













一、 Filnk简介和编程模型
Flink使用java语言开发,提供了scala编程的接口。使用java或者scala开发Flink是需要使用jdk8版本,如果使用Maven,maven版本需要使用3.0.4及以上。
Dataflows:
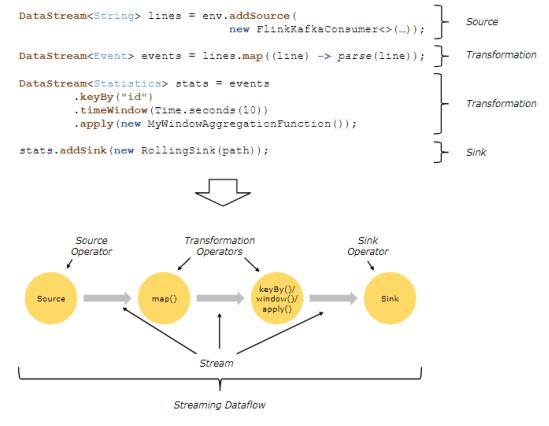
parallel Dataflows:
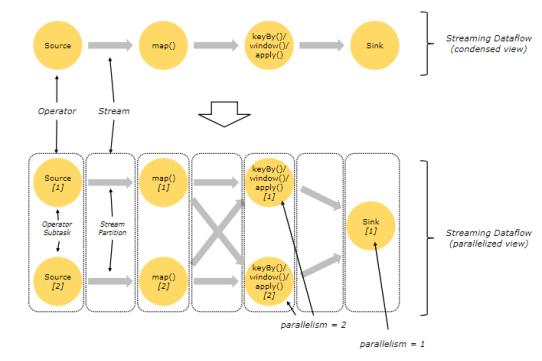
Task和算子链:
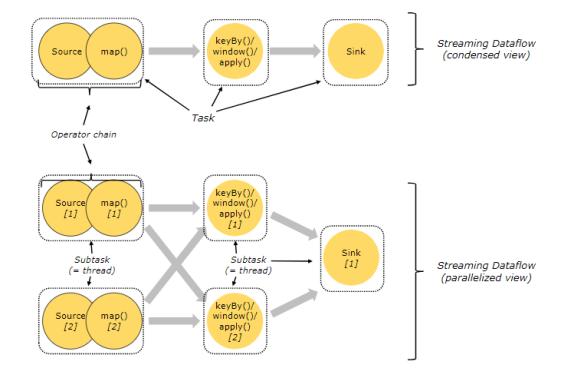
JobManager、TaskManager和clients:
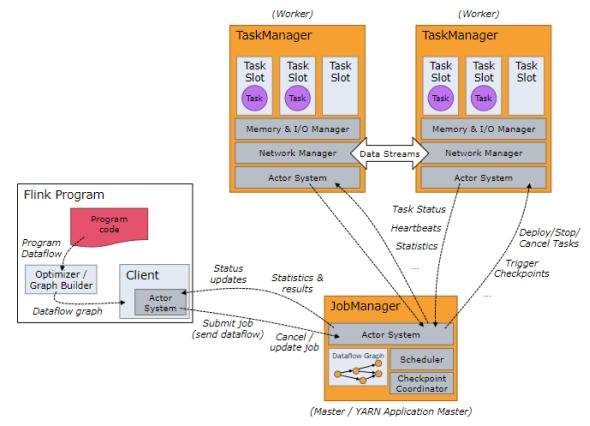
Flink运行时包含两种类型的进程:
- JobManger:也叫作masters,协调分布式执行,调度task,协调checkpoint,协调故障恢复。在Flink程序中至少有一个JobManager,高可用可以设置多个JobManager,其中一个是Leader,其他都是standby状态。
- TaskManager:也叫workers,执行dataflow生成的task,负责缓冲数据,及TaskManager之间的交换数据。Flink程序中必须有一个TaskManager.
