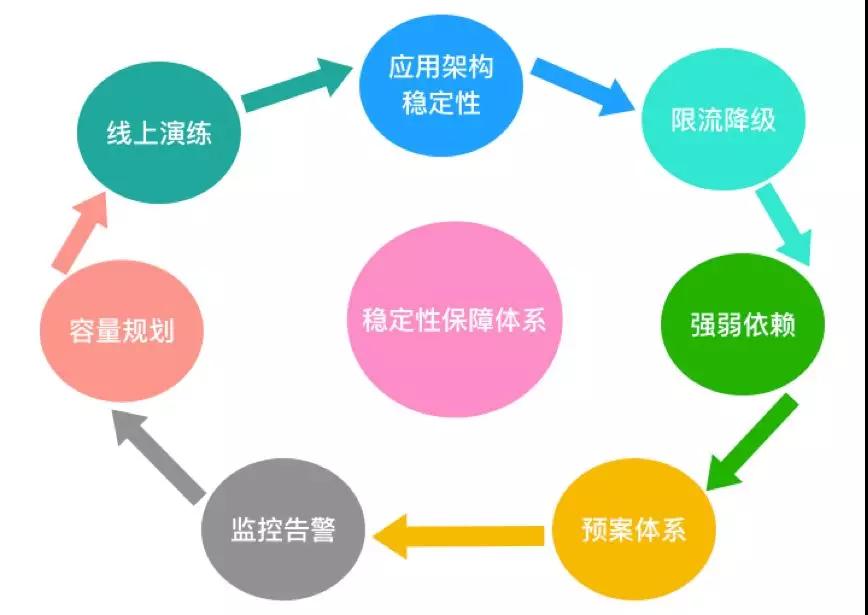
上图涵盖了稳定性体系的各个方面,下面我来一一讲解。
应用架构稳定性
应用架构稳定性相对是比较广的话题,按我的理解主要包括很多设计原则和手段:
①架构设计简单化。系统架构简单清晰,易于理解,同时也需要考虑到一定的扩展性,符合软件设计中 KISS 原则。
现实中存在太多的“过度设计”和“为了技术而技术”,这些都是反例,架构师需懂得自己权衡。
②拆分。拆分是为了降低系统的复杂度,模块或服务“自治”,符合软件设计中“单一职责”原则。拆分的太粗或者太细都会有问题,这里没有什么标准答案。
应该按照领域拆分(感兴趣同学可以学习下 DDD 中的限界上下文),结合业务复杂程度、团队规模(康威定律)等实际情况来判断。可以想象 5 个人的小团队去维护超过 30 多个系统,那一定是很痛苦的。
③隔离。拆分本质上也是一种系统级、数据库级的隔离。此外,在应用内部也可以使用线程池隔离等。分清“主、次”,找出“高风险”的并做好隔离,可以降低发生的几率。
④冗余。避免单点,容量冗余。机房是否单点,硬件是否单点,应用部署是否单点,数据库部署是否单点,链路是否单点…硬件和软件都是不可靠的,冗余(“备胎”)是高可用保障的常规手段。
⑤无状态、一致性、并发控制、可靠性、幂等性、可恢复性…等。比如:投递了一个消息,如何保障消费端一定能够收到?上游重试调用了你的接口,保证数据不会重复?Redis 节点挂了分布式锁失效了怎么办?…这些都是在架构设计和功能设计中必须考虑的。
