












还有几天,我们就要和2019年说再见了。今年是AI从梦想变为现实的一年,从NLP到自动驾驶,从人脸识别到数据模拟,有哪些技术突破面世,又遭遇了哪些新的困难?吴恩达的Deeplearning.ai梳理了今年AI最重要领域内的六大标志性事件和趋势。
2019年已经走过了98%,再过几天,20后就要诞生了!
这一年注定是充满了里程碑的一年。它将大众从《西部世界》、《终结者》等好莱坞科幻电影不切实际的虚幻场景中抽离出来,让人们认识到,AI其实是世界上的有形力量而非梦幻,从而开始认真讨论AI对社会,经济,政治和国际力量平衡的影响。
本文回顾了语言模型成绩斐然、人脸识别遭遇阻碍、自动驾驶迟迟未实现、DeepFake进入主流等等AI领域的发展现状:有哪些技术突破面世,又遭遇了哪些新的困难?一起跟随吴恩达的Deeplearning.ai,来看今年AI最重要领域内的六大标志性事件和趋势。
自动驾驶:在寒冬中孕育希望
就在几年前,一些汽车公司还在承诺,最早在2017年就可推出可上路的自动驾驶汽车。不过,今年1月《华尔街日报》报道,Waymo首席执行官约翰·克拉夫奇克(John Krafcik)表示,自动驾驶汽车可能永远无法在全路况条件下行驶。他的这一表态也成为2019年汽车行业的大裁员定下了基调。
自动驾驶在2019年遭遇瓶颈,几家在自动驾驶领域活跃的公司的商业化扩展的速度明显放缓。GM Cruise和特斯拉已经将自家旗下的自动驾驶出租车的最后期限推迟到2020年。
对于Waymo和Lyft而言,尽管美国凤凰城监管部门在2018年就已允许这两家公司开展自动驾驶出租车的运营业务,但到目前为止,这项服务仅在少数有限地区开展,愿意选择这项服务的人群也是寥寥无几。商用业务进展不顺,今年11月,Waymo宣布关闭在德州奥斯汀的自动驾驶汽车研发机构。
从技术上看,城市中道路的实时驾驶环境比路测更复杂,可能出现的极端危险情况也明显增多。但如此多的极端情况,能实际出现的几率却很低,这就造成了一个麻烦,工程师们可能无法获得足够的模拟数据再现这些情况。目前来看,一些行驶路线相对固定,可预测性较高的车辆,比如自动驾驶公交车、货车等,这些车可能比私家车和出租车更有希望尝到自动驾驶技术落地的真正甜头。
从成本上看,传感器(尤其是激光雷达)成本居高不下,而且供应量吃紧,汽车企业成本控制,更多地选择自己尝试制造这些设备,同时势必对车辆上的传感器数量进行缩减,而传感器数量的减少意味着训练和认知数据量的下降,如果传感器的性能提升速度无法弥补这个下降,威胁到的将是自动驾驶技术的重中之重——安全性。
从市场环境上看,2019年是全球汽车企业大裁员的一年。在全球经济下行、新车需求减少的背景下,日美欧各大车企先后宣布了大裁员计划。据不完全统计,全球每三家汽车公司中就有一家正在裁员。自动驾驶是个烧钱的行业,新技术的研发离不开传统车企的技术和资金支持,目前这个环境下,过去的富爸爸们也显得捉襟见肘了。
当然,也不是没有好消息,中国就正在尝试另一种思路。不再训练自动驾驶汽车在现有的城市环境中进行导航,而是对现有城市进行数字化改造,以适应并促进自动驾驶技术的发展。这被称为“智能城市”建设,包括路边传感器设备的完善,这些传感器会根据导航提示(例如车道变化和限速牌)传递更丰富的道路信息。
总体来看,2019年是自动驾驶行业内划分进一步细化的一年,技术瓶颈和资金紧缩让企业无法维系大而全的业务线,转而专攻一个个自己擅长的专门领域。
传统汽车制造商,比如福特和梅赛德斯,将重点放在了辅助驾驶功能上,背靠谷歌的Waymo则继续致力于全自动驾驶汽车,一些小公司则努力在有限场景中部署全自动驾驶,这些公司的目标会随着时间的推移而不断扩展。
Deepfake:技术孕育的妖怪如何收服?
