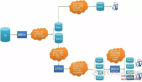
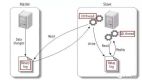
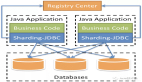
随着互联网应用的广泛普及,海量数据的存储和访问成为了系统设计的瓶颈问题。对于一个大型的互联网应用,每天几十亿的PV无疑对数据库造成了相当高的负载。对于系统的稳定性和扩展性造成了极大的问题。通过数据切分来提高网站性能,横向扩展数据层已经成为架构研发人员首选的方式。
mysql主从复制原理
主要涉及三个线程:binlog 线程、I/O 线程和 SQL 线程。
- binlog 线程 :负责将主服务器上的数据更改写入二进制日志(Binary log)中。
- I/O 线程 :负责从主服务器上读取二进制日志,并写入从服务器的中继日志(Relay log)。
- SQL 线程 :负责读取中继日志,解析出主服务器已经执行的数据更改并在从服务器中重放(Replay)。
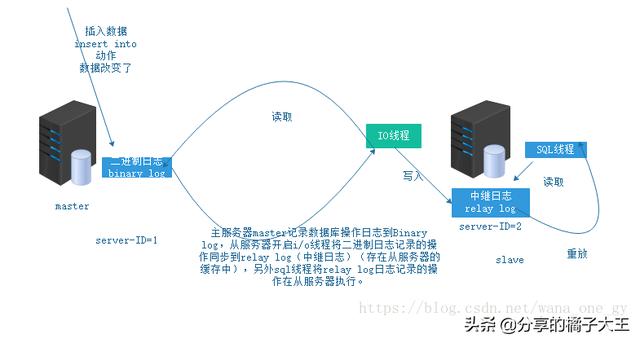
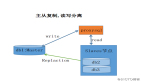
这张图就很清晰表达出流程
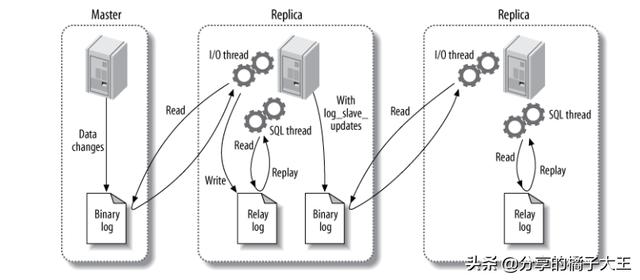
1:主库db的更新事件(update、insert、delete)被写到binlog
2:从库发起连接,连接到主库
3:此时主库创建一个binlog dump thread线程,把binlog的内容发送到从库
4:从库启动之后,创建一个I/O线程,读取主库传过来的binlog内容并写入到relay log
5:还会创建一个SQL线程,从relay log里面读取内容,从Exec_Master_Log_Pos位置开始执行读取到的更新事件,将更新内容写入到slave的db.
主从同步复制模式:

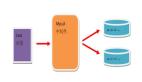
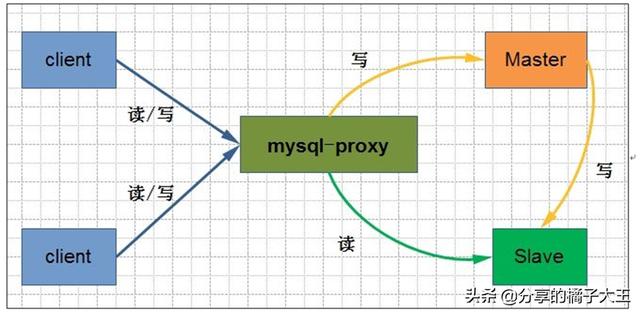
读写分离:
MYSQL读写分离的原理其实就是让Master数据库处理事务性增、删除、修改、更新操作(CREATE、INSERT、UPDATE、DELETE),而让Slave数据库处理SELECT操作,MYSQL读写分离前提是基于MYSQL主从复制,这样可以保证在Master上修改数据,Slave同步之后,WEB应用可以读取到Slave端的数据。
数据库分区:
分区并不是生成新的数据表,而是将表的数据均衡分摊到不同的硬盘,系统或是不同服务器存储介子中,实际上还是一张表。另外,分区可以做到将表的数据均衡到不同的地方,提高数据检索的效率,降低数据库的频繁IO压力值,分区的优点如下:
- 相对于单个文件系统或是硬盘,分区可以存储更多的数据;
- 数据管理比较方便,比如要清理或废弃某年的数据,就可以直接删除该日期的分区数据即可;
- 精准定位分区查询数据,不需要全表扫描查询,大大提高数据检索效率;
- 可跨多个分区磁盘查询,来提高查询的吞吐量;
- 在涉及聚合函数查询时,可以很容易进行数据的合并;
1、水平分区
这种形式分区是对表的行进行分区,通过这样的方式不同分组里面的物理列分割的数据集得以组合,从而进行个体分割(单分区)或集体分割(1个或多个分区)。所有在表中定义的列在每个数据集中都能找到,所以表的特性依然得以保持。
2、垂直分区
这种分区方式一般来说是通过对表的垂直划分来减少目标表的宽度,使某些特定的列被划分到特定的分区,每个分区都包含了其中的列所对应的行。
什么时候考虑使用分区?
