了解更多数字化转型方案查看此链接:
https://www.dellemc-solution.com/home/index.html
古今中外
提起考试
总有那么一个未解之谜
为什么Ta上课睡觉
下课玩耍
每次考试都说发挥不好
却能回回拿第一!?
在最近A企业第一届深度学习班的摸底考试中
同样的疑问也飘在蔡工头顶...
成绩出来了,他的性能结果差别人一大截,瞅着人群中笑得灿烂的林工,蔡工白眼频飞,一脸的羡慕嫉妒恨。
蔡工不理解,也不服气,他拿着成绩单来到技术主管Tony面前,把疑问悉数倒出。
Tony听完,调出蔡工、林工的卷子,捻起胡须细细分析起来:
① 这次图片类别的深度学习项目中,你的训练时间比林工长,数据量也比林工大,而且经过了多次devset评估调优,因此这几项,可以从你二人性能差别的原因中排除了;
② 框架和软件架构方面,你和林工的基本一致,所以问题也不在这儿;
③剩下的就是硬件方面了。GPU选择上,林工用的是Tesla P100,你用的GPU型号是GeForce GTX1080ti;服务器方面,林工用的PowerEdge T640,而你也并未选择T640。因此最终项目性能差别悬殊,原因可能就在硬件上。
蔡工摸摸头不好意思地开口:“当初出于预算考虑,没有选择Tesla P100+PowerEdge T640的配置,但是服务器参数、CPU、内存、硬盘这些都是一样的。GPU方面,GeForce GTX1080ti相比Tesla P100性能也许差点,但价格便宜,想着为此牺牲点训练时间也是可以接受的。”
Tony放下卷子,说道:“区别大着呢!对这个深度学习项目,Tesla P100+T640的硬件平台是经过应用和戴尔易安信验证通过,难怪最终结果差很多!”
蔡工这才有点拨云见日的感觉,继续发问:“GPU和服务器是怎么影响这次项目结果呢?”
Tony:“来,我给你分析分析。”
GPU影响知多少
一、应用
首先,从应用角度出发,了解应用是需要使用双精度FP64、单精度FP32,还是混合精度FP32&FP16——这是重要的一点,毕竟使用GPU根本的目的,是加速训练模型,让企业快速应用这海量数据的价值。
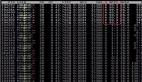
P.s IEEE754标准定义了半精度、单精度、双精度的概念,单精度的浮点数中采用4个字节也就是32位二进制来表达一个数字,双精度浮点数采用8个字节即64bits来表达,半精度浮点数就是采用16bits了,采用不同位数的浮点数的表达精度不一样,造成的计算误差也不一样。一般而言,需要处理数字范围大且需精确运算的科学计算,要求采用双精度浮点数。随着要求精度降低,单精度浮点数或者半精度浮点数也够用了。
如果是深度学习训练,不做超算类别的应用,一般使用的是混合精度即FP32与FP16。这次的项目是图片类别的深度学习训练,因此要采用混合精度训练模式。
在目前主流的Pascal GPU架构中,只有Tesla P100采用了单精度计算单元和双精度计算单元为2:1的比例设计,其他核心采用的都是32:1的设计。如果转化为双精度数值,可以通过以下公式简单计算——双精度理论峰值=FP64Cores*GPUBoost Clock*2,计算得出:
P100 5.3TFlops
V100 7.8TFlops
GTX1080ti 0.35TFlops
可见,Tesla P100双精度浮点数是GTX1080Ti的16倍!这也就是林工使用P100的训练周期比蔡工使用GTX1080ti缩短了很多的原因。(当然现在很有挑战的是新的GeForce显卡也支持混合精度,如果仅仅在训练时间上看P100,V100不会有几倍性能RTX2080的提升了,不过Tesla系列还有很多专业深度学习GPU特性优越于GeForce系列)。
二、ECC内存检验和纠正
GeForce系列GPU是没有ECC内存检验和纠正的,简单来说,如果Geforce显卡用来运行游戏,内存错误不会造成严重问题,只是画面显示有些许错误,可以忽略。
但就深度学习而言,所有训练都非常依赖GPU返回数据的准确性,特别是大量数据分析汇总。如果内存出现多次错误,就可能使计算结果出现误差,甚至导致整个大数据分析的不准确——这也很可能是蔡工Test set评估完整模型性能不理想的原因之一。
相比之下,Tesla P100就不一样了。Tesla系列具备ECC校验功能,能够发现并纠正L1/L2缓存或者现存错误,极好地保证计算结果的准确性,避免了因GPU内存错误导致模型性能不理想问题。
三、集群GPU
未来随着数据量增加,为了更好地获取性能加速,项目通常会采用集群GPU加速深度学习周期。
但是GeForce只支持单机P2P GPUDirect,不能支持跨主机的GPU RDMA,而Tesla与之相反,可以支持跨主机的GPU RDMA。
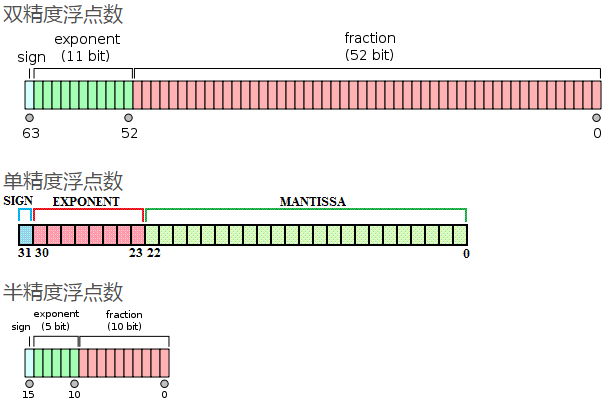
经实验室测定,在GPU集群计算环境中,即使是同样的Tesla GPU卡,采用GPU RDMA会比不使用RDMA仅使用TCP的性能提升2.5倍;而且相比单个GPU,使用RDMA基本可以获得高达30.6倍线性加速。所以长远考虑,同样建议在开始就选择合理的硬件配置。
四、易用性和管理型
从GPU和易用性和管理性来看,NVIDIA提供了NGC容器平台,NGC容器可接入Nvidia优化的深度学习软件、HPC应用、Nvidia HPC可视化工具等。通过NGC容器平台,开发人员可以免费访问深度学习容器,包括Caffe、Caffe2、CNTK、MXNet、TensorFlow、Theano、Torch等。
而戴尔易安信PowerEdge服务器+Tesla组合经过了Nvidia NGC认证,可以直接将NGC接入服务器中,所有这些工具都是预先集成、经过测试,并且专门为Nvidia GPU优化的,大大缩减了产品开发以及业务部署的时间。
此外,许多健康工具和GPU管理功能仅为Tesla GPU提供支持。如通过IMPI监控GPU健康状态、调整风扇速度以获得适当的冷却、遇到高温等及时发送报警、保证设备持续稳定运行等等。当然还有更多细节,如Tesla比GeForce在GPU内存容量、操作系统支持、应用软件支持、电源能效等方面有更好的表现等等,这里就不一一展开了。
服务器效用有多大
结合深度学习项目需求,基于快速应用、24小时不间断高性能运行、未来集群扩展性管理型的三大考量,戴尔易安信推荐了Tesla P100+PowerEdge T640组合。