2018年底开始,一批能够生成高度还原图像的模型陆续诞生,如BigGAN和StyleGAN,前者可以生成ImageNet中发现的类的图像,后者能够生成姿势,发型和衣服等要素的逼真变化。
2019年,基于深度学习技术生成的“Deepfake”假视频开始泛滥,这些视频能够凭空制造根本不存在的名人或政治人物的演讲内容,这些逼真的视频让人们发出“技术无所不能”的赞叹,同时,也引发了更多的人对技术滥用和不可控的担忧,甚至是恐惧。
Deepfake的出现实现了“以假乱真”的合成技术从图像到视频的跨越
在Deepfake视频中,英国足球明星大卫·贝克汉姆(David Beckham)可以用9种语言传达抗疟疾信息。中国科技企业发布基于同样技术的应用ZAO,可以将视频中用户的脸换到流行的电影场景中的演员身上,让用户感觉就像是自己在演电影一样。
不过,与恶搞娱乐和公益相比,Deepfake更多地显示了技术的“阴暗獠牙”。利用Deepfake伪造的演讲视频已经对马来西亚和加蓬的政治丑闻产生影响。
据Deepfake检测软件的DeeptraceLabs的一份报告称,目前在线的Deepfake视频中有96%是非自愿拍摄的“换头”色情片,片中人的脸往往被换成了女性名人的脸。这已经超出了恶搞的范畴,触及违法的边缘。
“妖怪”已经从瓶中放出,我们应如何应对?科技企业和政府立法部门已经开始努力。Facebook宣布了开启一项总奖金高达1000万美元的竞赛,开发Deepfake假视频的自动检测技术。中国政府颁布了关于禁止传播虚假视频的相关规定。美国加州也通过了一项类似的法律,众议院则在考虑推动对抗Deepfake假视频的国家层面的立法。
这可能是一场旷日持久的“猫捉老鼠”的高科技比拼。南加州大学计算机科学教授黎颢表示,这场比拼中,当猫的一方前景可能并不乐观,尽管今天的Deepfake视频仍有明显特征,但一年之后,这些假视频和真视频可能就根本没有区别了。
人脸识别落地受挫,政府插手立法遏制
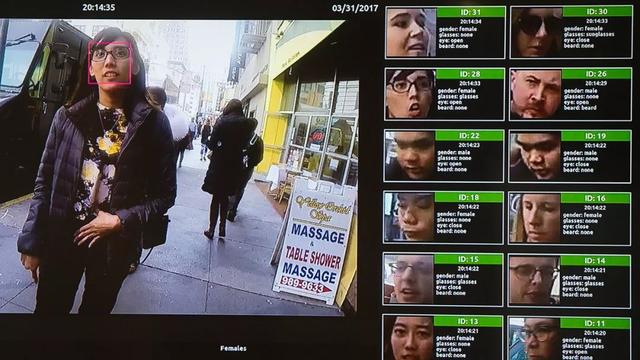
相比NLP领域的蓬勃发展,人脸识别却在前进路上遭遇到了严重的抵制。国际反监视情绪的推波助澜,阻碍了人脸识别系统的进一步泛滥。
公众出于对自身隐私、肖像被滥用的担忧,美国和欧洲的维权人士以及监督组织对人脸识别可能导致公民人身权利遭到潜在危害而深感忧虑,于是促使立法来限制该技术的使用。
他们的努力推动了国家禁止对该技术的公共和私人使用的势头,让刚刚崭露头角、准备大干一场的人脸识别大规模商用遭受当头一棒。
如今随着美国联邦政府对问题进行审议,美国多个城市通过了反面部识别法。而欧盟也正在努力制定自己的限制标准。下面我们回顾一下今年几起标志性的事件。
- 今年5月,旧金山成为美国第一个禁止警察和其他政府官员使用人脸识别的大城市;马萨诸塞州波士顿的萨默维尔地区则紧随其后。在接下来的几个月内,旧金山的邻居奥克兰和伯克利也通过了类似的法律。这些法律是由美国公民自由联盟牵头的,该联盟旨在促进国家立法。
- 在华盛顿,美国国会议员抨击了国土安全部对该机构在机场和边境使用该技术的计划。参议院和众议院的立法者提出了至少十二项法案,其中许多法案得到了两党的支持。这些法案旨在限制使用面部识别在压制人身,剥夺住房和创造利润方面的影响。
- 欧洲监管机构推动将面部图像分类为符合现有隐私法规的生物识别数据。欧盟委员会正在考虑立法来针对私人组织和公共机构“不加区别地使用”面部识别的行为。尽管如此,法国还是在10月准备了一项基于该技术的国家识别项目。
- 中国对人脸识别的使用在美国引起了反对,美国联邦贸易当局禁止向几家中国公司出口美国技术。
2016年,美国国家电信和信息管理局发布了人脸识别指南,要求公司保持透明,实行良好的数据管理并允许公众对与第三方共享人脸数据的某些控制权。尽管该技术的主要供应商是NTIA的成员,但尚不清楚他们是否遵守这些准则。
