在 golang 中创建 goroutine 是一件很容易的事情,但是不合理的使用可能会导致大量 goroutine 无法结束,资源也无法被释放,随着时间推移造成了内存的泄漏。避免 goroutine 泄漏的关键是要合理管理 goroutine 的生命周期,通过导出 runtime 指标和利用 pprof 可以发现和解决 goroutine 泄漏问题。
笔者维护了一个通过 SSH 连接到目标机器并执行命令的服务,这是一个内部小服务,平时没有问题的时候一般也不会关注。大约 4 个月前,最后一次更新的时候,增加了一个任务计数器并且导出到 prometheus 中监控起来。近期发现这个计数器在稳步增加。
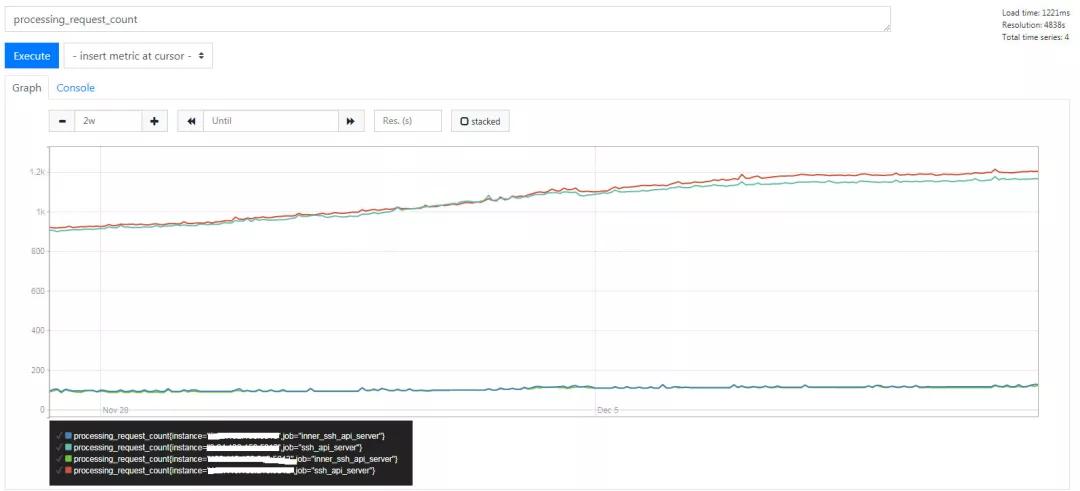
第一反应是,好事!调用量稳步增长了!!但是一想不对啊,这内部小服务哪儿来这么多调用量。于是再看看 goroutine 的监控情况(这个数据从 runtime.NumGoroutine()获取的)
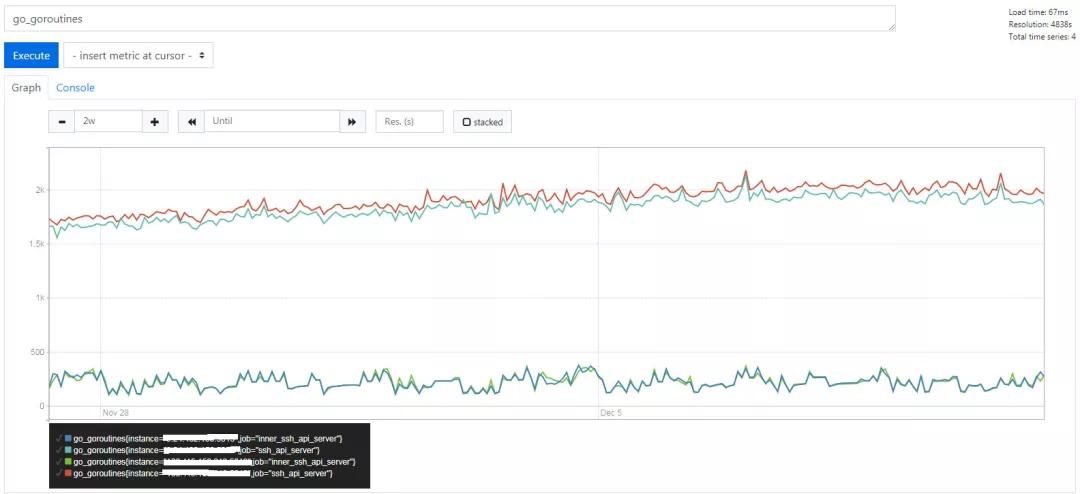
goroutine 的数量也是稳步增加的,单位时间请求量增加,goroutine 数量也增进,没毛病。但是又再转念一想,内部小服务,不可能不可能。
于是再看一下所有请求在 mm 系统的视图:
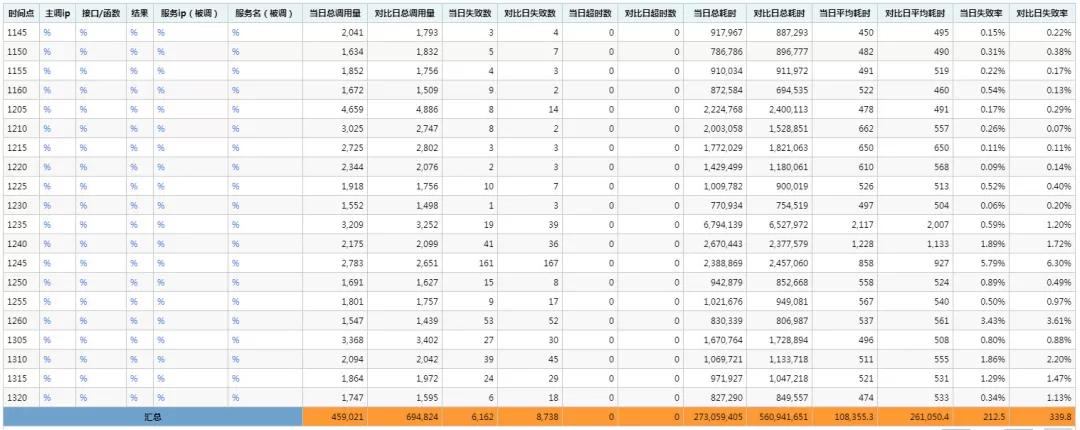
可以看出,每 5 分钟请求量在 2000 左右,平均下来每分钟 400 的请求量,上面 prometheus 监控图中,每个曲线是一个实例,实际上部署了 4 个实例,因此 400 还要除以 4 得到单个实例(曲线)的请求量应该在 100/min 左右,在服务刚启动的时候该计数器也确实在 100/min 左右,随着时间推移慢慢泄漏了。
Goroutine 泄漏 (Goroutine leak)
虽然心里想着 99%是泄漏了,但是也要看点详细的信息。之前在服务里已经启用了 net/http/pprof,因此直接请求 pprof 暴露出来的 HTTP 接口。