⑥尽可能的异步化,尽可能的降低依赖。异步化某种程度可以提升性能,降低 RT,还能减少直接依赖,是常用的手段。
⑦容错模式。
我在团队中经常强调学会“面向失败和故障的设计”,尽可能做一个“悲观主义者”,或许有些同学会不屑的认为我是“杞人忧天”,但事实证明是非常有效的。
从业以来我有幸曾在一些高手身边学习,分享受益颇多的两句话:
- 出来混,迟早要还的
- 不要心存侥幸,你担心的事情迟早要发生的
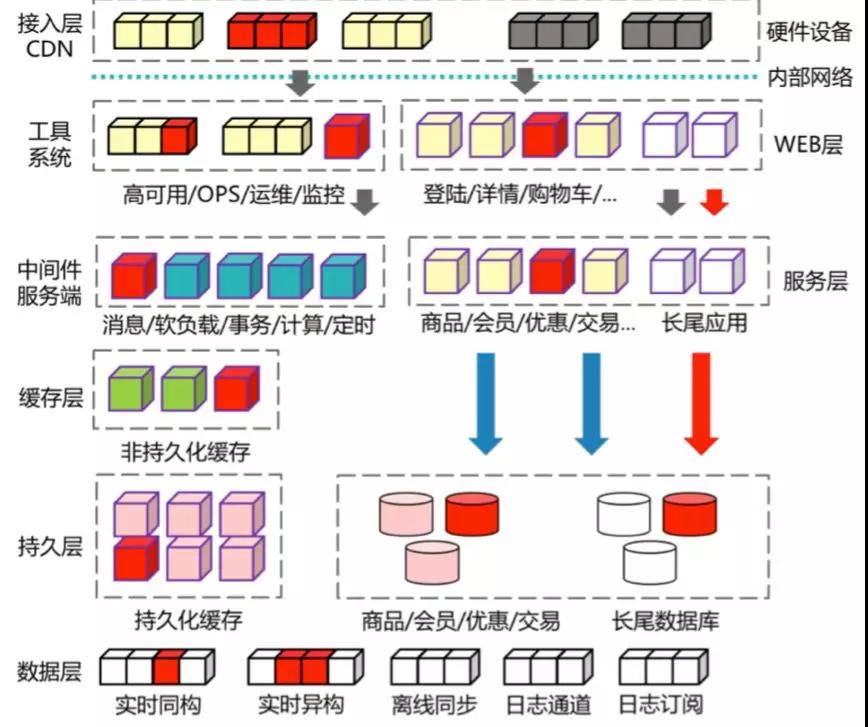
上图是比较典型的互联网分布式服务化架构,如果其中任意红色的节点出现任何问题,确定都不会影响你们系统正常运行吗?
限流降级
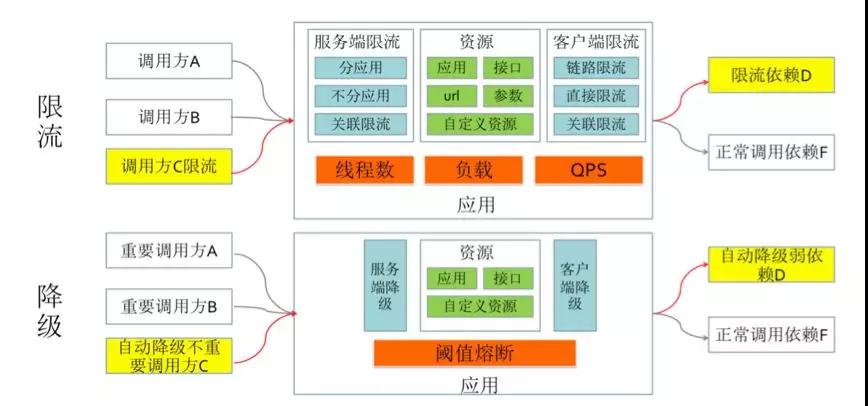
前面介绍过了限流和降级的一些场景,这里简单总结下实际使用中的一些关键点。
以限流为例,你需要先问自己并思考一些问题:
- 你限流的实际目的是什么?仅仅只做过载保护?
- 需要什么限流策略,是“单机限流”还是“集群限流”?
- 需要限流保护的资源有哪些?网关?应用?
- 水位线在哪里?限流阈值配多少?
- …
同理,降级你也需要考虑:
- 系统、接口依赖关系
- 哪些服务、功能可以降级掉
- 是使用手工降级(在动态配置中心里面加开关)还是自动熔断降级?熔断的依据是什么?
- 哪些服务可以执行兜底降级的?怎么去兜底(例如:挂了的时候走缓存或返回默认值)?