虽然立法限制使用人脸识别的初衷是为了保护公民的隐私,但不同的立场以及各自为政的作风,反而可能带来一些负面的效果。
今年6月份,亚马逊网络服务公司首席执行官Andy Jassy大吐苦水:“求求国会赶紧统一立法的吧,要不然我们将会面对的是:在美国50个州有50种不同的法律法规!”这样的混乱局面甚至可能让当地的执法部门都陷入困惑之中。
NLP飞跃,语言模型变得精通语言
早期由Word2Vec和GloVe embeddings支持的语言模型产生了令人困惑的聊天机器人、具有中学阅读理解能力的语法工具,以及勉强能看的翻译。但最新一代的语言模型变得如此之好,甚至有人认为它们很危险。
2019年自然语言处理领域发生了什么呢?一个新的语言模型生成了新闻文章,读者评价其和《纽约时报》一样可信;同样的语言模型还为《纽约客》的一篇文章做出了贡献。令人欣慰的是,这些模型没有像人们担忧的那样散布大量虚假信息。
2019年,研究人员在让机器理解自然语言方面取得了飞跃。通过对巨大的、未标记的数据集进行预训练,新模型通常可以熟练掌握自然语言。然后,他们通过在专门语料库上进行微调来掌握给定的任务或主题。

早期的模型如ULMFiT(由Jeremy Howard和Sebastian Ruder提出)和ELMo(来自艾伦人工智能研究所和华盛顿大学)展示了预训练的潜力,而谷歌的BERT是这种方法的第一个突破性的成功。BERT于2018年底发布,在GLUE阅读理解基准测试中得分之高,以至于测试的组织者首次将模型的表现与人类的baseline分数进行了比较。今年6月,微软的MT-DNN模型首次击败了人类。
今年2月中旬,OpenAI发布了GPT-2,一个预训练的通用语言模型,其创建者甚至认为它太过危险而不能发布,因为它有能力生成令人信服的文章。GPT-2使用40GB的Reddit评论进行了训练,并没有引发假新闻的大灾难,但确实为一部小说、一首前卫的歌词,以及《权力的游戏》的同人小说做出了贡献。OpenAI最终在11月发布了完整版本的模型。
在这期间,来自百度、卡内基梅隆大学、谷歌大脑、Facebook等其他机构的一系列模型依次超越了NLP基准。其中许多都基于transformer架构,并利用了BERT风格的双向编码。
新闻的背后:2018年7月,就在BERT诞生前不久,DeepMind研究员Sebastian Ruder预测了预训练对自然语言处理的影响。此外,他还预测,NLP的突破将彻底改变整个人工智能。他的论点基于2012年前后预训练对计算机视觉模型的激发。许多业内人士将深度学习的爆炸式增长追溯到这一刻。
现状:尽管经过了一年的创新,语言模型仍然有很大的增长空间:即使是1.5万亿参数的GPT-2也经常吐出一堆令人费解的文字。至于最新的模型是否有能力用铺天盖地的虚假信息扰乱民主,即将到来的美国选举季将检验这一点。
从《星际争霸II》到机器手解魔方:机器学习更多地依赖模拟数据
机器学习的未来可能更少地依赖于收集真实数据,而更多地依赖模拟环境。
有了足够的高质量数据,深度学习就像变魔术一样有效。但是,当样本很少的时候,研究人员就用模拟数据来填补空白。
2019年,在模拟环境中训练的模型完成了比该领域先前工作更复杂、更多样的壮举。在强化学习方面,DeepMind的AlphaStar在复杂战略游戏《星际争霸II》(StarCraft II)中取得了特级大师段位——能够打败99.8%的人类玩家。OpenAI Five训练了一个由5个神经网络组成的团队,打败了Dota 2的世界冠军。但这些模型在模拟世界学习,学会的是在模拟世界中行动。其他研究人员将AI在模拟中学习到的技能迁移到现实世界中。