Flink程序可以运行在standalone集群,Yarn或者Mesos资源调度框架中。
clients不是Flink程序运行时的一部分,作用是向JobManager准备和发送dataflow,之后,客户端可以断开连接或者保持连接。
TaskSlots 任务槽:
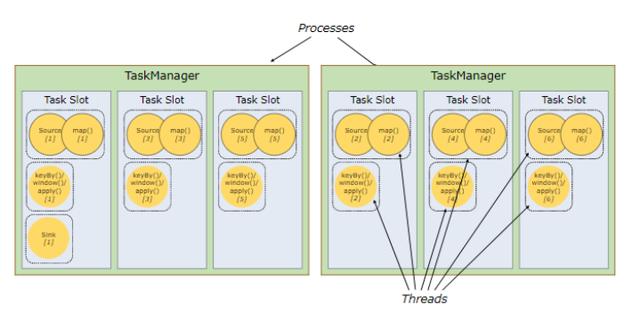
每个Worker(TaskManager)是一个JVM进程,可以执行一个或者多个task,这些task可以运行在任务槽上,每个worker上至少有一个任务槽。每个任务槽都有固定的资源,例如:TaskManager有三个TaskSlots,那么每个TaskSlot会将TaskMananger中的内存均分,即每个任务槽的内存是总内存的1/3。任务槽的作用就是分离任务的托管内存,不会发生cpu隔离。
通过调整任务槽的数据量,用户可以指定每个TaskManager有多少任务槽,更多的任务槽意味着更多的task可以共享同一个JVM,同一个JVM中的task共享TCP连接和心跳信息,共享数据集和数据结构,从而减少TaskManager中的task开销。
总结:task slot的个数代表TaskManager可以并行执行的task数。
二、 Flink 批处理
批处理WordCount:
ExecutionEnvironment env = ExecutionEnvironment.getExecutionEnvironment();
DataSource<String> ds = env.readTextFile("./data/words");
FlatMapOperator<String, String> flatMap = ds.flatMap(new FlatMapFunction<String, String>() {
@Override
public void flatMap(String s, Collector<String> collector) throws Exception {
String[] ssplit = s.split(" ");
for (String cs : split) {
collector.collect(cs);
}
}
});
MapOperator<String, Tuple2<String, Integer>> map = flatMap.map(new MapFunction<String, Tuple2<String, Integer>>() {
@Override
public Tuple2<String, Integer> map(String s) throws Exception {
return new Tuple2<String, Integer>(s, 1);
}
});
UnsortedGrouping<Tuple2<String, Integer>> groupBy = map.groupBy(0);
AggregateOperator<Tuple2<String, Integer>> sum = groupBy.sum(1);
// sum.print();//可以触发算子执行
//排序,目前不支持全局排序
SortPartitionOperator<Tuple2<String, Integer>> sort = sum.sortPartition(1, Order.DESCENDING).setParallelism(1);
sort.writeAsText("./TempResult/result").setParallelism(1);
env.execute("my-wordcount");
- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
- 9.
- 10.
- 11.
- 12.
- 13.
- 14.
- 15.
- 16.
- 17.
- 18.
- 19.
- 20.
- 21.
- 22.
- 23.
- 24.
三、 Flink 执行流程
数据源分为有界和无界之分,有界数据源可以编写批处理程序,无界数据源可以编写流式程序。DataSet API用于批处理,DataStream API用于流式处理。
批处理使用ExecutionEnvironment和DataSet,流式处理使用StreamingExecutionEnvironment和DataStream。
DataSet和DataStream是Flink中表示数据的特殊类,DataSet处理的数据是有界的,DataStream处理的数据是无界的,这两个类都是不可变的,一旦创建出来就无法添加或者删除数据元。
Flink程序的执行过程:
- 获取flink的执行环境(execution environment)
- 加载数据-- soure
- 对加载的数据进行转换 -- transformation
- 对结果进行保存或者打印 --sink
- 触发flink程序的执行(execute(),count(),collect(),print()),例如:调用ExecutionEnvironment或者StreamExecutionEnvironment的execute()方法。
四、 Flink standalone集群搭建
Flink可以在Linux和window中运行,Flink集群需要有一个Master节点和一个或者多个Worker节点组成。
安装Flink集群之前需要准备:1.每台几点需要配置jdk8环境变量。2.需要每台节点有ssh服务,且有免密通信。
步骤:
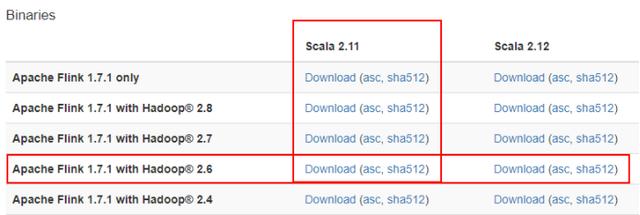
1. 进入https://flink.apache.org/downloads.html 下载flink.