# goroutines摘要curl http://service:port/debug/pprof/goroutine?debug=1# goroutines详情curl http://service:port/debug/pprof/goroutine?debug=2
先看一下导出的 goroutine 摘要:
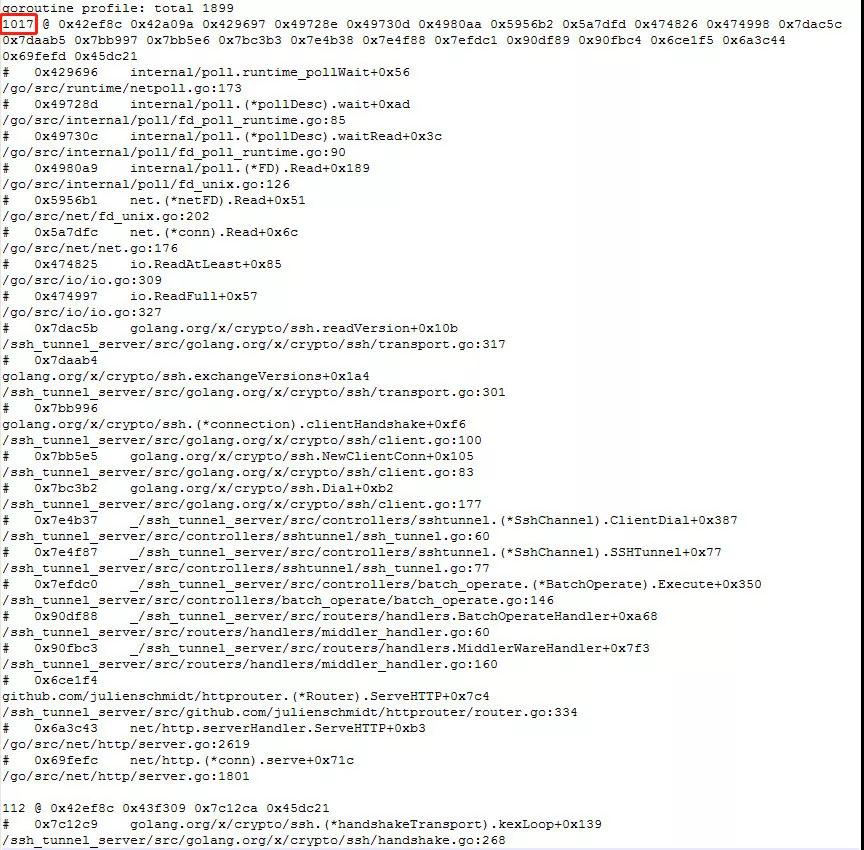
有 1000+个 goroutine 处于同一个状态,简单看是等待读数据,再看下导出的 goroutine 详情:

不看不知道,一看吓一跳,详情里有 goroutine 阻塞的时间超过了 20w 分钟(4 个月)……
可以肯定是 goroutine 泄漏无疑了。为什么会泄漏?只有顺着 pprof 导出的 goroutine 信息去排查了。处于 IO wait 状态最多的这 1000 多 goroutine 的调用栈都打出来了,根据这段调用栈内容来看,找到对应代码的位置,从 ssh.Dial 开始一直到某个地方进行 io.ReadFull 便阻塞住了。
这个服务进行 ssh 连接使用的是 golang.org/x/crypto/ssh 这个包。先看一下在这个服务里调用 ssh.Dial 的地方:
- clientConfig := &ssh.ClientConfig{
- ...
- Timeout: 3 * time.Second,
- ...
- }
- // connet to ssh
- client, err := ssh.Dial("tcp", fmt.Sprintf("%s:%d", s.Host, 36000), clientConfig)
看起来是没啥问题的,毕竟传入了一个 Timeout 参数,不应该会阻塞。接着继续看下去发现了一些问题。直接来到调用栈中阻塞的地方(先不看 library 和 runtime,这两个一般没问题),是在进行 SSH Handshake 的第一个步骤,交换 SSH 版本这步。
- // Sends and receives a version line. The versionLine string should
- // be US ASCII, start with "SSH-2.0-", and should not include a
- // newline. exchangeVersions returns the other side's version line.
- func exchangeVersions(rw io.ReadWriter, versionLine []byte) (them []byte, err error) {
- ...
- if _, err = rw.Write(append(versionLine, '\r', '\n')); err != nil {
- return
- }
- them, err = readVersion(rw)
- return them, err
- }
- // maxVersionStringBytes is the maximum number of bytes that we'll
- // accept as a version string. RFC 4253 section 4.2 limits this at 255
- // chars
- const maxVersionStringBytes = 255
- // Read version string as specified by RFC 4253, section 4.2.
- func readVersion(r io.Reader) ([]byte, error) {
- versionString := make([]byte, 0, 64)
- var ok bool
- var buf [1]byte
- for length := 0; length < maxVersionStringBytes; length++ {
- _, err := io.ReadFull(r, buf[:]) // 阻塞在这里
- if err != nil {
- return nil, err
- }
- ...
- }
- ...