- 一张表的查询速度已经慢到影响使用的时候。
- sql经过优化
- 数据量大
- 表中的数据是分段的
- 对数据的操作往往只涉及一部分数据,而不是所有的数据
分库分表:
分库分表的原因:
- 随着单库中的数据量越来越大,相应的,查询所需要的时间也越来越多,相当于数据的处理遇到了瓶颈
- 单库发生意外的时候,需要修复的是所有的数据,而多库中的一个库发生意外的时候,只需要修复一个库(当然,也可以用物理分区的方式处理这种问题)
什么时候考虑使用分库?
单台DB的存储空间不够
随着查询量的增加单台数据库服务器已经没办法支撑
分库解决的问题:
其主要目的是为突破单节点数据库服务器的 I/O 能力限制,解决数据库扩展性问题。
垂直拆分
将系统中不存在关联关系或者需要join的表可以放在不同的数据库不同的服务器中。
按照业务垂直划分。比如:可以按照业务分为资金、会员、订单三个数据库。
需要解决的问题:跨数据库的事务、jion查询等问题。
水平拆分
例如,大部分的站点。数据都是和用户有关,那么可以根据用户,将数据按照用户水平拆分。
按照规则划分,一般水平分库是在垂直分库之后的。比如每天处理的订单数量是海量的,可以按照一定的规则水平划分。需要解决的问题:数据路由、组装。
什么时候考虑分表?
- 一张表的查询速度已经慢到影响使用的时候。
- sql经过优化
- 数据量大
- 当频繁插入或者联合查询时,速度变慢
分表解决的问题
分表后,单表的并发能力提高了,磁盘I/O性能也提高了,写操作效率提高了
- 查询一次的时间短了
- 数据分布在不同的文件,磁盘I/O性能提高
- 读写锁影响的数据量变小
- 插入数据库需要重新建立索引的数据减少
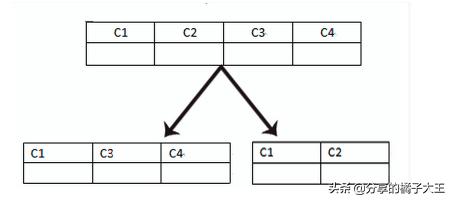
垂直分表
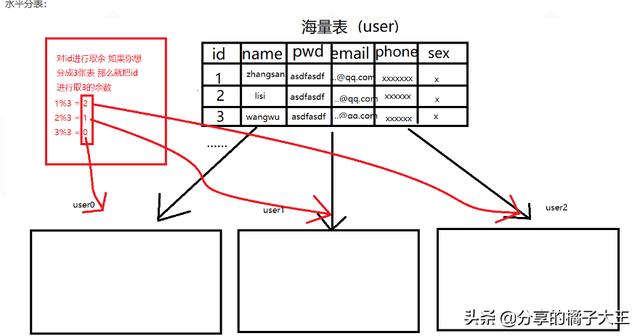
水平分表
存储演变:
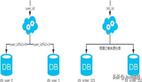
单库单表
单库单表是最常见的数据库设计,例如,有一张用户(user)表放在数据库db中,所有的用户都可以在db库中的user表中查到。
单库多表
随着用户数量的增加,user表的数据量会越来越大,当数据量达到一定程度的时候对user表的查询会渐渐的变慢,从而影响整个DB的性能。如果使用mysql, 还有一个更严重的问题是,当需要添加一列的时候,mysql会锁表,期间所有的读写操作只能等待。
可以通过某种方式将user进行水平的切分,产生两个表结构完全一样的user_0000,user_0001等表,user_0000 + user_0001 + …的数据刚好是一份完整的数据。
多库多表
随着数据量增加也许单台DB的存储空间不够,随着查询量的增加单台数据库服务器已经没办法支撑。这个时候可以再对数据库进行水平拆分。
数据库额外小知识:
MySQL 使用自增ID主键和UUID 作为主键的优劣比较详细过程(从百万到千万表记录测试)
(1)单实例或者单节点组:
经过500W、1000W的单机表测试,自增ID相对UUID来说,自增ID主键性能高于UUID,磁盘存储费用比UUID节省一半的钱。所以在单实例上或者单节点组上,使用自增ID作为首选主键。
(2)分布式架构场景:
20个节点组下的小型规模的分布式场景,为了快速实现部署,可以采用多花存储费用、牺牲部分性能而使用UUID主键快速部署;
20到200个节点组的中等规模的分布式场景,可以采用自增ID+步长的较快速方案。
200以上节点组的大数据下的分布式场景,可以借鉴类似twitter雪花算法构造的全局自增ID作为主键。