下载Flink版本,这里选择了基于Scala2.11和Hadoop2.6的1.7.1版本.
2. 下载好Flink之后上传到Master(node1)节点上解压:
![]()
3. 进入../conf/flink-conf.yaml中配置:
- jobmanager.rpc.address: node1 设置Master节点地址
- jobmanager.heap.size: 1024m 设置Master使用的最大内存,单位是MB
- taskmanager.heap.size: 1024m 设置Worker使用的最大内存,单位是MB
4. 配置../conf/slaves ,配置Worker节点列表
![]()
5. 将配置好的Flink发送到其他worker节点(node2,node3)上。
![]()
6. 启动Flink集群,访问webui
在Master节点上,../bin/start-cluster.sh 启动集群。访问webui:http:node1:8081
7. 停止集群:在Master节点中../bin/stop-cluster.sh
五、 将Flink任务提交到standalone集群运行
将以上FlinkSocketWordCount 案例打包提交到集群中运行,无论在Master节点还是在Worker节点提交都可以。
首先需要在node5节点中启动socket 9999端口:
nc –lk 9999
- 1.
提交命令如下:
./flink run /root/test/MyFlink-1.0-SNAPSHOT-jar-with-dependencies.jar --port 9999
- 1.
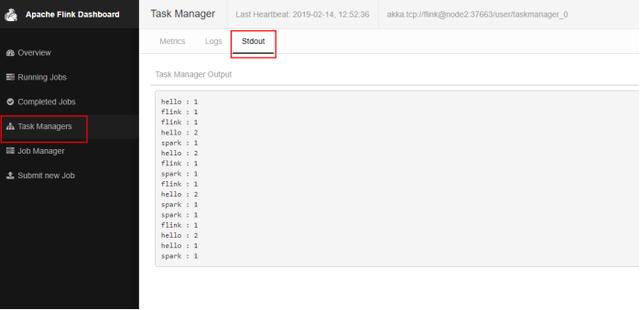
在node5节点上输入数据后在webUI中查看日志:
六、 Flink流处理
1. 读取Socket数据统计WordCount
public class SocketWindowWordCount {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env =
StreamExecutionEnvironment.getExecutionEnvironment();
DataStreamSource<String> socketStream = env.socketTextStream("node5", 9999);
SingleOutputStreamOperator<Tuple2<String, Integer>> pairWords =
socketStream.flatMap(new Splitter());
KeyedStream<Tuple2<String, Integer>, Tuple> keyBy = pairWords.keyBy(0);
WindowedStream<Tuple2<String, Integer>, Tuple, TimeWindow> windowStream =
keyBy.timeWindow(Time.seconds(5));
DataStream<Tuple2<String, Integer>> dataStream = windowStream.sum(1);
dataStream.print();
env.execute("socket wordcount");
}
//Splitter 实现了 FlatMapFunction ,将输入的一行数据按照空格进行切分,返回tuple<word,1>
public static class Splitter implements FlatMapFunction<String, Tuple2<String, Integer>> {
@Override
public void flatMap(String sentence, Collector<Tuple2<String, Integer>> out) throws Exception {
for (String word: sentence.split(" ")) {
out.collect(new Tuple2<String, Integer>(word, 1));
}
}
}
}
- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
- 9.
- 10.
- 11.
- 12.
- 13.
- 14.
- 15.
- 16.
- 17.
- 18.
- 19.
- 20.
- 21.
- 22.
- 23.
- 24.