- …
这里我先卖下关子,篇幅关系,下篇文章中我会专门讲解。
监控预警

上图是我个人理解的一家成熟的互联网公司应该具备的监控体系。前面我提到过云原生时代“可观察性”,也就是监控的三大基石。
这里再简单补充一下 “健康检查”,形成经典的“监控四部曲”:
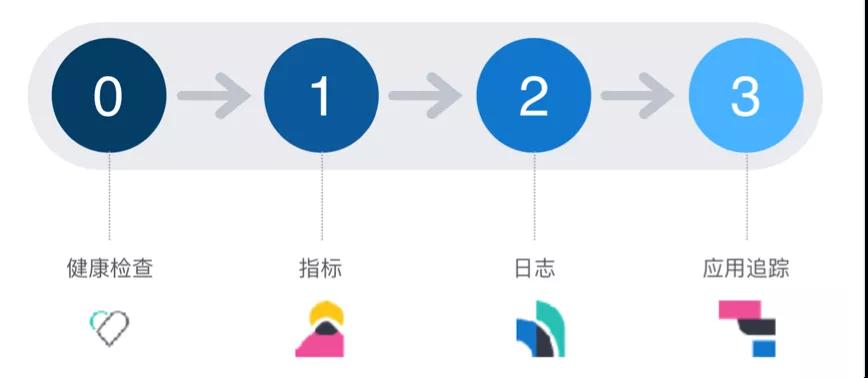
关于健康检查,主要就分为“服务端轮询”和“客户端主动上报”两种模式,总的来讲各有优缺点,对于类似 MySQL 这类服务是无法主动上报的(除非借助第三方代理)。需要注意的是传统基于端口的健康检查很难识别“进程僵死”的问题。

提到监控那就不得不提 Google SRE 团队提出的监控四项黄金指标:
- 延迟:响应时间
- 流量:请求量、QPS
- 错误:错误数、错误率
- 饱和度:资源利用率
类似的还有 USE 方法,RED 方法,感兴趣的读者可以自行查阅相关资料。
云原生时代通常是应用/节点暴露端点,监控服务端采用 Pull 的方式采集指标,当前比较典型的就是 Prometheus 监控系统,感兴趣的可以详细了解。
当然,以前也有些监控是通过 Agent 采集指标数据然后上报到服务端的。
除了监控自身,告警能力也是非常重要的。告警的阈值配多少也需要技巧,配太高了不灵敏可能会错过故障,配太低了容易“监控告警疲劳”。
强弱依赖治理

这是网上找的一张“系统依赖拓扑图”,可见面对这种复杂性,无论是通过个人经验,还是借助“链路跟踪工具”都很难快速理清的。
何为强弱依赖?A 系统需要借助 B 系统的服务完成业务逻辑,当 B 挂掉的时候会影响 A 系统中主业务流程的推进,这就是“强依赖”。
举个例子:下单服务依赖“生成订单号”,这就是“强依赖”,“扣库存”这也是 “强依赖”。
同理,当 A 依赖的 B 系统挂掉的时候,不会影响主流程推进,那么就是“弱依赖”。例如:购物车页面中显示的库存数是非必须的。