OpenAI的Dactyl机械臂在虚拟环境中花费了相当于13000年的模拟时间,开发出操作魔方所需的灵活性。然后将这些技能应用到一个真实魔方上。当还原一个魔方需要15次以内的旋转时,它的成功率达到60%。当还原魔方需要更多次操作时,它的成功率下降到20%。
加州理工学院的研究人员训练了一个神经网络来区分重叠地震和同时发生的地震,方法是模拟横跨加州和日本的地震波,并将模拟结果作为训练数据。
亚马逊旗下的Aurora自动驾驶汽车部门同时进行数百次模拟,以训练其模型在城市环境中导航。该公司正在以类似的方式训练Alexa的对话能力、送货无人机和机器人。
模拟环境,诸如Facebook的AI Habitat,谷歌的强化学习行为套件,以及OpenAI的Gym,都可以为AI掌握任务提供资源,例如优化纺织生产线,填充3D图像中的空白点,以及在嘈杂的环境中检测对象。在不久的将来,模型可以探索分子模拟,以了解如何设计具有预期结果的药物。
冲突爆发:符号主义和连接主义的古老争论再燃
以Twitter为阵地,以加里·马库斯(Gary Marcus)为首的长达一年的争论,为围绕人工智能发展方向数十年的争论注入了新的活力。
马库斯是纽约大学教授、作家、企业家,以及基于逻辑的AI的鼓吹者,他发起了不懈的Twitter争论,试图打破深度学习的根基,并推广其他人工智能方法。
马库斯重新点燃了所谓的符号主义者和连接主义者之间的古老争论,前者坚持认为基于规则的算法对认知至关重要,而后者则认为将足够多的神经元与正确的损失函数连接起来是获得机器智能的最佳途径。
与马库斯针锋相对的AI从业者重新熟悉了象征主义的方法,以免连接主义的局限性导致资金崩溃,或人工智能陷入寒冬。这一争论促使人们对人工智能的未来做出了清醒的评估,并在12月23日由马库斯和深度学习先驱、蒙特利尔大学Yoshua Bengio教授的一场现场辩论中达到高潮。辩论过程非常有礼貌,双方都承认两个党派之间需要合作。
2018年12月,马库斯向深度学习支持者的“帝国主义”态度发起了挑战,开始了自己的进攻。他继而鞭策Facebook的深度学习先驱Yann LeCun,要他选择一方:是把自己的信仰寄托在纯粹的深度学习上,还是有好的“出色的老式人工智能”(good old-fashioned AI)的一席之地?
OpenAI在10月份提出的混合模型成为头条新闻。它的机械手通过深度强化学习和经典的Kociemba算法的结合解决了魔方难题。虽然马库斯指出是Kociemba算法计算出了解决方案,而不是深度学习,但其他人断言机器人可以通过进一步的训练来学习这项技能。
去年12月,微软提出“神经符号人工智能”(neurosymbolic AI),填补了这一空缺。这是一个旨在弥合神经表示和符号表示之间差距的模型架构。
随着2019年临近结束,NeurIPS会议强调了人工智能社区的soul searching。谷歌研究员Blaise Aguera y Arcas在一次主题演讲中表示:“我们目前所有的训练模式都是为了让AI在特定任务中取得胜利或者赢得高分,但这并不是智能的全部。”
符号主义者和连接主义者之间的敌意可以追溯到半个多世纪以前。1969年,马文·明斯基和西摩尔·派普特在《Perceptrons》书中,仔细分析了以感知机为代表的单层神经网络系统的功能及局限,证明感知机不能解决简单的异或(XOR)等线性不可分问题,帮助触发了第一个AI冬天。
第二个AI寒冬是在将近20年后,部分原因是符号AI依赖于LISP计算机,而LISP计算机已经随着PC的出现变得过时了。
神经网络在20世纪90年代开始普及,并在过去十年计算能力和数据的爆炸式增长中取得了主导地位。
当连接主义者和符号主义者齐头并进,或者直到一个派别消灭另一个派别时,我们期待着激动人心的新时代






















