北京时间2019年12月26日下午14点30分,联泰集群在北京正式发布了水晶系列工作站产品,本次“水晶工作站产品发布会”暨“联泰集群高性能计算解决方案研讨会”由英特尔®中国独家赞助,产品在提供强悍高算力的同时,又能保证温婉低噪的静音,刚柔并济。
现场请到了英特尔中国数据中心技术售前经理——拓庆国先生,带来最新的英特尔CPU架构和傲腾™技术加持的傲腾™增强型SSD讲解,以及清华大学——张宇飞教授使用联泰集群产品在科研方面的精彩案例分享。
发布会现场首先由拓总和张教授共同为水晶系列工作站揭幕,工作站产品在会场进行了点亮,完全不会影响发布会的正常进行,真正检验了工作站的静音属性,当得知水晶工作站处于点亮状态,在场的嘉宾纷纷侧目旁边的展台,完全没有察觉到如传统工作站的噪音存在。
之后由联泰集群硬件产品技术中心总监——刘振锋、软件产品技术中心总监——孙建军、硬件产品技术中心工程师——肖学文分别从应用方向、水晶工作站一体化软件平台及水晶系列产品硬件方面对本系列产品进行了详细的介绍。




入门级深度学习工作站W5232
在讨论这个问题之前我们需要理解为什么深度学习需要使用专业的工作站?
1. 深度学习需要大量的并行计算资源,而且动辄计算几天甚至数周,而显卡(GPU)恰好适合这种工作,提供几十上百倍的加速,性能强劲的GPU能在几个小时内完成原本CPU需要数月完成的任务,所以目前深度学习乃至于机器学习领域已经全面转向GPU架构,使用GPU完成训练任务
2. 如今即使使用GPU的深度学习任务也要持续数天乃至数月(取决于数据规模和深度学习网络模型),需要使用单独的设备保障保证训练任务能够7x24小时长期稳定运行。
3. 独立的深度学习工作站(服务器)可以方便实现实验室计算资源共享,多用户可以在个人电脑编写程序,远程访问到深度学习服务器上排队使用计算资源,减少购买设备的开支并且避免了在本地计算机配置复杂的软件环境。
深度学习工作站配置要求
深度学习任务对计算机的性能要求较高,各硬件主要完成以下操作。
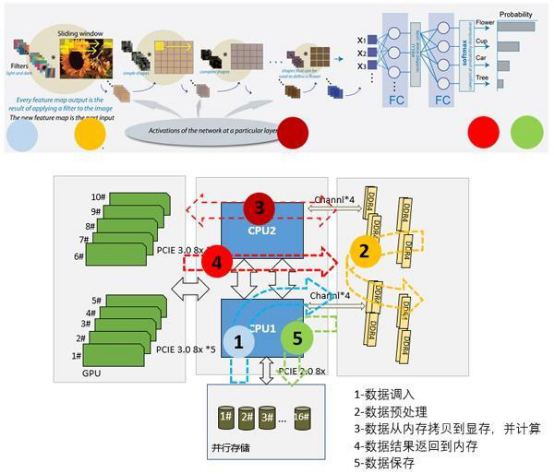
上述图示,深度神经网络计算大致流程,下面通过深度神经网络计算环节,分析核心硬件配置理想要求

CPU:因为主要使用显卡进行cuda计算,因此对CPU的要求并不是很高,频率越高、线程数越多越好,一般最低要求cpu核心数大于显卡个数。其中一个制约因素:cpu的最大PCI-E 通道数。每张显卡占用16条pcie通道才能达到最大性能,而单cpu最大支持48条pcie,也就是最多3条PCI-E x16接口, 但是受限主板的大小,只有选用专业的工作站板子才能充分发挥GPU卡的性能,而联泰的W5232工作站就是一个很好的选择。采用专用的双路工作站,不仅提升了CPU的处理能力,也能通过使用两张GPU卡来增加训练能力。
GPU卡:深度学习需要较强性能的显卡进行复杂的单精度运算,通常神经网络需要大量显存和内存资源,因此需要8GB以上显存才能运行大规模的深度卷积网络,执行计算机视觉任务,一般选择GTX1070以上配置。应该购买具有较大显存的显卡。下面给出2080ti、2080、2070、1080ti、1070、1060、Titan X、Titan V的几项指标的对比:
TFLOPS(teraFLOPS FLoating-point Operations Per Second每秒浮点运算次数)单精度也就是运算性能,决定了运算速度,首选1080ti、2080ti、Titan V,不过性能最强的titan V的价格是2080ti的三倍

VRAM (显存):显存大小决定了我们的网络模型能不能执行,大型的卷积神经网络会使用超过8G以上的显存,因此购买具有大显存的显卡才能够保证大多数卷积神经网络模型能够顺利执行。联泰的W5232工作站就是这种入门级深度学习的工作站,采用的是两颗二代Intel至强可扩展处理器,并且配备了64GB的内存,支持2张GPU加速卡,480G的SSD作为系统盘,4T的SATA盘作为数据盘,所以整个工作站的很高的,非常适合入门级深度学习。
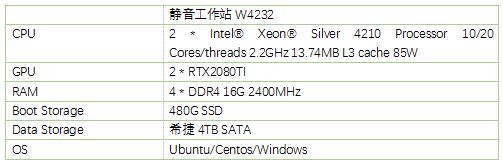
当然这款工作站配置那么高,也可进行其他的一些图像高分辨率,高清晰度的图像的输出,像再医院里面很多的各种CT等图片都是通过这种工作站进行扫描分辨出来的,特别是对于患者这种生理结构图的处理需要更加清晰的图像,因此需要更加强劲的图形处理能力。当然对于一些医疗行业里面的关于生命科学的基本的计算工作也是可以胜任的。

今后,联泰集群还将继续推出更多更新的产品,让我们一起感受科技前沿和创新变化。