2. 数据源Source
Source 是Flink获取数据的地方。以下source中和批处理的source类似,但是以下源作为dataStream流处理时,是一条条处理,最终得到的不是一个总结果,而是每次处理后都会得到一个结果。
- socketTextStream – 读取Socket数据流
- readTextFile() -- 逐行读取文本文件获取数据流,每行都返回字符串。
- fromCollection() – 从集合中创建数据流。
- fromElements – 从给定的数据对象创建数据流,所有数据类型要一致。
- addSource – 添加新的源函数,例如从kafka中读取数据,参见读取kafka数据案例。
3. 数据写出 Sink
- writeAsText() – 以字符串的形式逐行写入文件,调用每个元素的toString()得到写入的字符串。
- writeAsCsv() – 将元组写出以逗号分隔的csv文件。注意:只能作用到元组数据上。
- print() – 控制台直接输出结果,调用对象的toString()方法得到输出结果。
- addSink() – 自定义接收函数。例如将结果保存到kafka中,参见kafka案例。
七、 Flink读取Socket数据WordCount案例
1. 创建maven项目
2. 导入maven依赖
flink1.7.1 使用jdk1.8,scala2.11或者2.12.这里使用的scala2.11.如果只是使用java开发flink,Scala的版本选择多少都可以。如果使用Scala开发那么就必须使用Scala对应的版本。
<properties>
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
<maven.compiler.source>1.8</maven.compiler.source>
<maven.compiler.target>1.8</maven.compiler.target>
<flink.version>1.7.1</flink.version>
</properties>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-java</artifactId>
<version>${flink.version}</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-streaming-java_2.11</artifactId>
<version>${flink.version}</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-clients_2.11</artifactId>
<version>${flink.version}</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-connector-wikiedits_2.11</artifactId>
<version>${flink.version}</version>
</dependency>
- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
- 9.
- 10.
- 11.
- 12.
- 13.
- 14.
- 15.
- 16.
- 17.
- 18.
- 19.
- 20.
- 21.
- 22.
- 23.
- 24.
- 25.
- 26.
- 27.
3. 创建StreamExecutionEnvironment 或者ExecutionEnvironment(批处理作业)。用于设置执行参数并创建从外部系统读取的源。
代码如下:
public class FlinkSocketWordCount {
public static void main(String[] args) throws Exception {
final int port ;
try{
final ParameterTool params = ParameterTool.fromArgs(args);
port = params.getInt("port");
}catch (Exception e){
System.err.println("No port specified. Please run 'FlinkSocketWordCount --port <port>'");
return;
}
//获取执行环境
final StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
//从socket中获取数据。
DataStreamSource<String> text = env.socketTextStream("node5", port);
SingleOutputStreamOperator<WordWithCount> wordWithCountInfos = text.flatMap(new FlatMapFunction<String, WordWithCount>() {
@Override
public void flatMap(String line, Collector<WordWithCount> collector) throws Exception {
for (String word : line.split(" ")) {
collector.collect(new WordWithCount(word, 1L));
}
}
});
//keyBy中所写的字段必须是类WordWithCount中的字段,WordWithCount中如果重写构造必须写上无参构造
KeyedStream<WordWithCount, Tuple> keyedInfos = wordWithCountInfos.keyBy("word");
WindowedStream<WordWithCount, Tuple, TimeWindow> windowedInfo = keyedInfos.timeWindow(Time.seconds(5), Time.seconds(1));
SingleOutputStreamOperator<WordWithCount> windowCounts = windowedInfo.reduce(new ReduceFunction<WordWithCount>() {
@Override
public WordWithCount reduce(WordWithCount w1, WordWithCount w2) throws Exception {
return new WordWithCount(w1.getWord(), w1.getCount() + w2.getCount());
}
});
windowCounts.print();
env.execute("Socket Window WordCount");
}
public static class WordWithCount {
public String word;
public Long count;
public WordWithCount() { }
public WordWithCount(String word, Long count) {
this.word = word;
this.count = count;
}
public String getWord() {
return word;
}
public void setWord(String word) {
this.word = word;
}
public Long getCount() {
return count;
}
public void setCount(Long count) {
this.count = count;
}
@Override
public String toString() {
return word + " : " + count;
}
}
}
- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
- 9.
- 10.
- 11.
- 12.
- 13.
- 14.
- 15.
- 16.
- 17.
- 18.
- 19.
- 20.
- 21.
- 22.
- 23.
- 24.
- 25.
- 26.
- 27.
- 28.
- 29.
- 30.
- 31.
- 32.
- 33.
- 34.
- 35.
- 36.
- 37.
- 38.
- 39.
- 40.
- 41.
- 42.
- 43.
- 44.
- 45.
- 46.
- 47.