如何梳理出这种强弱依赖,这个在阿里内部是有专门的中间件可以做的,目前开源社区没有替代品,可能就要结合链路跟踪+个人的经验,针对系统级,接口级去做链路梳理。
我们重点关注的是 “强依赖”,而“弱依赖” 通常是可以执行容灾策略的,例如:可以直接降级掉,可以返回为空或者默认值、执行兜底等。
总结出来关键有几点:当前业务功能/应用/服务、依赖的服务描述、依赖类型(比如:RPC 调用),峰值调用量、链路的流量调用比例、强弱等级、挂掉的后果等。
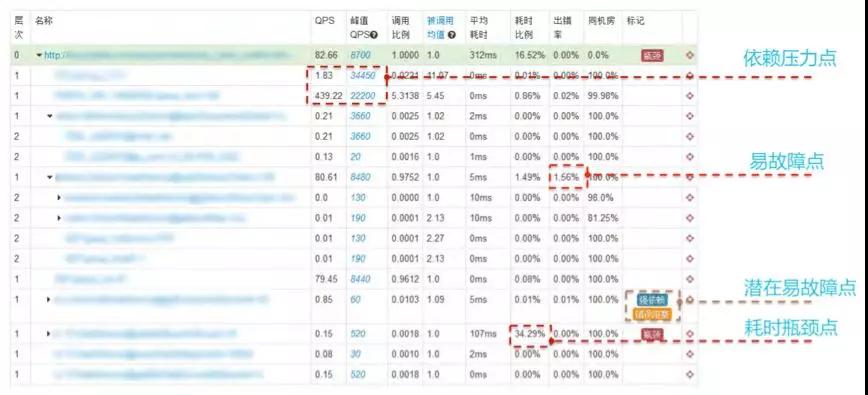
容量规划
容量规划是非常重要的,无论是成本控制还是稳定性保障都需要。否则压根不知道需要投入多少资源以及资源投入到哪里。
需要了解系统极限水位在哪里,再推算出合理的“阈值”来做好“过载保护”,这也是执行是限流、降级等预案体系的关键依据和基础。
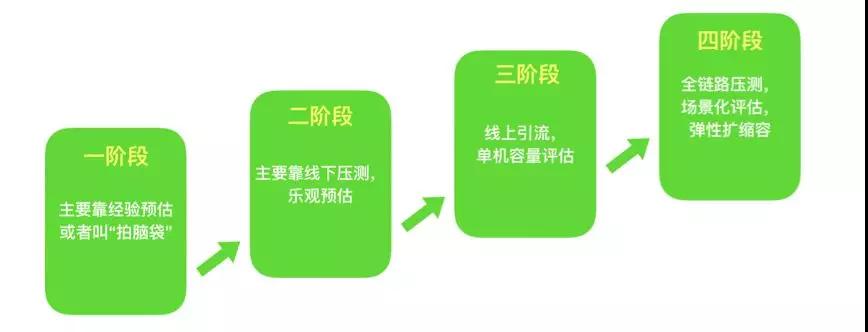
第一阶段:主要依靠经验值、理论值等来预估的,或者是靠“拍脑袋”的
前几年资本市场情况比较好,互联网公司比较典型的现象:老板,我需要买 100 台服务器,50 台跑应用,20 台跑中间件,10 台做数据库…预计可以扛住日均 1000W 访问量,每天 100W 订单…
靠谱一点的人还能扯出 “MySQL 并发连接数在几 core 几 G 大概能到 xxx”、 “Redis 官方称可以达到 10W TPS”之类的参考值,这种至少听起来还有那么一点道理。
不靠谱的人呢?那可能就真是瞎说的一个数字,或者会说“我上家公司就用了这么多支撑的”,其实纯靠拍脑袋的。
总之,这都是很不靠谱的,会造成资源分配不合理,有些浪费而有些饥荒。
第二阶段:通过线下压测手段来进行
线下压测通常是压测的单接口、单节点,压测结果可以帮助我们了解应用程序的性能状况、定位性能瓶颈,但是要说做整体的容量规划,那参考价值不大。
因为实际情况往往复杂太多,网络带宽、公共资源、覆盖场景不一致、线上多场景混合等各种因素。