- return versionString, nil
- }
看逻辑是在给对端发送完自己的版本信息后,等待对端回复,但是一直没有收到回复。但是为什么会没回复,为什么没有超时,刚开始看到这里的我是懵逼的。我只能想到既然这些都阻塞在等待对端回复上,那么一定有对应的连接存在,我先看看机器上的连接有什么问题。
TCP 连接的半打开状态 (TCP half-open)
在机器上执行了一下 netstat 命令看了下连接数。
- # netstat -anp|grep :36000|awk '{print $6}'|sort|uniq -c
- 2110 ESTABLISHED
- 1 LISTEN
- 41 TIME_WAIT
有大量处于 ESTABLISHED 的进程,数量和 goroutine 数能大致对上。先把注意力放到这些连接上,选其中一两个看看有什么问题吧。
接着便发现,有些连接,在本机有 6 个连接:
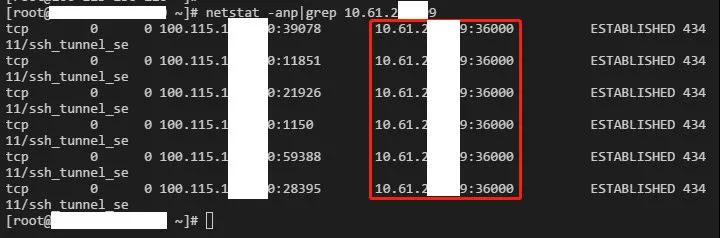
但是,对端一个也没有(图上那一个连接是我登录到目标机器的 ssh 连接):

google 查了下,发现这种情况属于 TCP 半打开状态,出现这种情况应该是建立连接后对端挂掉了或者其他网络无法连通的原因,而连接又没有启动 KeepAlive,导致一端无法发现这种情况,继续显示 ESTABLISHED 的连接,而另一端在机器挂掉重新启动后便不存在这条链接了。现在要确认一下是否真的没用启用 KeepAlive:
- # ss -aeon|grep :36000|grep -v time|wc -l
- 2110
全部没开……这里不带 KeepAlive 的连接数和上面 netstat 显示出来状态为 ESTABLISHED 状态的连接数一致,实际上在执行这两条命令的间隙肯定有新请求进来,这两个数字对上不能说完全匹配,只能说大多数是没有开启的。这里能 Get 到点就行。
再看一下 ssh.Dial 的逻辑,建立连接用的是 net.DialTimeout,而现网发生泄漏的版本是用 go1.9.2 编译的,这个版本的 net.DialTimeout 返回的 net.Conn 结构体的 KeepAlive 是默认关闭的(go1.9.2/net/client.go )。
golang.org/x/crypto/ssh 包在调用 net.DialTimeout 时不会显式启用 KeepAlive,完全依赖于当前 go 版本的默认行为。在最新版的 go 里面已经把建立 TCP 连接时启动 KeepAlive 作为默认行为了,于是这里我把代码迁移到 go1.13.3 重新编译了一次发到现网了,以为问题就尘埃落定了。
SSH 握手阻塞 (SSH Handshake hang)
实际上不是的。用 go1.13.3 编译的版本,运行一段时间后,用 pprof 看 goroutine 情况,还是存在不少处于 IO wait 状态的,并且看调用栈还是原来的味道(SSH handshake 时交换版本信息)。再看一下机器上的连接情况:
- # netstat -anp|grep :36000|awk '{print $6}'|sort|uniq -c
- 81 ESTABLISHED
- 1 LISTEN
- 1 SYN_SENT
- 23 TIME_WAIT
- # ss -aeon|grep :36000|grep time|wc -l
- 110
- # ss -aeon|grep :36000|grep -v time|wc -l
- 1
- # ss -aeon|grep :36000|grep -v time
- LISTEN 0 128 100.107.1x.x6:36000 *:* ino:2508898466 s
不带 KeepAlive 那个连接是本机监听 36000 端口的 sshd,其他都带上了,那没什么问题。说明这些阻塞住的应该不是因为 TCP 半打开导致阻塞的,选其中一个 IP 出来看看。
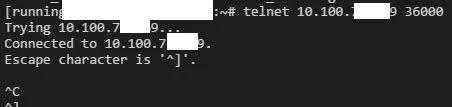
用 telnet 可以连上,但是无法断开连接。说明 TCP 连接是可以建立的,对端却因为一些不可知的原因不响应。再看看这个 IP 的连接存在多久了
- # netstat -atnp|grep 10.100.7x.x9
- tcp 0 0 100.107.1x.x6:8851 10.100.7x.x9:36000 ESTABLISHED 33027/ssh_tunnel_se
- # lsof -p 33027|grep 10.100.7x.x9
- ssh_tunne 33027 mqq 16u IPv4 3069826111 0t0 TCP 100-107-1x-x6:8504->10.100.7x.x9:36000 (ESTABLISHED)
- # ls -l /proc/33027/fd/16
- lrwx------ 1 mqq mqq 64 Dec 23 15:44 /proc/33027/fd/16 -> socket:[3069826111]
执行这个命令的时间是 24 日 17 时 25 分,已经阻塞一天多了。那这里的问题就是应用层没有超时控制导致的。再回过去看 ssh.Dial 的逻辑,Timeout 参数在 SSH handshake 的时候并没有作为超时控制的参数使用。net.Conn 的 IO 等待在 Linux 下是用非阻塞 epoll_pwait 实现的,进入等待的 goroutine 会被挂起直到有事件进来,超时是通过设置 timer 唤醒 goroutine 进行处理的,暴露出来的接口便是 net.Conn 的 SetDeadline 方法,于是重写了 ssh.Dial 的逻辑,给 SSH
handshake 阶段添加超时:
- // DialTimeout starts a client connection to the given SSH server. Differ from
- // ssh.Dial function, this function will be timeout when doing SSH handshake.