- 48.
- 49.
- 50.
- 51.
- 52.
- 53.
- 54.
- 55.
- 56.
- 57.
- 58.
- 59.
- 60.
八、 如何指定keys
比如某些算子(join,coGroup,keyBy,groupB y)要求在数据元上定义key。另外有些算子操作(reduce,groupReduce,Aggregate,Windows)允许数据在处理之前根据key进行分组。在Flink中数据模型不是基于Key,Value格式处理的,因此不需将数据处理成键值对的格式,key是“虚拟的”,可以人为的来指定,实际数据处理过程中根据指定的key来对数据进行分组,DataSet中使用groupBy来指定key,DataStream中使用keyBy来指定key。如何指定keys?
1. 使用Tuples来指定key
定义元组来指定key可以指定tuple中的第几个元素当做key,或者指定tuple中的联合元素当做key。需要使用org.apache.flink.api.java.tuple.TupleXX包下的tuple,最多支持25个元素且Tuple必须new创建。如果Tuple是嵌套的格式,例如:DataStream
2. 使用Field Expression来指定key
可以使用Field Expression来指定key,一般作用的对象可以是类对象,或者嵌套的Tuple格式的数据。
使用注意点:
(1) 对于类对象可以使用类中的字段来指定key。
类对象定义需要注意:
- 类的访问级别必须是public
- 必须写出默认的空的构造函数
- 类中所有的字段必须是public的或者必须有getter,setter方法。例如类中有个字段是foo,那么这个字段的getter,setter方法为:getFoo() 和 setFoo().
- Flink必须支持字段的类型。一般类型都支持
(2) 对于嵌套的Tuple类型的Tuple数据可以使用”xx.f0”表示嵌套tuple中第一个元素,也可以直接使用”xx.0”来表示第一个元素,参照案例GroupByUseFieldExpressions。
3. 使用Key Selector Functions来指定key
使用key Selector这种方式选择key,非常方便,可以从数据类型中指定想要的key.
九、 累加器(Accumulator)和计数器(Counter)
Accumulator即累加器,可以在分布式统计数据,只有在任务结束之后才能获取累加器的最终结果。计数器是累加器的具体实现,有:IntCounter,LongCounter和DoubleCounter。
累加器注意事项:
- 需要在算子内部创建累加器对象
- 通常在Rich函数中的open方法中注册累加器,指定累加器的名称
- 在当前算子内任意位置可以使用累加器
- 必须当任务执行结束后,通过env.execute(xxx)执行后的JobExecutionResult对象获取累加器的值。
IntCounter举例:
ExecutionEnvironment env = ExecutionEnvironment.getExecutionEnvironment();
DataSource<String> dataSource = env.fromElements("a", "b", "c", "d", "e", "f");
MapOperator<String, String> map = dataSource.map(new RichMapFunction<String, String>() {
//1.创建累加器,在算子中创建累加器对象
private IntCounter numLines = new IntCounter();
//2.注册累加器对象,通常在Rich函数的open方法中使用
// getRuntimeContext().addAccumulator("num-lines", this.numLines);注册累加器
public void open(Configuration parameters) throws Exception {
getRuntimeContext().addAccumulator("num-lines", this.numLines);
}
@Override
public String map(String s) throws Exception {
//3.使用累加器 ,可以在任意操作中使用,包括在open或者close方法中
this.numLines.add(1);
return s;
}
}).setParallelism(8);
map.writeAsText("./TempResult/result",FileSystem.WriteMode.OVERWRITE);
JobExecutionResult myJobExecutionResult = env.execute("IntCounterTest");
//4.当作业执行完成之后,在JobExecutionResult对象中获取累加器的值。
int accumulatorResult = myJobExecutionResult.getAccumulatorResult("num-lines");
System.out.println("accumulator value = "+accumulatorResult);
- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
- 9.
- 10.
- 11.
- 12.
- 13.
- 14.
- 15.
- 16.
- 17.
- 18.
- 19.
- 20.
- 21.
- 22.