根据“木桶短板”的原理,系统的容量往往取决于最弱的那一环节。正所谓 “差之毫厘,失之千里”。
第三阶段:通过线上单机压测来做
比较常见的手段有:线上引流、流量复制、日志回放等。其中线上引流实施起来最简单,但需要中间件统一。
通过接入层或服务注册中心(软负载中心)调整流量权重和比例,将单机的负载打到极限。这样就比较清楚系统的实际水位线在哪里了。
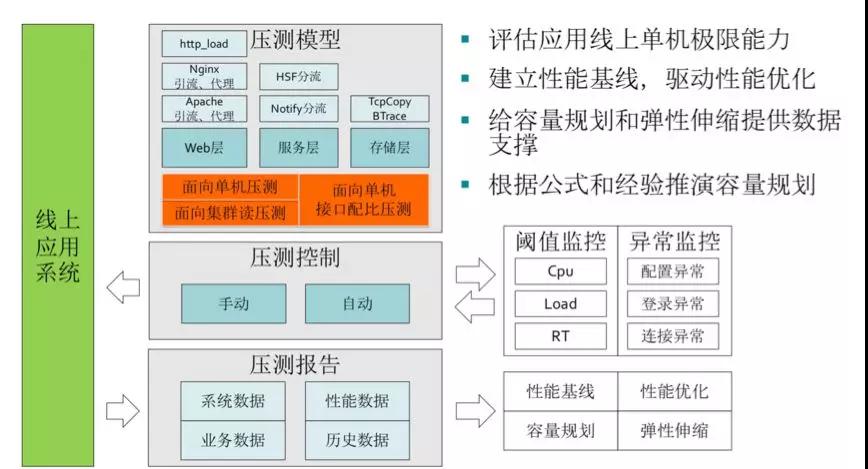
第四阶段:全链路压测,弹性扩容
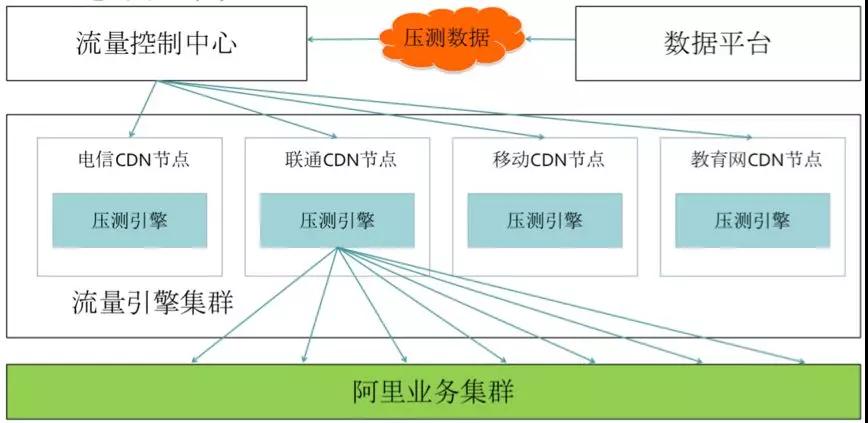
这个是阿里首创的,目前很多公司在效仿。属于是业务倒逼技术创造出来的手段。
全链路压测涉及到的内容会比较多,关键的步骤包括:
- 链路梳理
- 基础数据准备、脱敏等
- 中间件改造(透传影子标,软负载/消息/缓存/分库分表等路由,建立影子表)
- 建立压测模型、流量模型、流量引擎
- 预案体系的检查
- 执行压测,紧盯监控告警
- 数据清理
对业务开发团队同学来讲,关于链路梳理、流量模型的评估是其中最重要的环节,全链路压测就是模拟用户真实的访问路径构造请求,对生产环境做实际演练。
这里我以大家熟悉的购买电影票的场景为例。如下图,整个链路中业务流量其实是呈“漏斗模型”的,至于每一层的比例是多少,这个第一就是参考当前的监控,第二就是参考历史数据去推算平均值了。
漏斗模型推演示例:
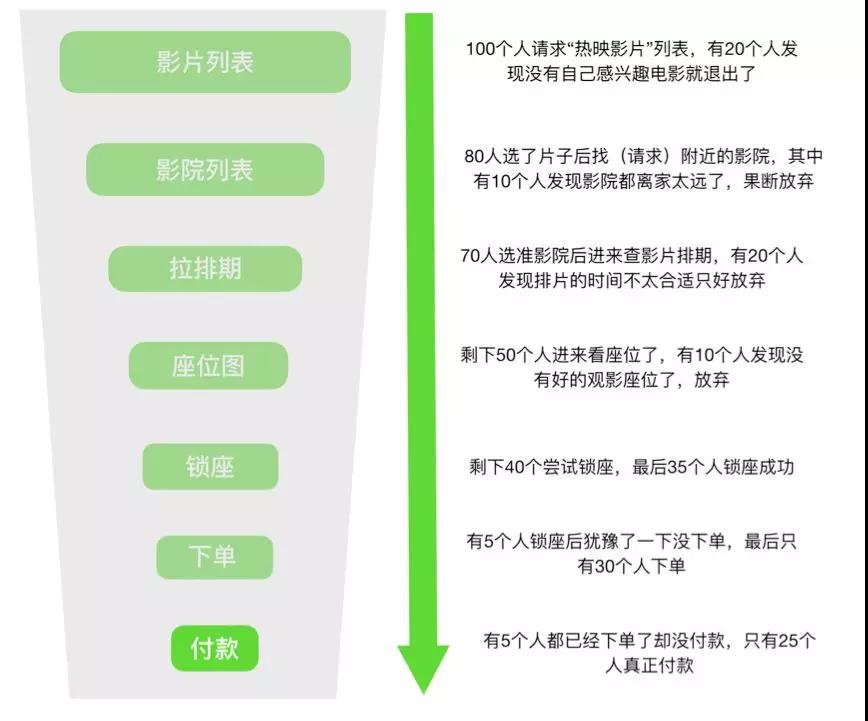
可以看出每一层(不同应用、不同服务)所需要承载的真实流量不一样,负载也是不一样的。
当然,实际场景更复杂,实际情况是多场景混合并行的,A 用户在拉排期的时候 B 用户已经在锁座了…
我们要做的,就是尽可能接近真实。还有最关键的一点要求:不能影响线上真实业务。这就需要非常强的监控告警和故障隔离能力了。
关于系统容量和水位标准,这里给大家一个建议参考值:
- 水位标准:单机房部署水位应在 70% 以下,双机房部署水位应在 40% 以下
- 单机水位:单机负载 / 单机容量
- 集群水位:集群负载 / 集群容量
- 理论机器数:实际机器数 *(集群水位 / 水位标准)
为什么双机房是 40%?一个机房故障了流量全都切到另外一个机房去,要确保整体不受影响,不会被压垮。
预案体系
电影片段中 “检查到有未知生物入侵地球,联合国宣布启动进入一级戒备,马上启动宇宙飞船达到现场” ,“已经了解清楚,并按协议执行驱逐指令,目前已经离开” … 这就是典型的预案体系。
触发条件、等级、执行动作、事后情况都非常清晰,整个过程还带有闭环的(当然这片段是我 YY 出来的)。
前面我讲过“面向失败的设计”,就是尽可能的考虑到各种异常场景和特殊情况。
这些零散的“知识点”,还有日常的一些复盘的经验都可以作为日后的预案。
当然,前面我们讲过的限流、降级等应急手段,容错模式也是整个预案体系中非常重要的。预案积累的越丰富,技术往往越成熟。
总的来讲,预案的生命周期包括:
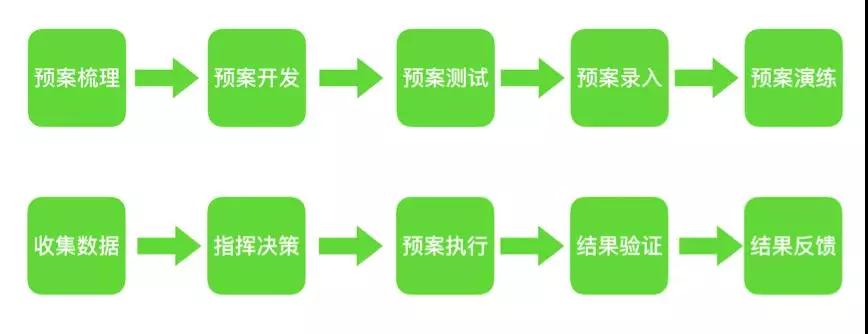
从大的层面又可以分为:
- 事前制定和完善预案
- 日常演练预案
- 事中统一指挥,收集数据,决策并执行预案
- 事后总结并继续完善和改进预案
当然,这里说明下,有些预案是达到明确的触发条件后自动执行的,有些是需要依赖人工决策然后再触发执行的。
这里我给一个简单的 Demo 给大家参考:
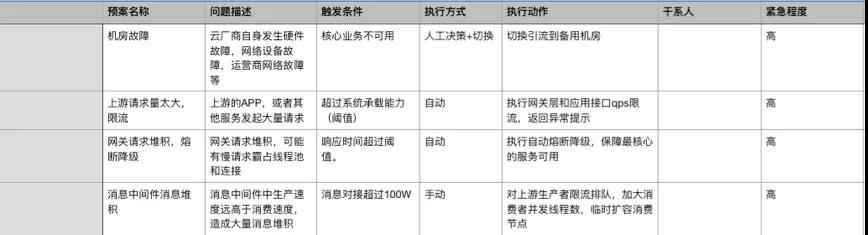
线上演练
正所谓 “养兵千日,用兵一时”。现实生活中的“消防演习”就是一个好例子,否则时间久了根本不知道灭火器放在哪里,灭火器是怎么打开的?
打开后还能喷出泡沫来吗?对应到我们技术领域也是一样的,你怎么知道你的预案都是有效的?你怎么保证 on call 值班机制没问题?你怎么知道监控告警真的很灵敏?