对于新的深度学习项目架构,TeslaP100+PowerEdgeT640已经得到了英伟达NGC认证,可以快速接入深度学习框架,大大缩减产品开发以及业务部署的时间。而单台PowerEdgeT640服务器至多可支持4块P100或者V100,足以满足项目初始需求,并且未来升级集群时可以使用RDMA等技术保证性能的线性增长。
关于GPU服务器是否能稳定运行,问题就在散热方面。
那么,为什么PowerEdge T640可以保证GPU在高负载情况下依然持续稳定运行呢?
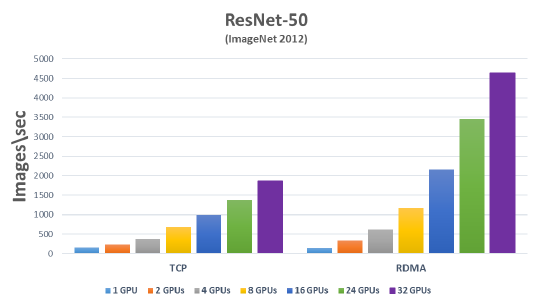
原因是PowerEdge T640专门对GPU机箱做了以下几方面的专业设计:
1
专门为多GPU优化设计了导风罩,多GPU卡专业散热,对气流的规划更为科学高效;


2
针对GPU设计专用风扇,并为GPU卡设计外置散热风扇,保证GPU长期高负载工作场景下更低的温度;
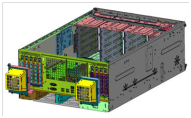
3
特别设计了GPU前中后三段式固定,减轻了GPU卡重量对主板的影响,从各方面提高系统的稳定性,保证机器在高负载下不间断稳定运行。

当然,对于超大型的深度学习架构底层,或者想要单台部署超过8GPU,服务器上可以选择戴尔易安信DSS8440——至多单台支持到10个V100的GPU,效用更为明显。

“同样的深度学习项目,硬件配置有差别,好比考场上人家拿了自动替芯涂卡笔,而你是中华2B美术笔,人答题卡涂完了,你的铅笔还没削好,这可不就落下了。这么一分析,你觉得呢?”Tony微笑看向蔡工。
蔡工:“原来如此,学霸成绩好不一定是脑子比我们好,而是在于有方法。原本我想靠“努力”来弥补,但忽视了“方法”,所以再怎么追赶,也成不了另一个学霸。”
“
如同GTX1080ti对比Tesla P100
看似性能差距不大
但两者的不同在于
是否经过应用和
戴尔易安信的验证通过
所以导致了失之毫厘,谬以千里的差距
因此,在人工智能
’军备竞赛‘的这条道路上
你需要选择戴尔易安信DSS8440
这样’方法‘与’实力‘兼备的产品助您成为人工智能行业的新一代
学霸
相关内容推荐:小编化身“李佳琦”前来带货啦
相关产品:PowerEdge T640塔式服务器