- // total timeout = ( 1 + timeFactor ) * config.Timeout
- // refs: https://github.com/cybozu-go/cke/pull/81/files
- func DialTimeout(network, addr string, config *ssh.ClientConfig) (*ssh.Client, error) {
- conn, err := net.DialTimeout(network, addr, config.Timeout)
- if err != nil {
- return nil, err
- }
- // set timeout for connection
- timeFactor := time.Duration(3)
- err = conn.SetDeadline(time.Now().Add(config.Timeout * timeFactor))
- if err != nil {
- conn.Close()
- return nil, err
- }
- // do SSH handshake
- c, chans, reqs, err := ssh.NewClientConn(conn, addr, config)
- if err != nil {
- return nil, err
- }
- // cancel connection read/write timeout
- err = conn.SetDeadline(time.Time{})
- if err != nil {
- conn.Close()
- return nil, err
- }
- return ssh.NewClient(c, chans, reqs), nil
- }
用这个函数替换了 ssh.Dial 后,编译上线,看下连接情况,恢复正常了。(恢复到一个小服务应该有的样子)
- # netstat -anp|grep :36000|awk '{print $6}'|sort|uniq -c
- 3 ESTABLISHED
- 1 LISTEN
- 86 TIME_WAIT
到这里会发现,其实本文解决的问题是对端如果出现各种异常了,如何及时关闭连接,而不是去解决对端的异常问题。毕竟 SSH 都异常了,谁还能上去查问题呢。现网服务器数量巨大,运行情况各不相同,因此出现异常也属情理之中,一一解决不太现实。
结尾
刚开始发现泄漏的时候到机器上 top 看了下,当时被 50G 的 VIRT 占用给吓着了,在咨询了组内大佬(zorro)的后,实际上这个值大多数时候都不用关心,只需关心 RES 占用即可。因为 RES 是实际占用的物理内存。
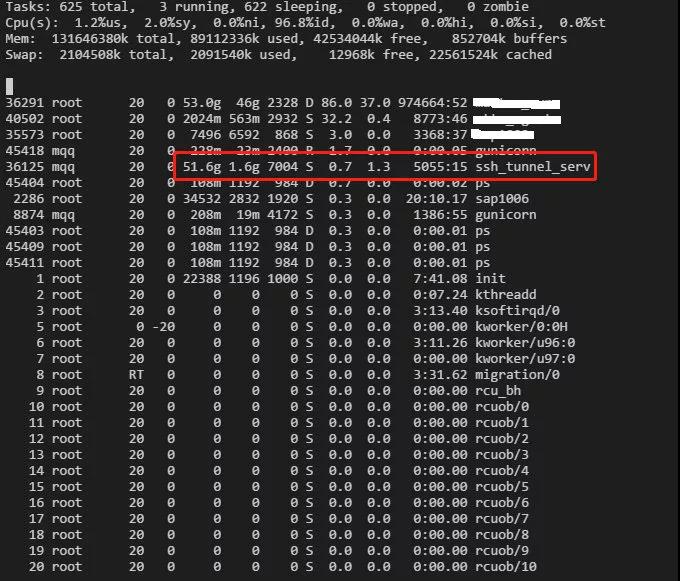
只看这一个时间点的 VIRT 和 RES 也是看不出到底有多少是泄漏的。只能和不同的时间点的内存占用对比,比如解决问题以后的版本,运行了三四天的情况下,VIRT 占用是 3.9G,而 RES 只占用了 16M。这样比下来看,还是释放了不少内存。或者说可以见得泄漏的那些 goroutine 占据了多少内存。
在 golang 中创建 goroutine 是一件很容易的事情,但是不合理的使用可能会导致大量 goroutine 无法结束,资源也无法被释放,随着时间推移造成了内存的泄漏。
避免 goroutine 泄漏的关键是要合理管理 goroutine 的生命周期,通过 prometheus/client_golang 导出 runtime 指标和利用 net/http/pprof 可以发现和解决 goroutine 泄漏问题。
【本文为51CTO专栏作者“腾讯技术工程”原创稿件,转载请联系原作者(微信号:Tencent_TEG)】