在阿里内部不管是大促还是常态,都会不定期来一些线上演练。在蚂蚁内部每年都会有“红蓝军对抗演练”,这是一种非常好的“以战养兵”的做法。
先看一张关于故障画像的大图,这里列举了典型的一些故障场景,大家不妨思考下如何通过“故障注入”来验证系统的高可用能力。
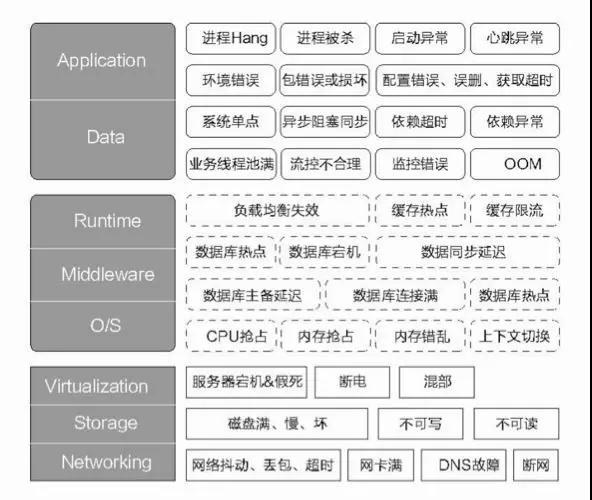
简单总结故障演练主要场景和目的:
- 预案有效性、完整性
- 监控告警的准确性、时效性
- 容灾能力测试
- 检查故障是否会重现
- 检查 on call 机制,验证突发情况团队实际战斗能力
- …
“混沌工程”是近年来比较流行的一种工程实践,概念由 Netflix 提出,Google、阿里在这方面的实践经验比较丰富(或者说是不谋而合,技术顶尖的公司大都很相似)。
通俗点来讲就是通过不断的给现有系统“找乱子”(进行实验),以便验证和完善现有系统的高可用性、容错性等。
引用一句鸡汤就是:“杀不死我的必将使我更强大”,混沌工程的原则:
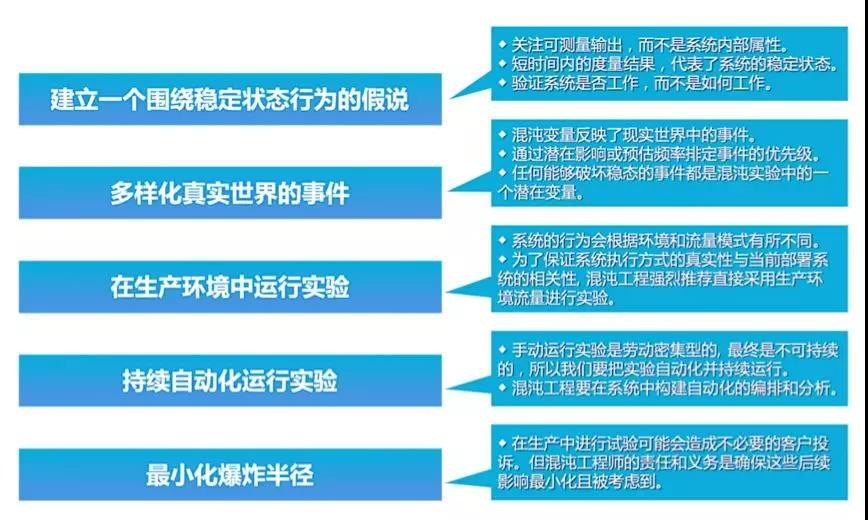
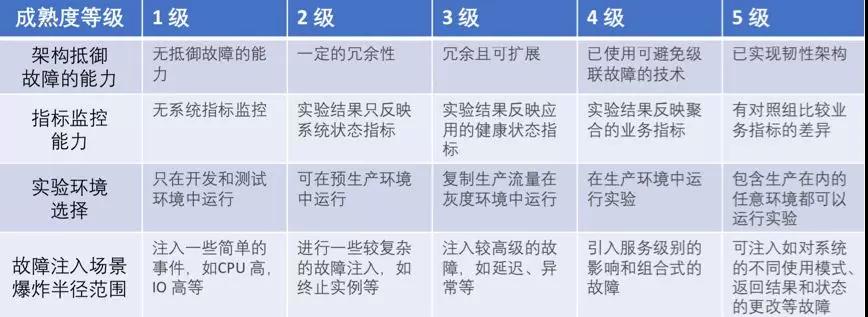
系统成熟度模型:
面向故障/失败的设计更是一种技术文化,应该在团队中大力推广。
小结
本文我主要讲解了稳定性治理的常见手段,稳定性保障体系。其中涉及到的知识、手段、内容都非常多。
限于篇幅的关系,不可能每一项都特别细致。还需读者慢慢消化,更重要的是好好思考现状并努力改进,也欢迎留言讨论。
作者:丁浪
简介:目前在创业公司担任高级技术架构师。曾就职于阿里巴巴大文娱和蚂蚁金服。具有丰富的稳定性保障,全链路性能优化的经验。架构师社区特邀嘉宾!