十、 Flink + kafka 整合使用
1. 在pom.xml中添加Flink Kafka连接器的依赖,如果添加了不要重复添加
<!-- Flink Kafka连接器的依赖-->
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-connector-kafka-0.11_2.11</artifactId>
<version>1.7.1</version>
</dependency>
- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
2. 从kafka中读取数据处理,并将结果打印到控制台
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
Properties props = new Properties();
props.setProperty("bootstrap.servers", "node1:9092,node2:9092,node3:9092");
props.setProperty("group.id", "flink-group");
/**
* 第一个参数是topic
* 第二个参数是value的反序列化格式
* 第三个参数是kafka配置
*/
FlinkKafkaConsumer011<String> consumer011 = new FlinkKafkaConsumer011<>("FlinkTopic", new SimpleStringSchema(), props);
DataStreamSource<String> stringDataStreamSource = env.addSource(consumer011);
SingleOutputStreamOperator<String> flatMap = stringDataStreamSource.flatMap(new FlatMapFunction<String, String>() {
@Override
public void flatMap(String s, Collector<String> outCollector) throws Exception {
String[] ssplit = s.split(" ");
for (String currentOne : split) {
outCollector.collect(currentOne);
}
}
});
//注意这里的tuple2需要使用org.apache.flink.api.java.tuple.Tuple2 这个包下的tuple2
SingleOutputStreamOperator<Tuple2<String, Integer>> map = flatMap.map(new MapFunction<String, Tuple2<String, Integer>>() {
@Override
public Tuple2<String, Integer> map(String word) throws Exception {
return new Tuple2<>(word, 1);
}
});
//keyby 将数据根据key 进行分区,保证相同的key分到一起,默认是按照hash 分区
KeyedStream<Tuple2<String, Integer>, Tuple> keyByResult = map.keyBy(0);
WindowedStream<Tuple2<String, Integer>, Tuple, TimeWindow> windowResult = keyByResult.timeWindow(Time.seconds(5));
SingleOutputStreamOperator<Tuple2<String, Integer>> endResult = windowResult.sum(1);
//sink 直接控制台打印
//执行flink程序,设置任务名称。console 控制台每行前面的数字代表当前数据是哪个并行线程计算得到的结果
endResult.print();
//最后要调用execute方法启动flink程序
env.execute("kafka word count");
- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
- 9.
- 10.
- 11.
- 12.
- 13.
- 14.
- 15.
- 16.
- 17.
- 18.
- 19.
- 20.
- 21.
- 22.
- 23.
- 24.
- 25.
- 26.
- 27.
- 28.
- 29.
- 30.
- 31.
- 32.
- 33.
- 34.
- 35.
- 36.
3. 将结果写入kafka
//sink 将结果存入kafka topic中,存入kafka中的是String类型,所有endResult需要做进一步的转换
FlinkKafkaProducer011<String> producer = new FlinkKafkaProducer011<>("node1:9092,node2:9092,node3:9092","FlinkResult",new SimpleStringSchema());
//将tuple2格式数据转换成String格式
endResult.map(new MapFunction<Tuple2<String,Integer>, String>() {
@Override
public String map(Tuple2<String, Integer> tp2) throws Exception {
return tp2.f0+"-"+tp2.f1;
}
}).addSink(producer);
- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
- 9.
4. 将结果写入文件
//sink 将结果存入文件,FileSystem.WriteMode.OVERWRITE 文件目录存在就覆盖
endResult.writeAsText("./result/kafkaresult",FileSystem.WriteMode.OVERWRITE);
// endResult.writeAsText("./result/kafkaresult",FileSystem.WriteMode.NO_OVERWRITE);
- 1.
- 2.
- 3.
十一、 Flink + Kafka 整合数据一致性保证
1. Flink消费kafka数据起始offset配置
Flink读取Kafka数据确定开始位置有以下几种设置方式:
(1) flinkKafkaConsumer.setStartFromEarliest()
从topic的最早offset位置开始处理数据,如果kafka中保存有消费者组的消费位置将被忽略。
(2) flinkKafkaConsumer.setStartFromLatest()
从topic的最新offset位置开始处理数据,如果kafka中保存有消费者组的消费位置将被忽略。
(3) flinkKafkaConsumer.setStartFromTimestamp(…)
从指定的时间戳(毫秒)开始消费数据,Kafka中每个分区中数据大于等于设置的时间戳的数据位置将被当做开始消费的位置。如果kafka中保存有消费者组的消费位置将被忽略。
(4) flinkKafkaConsumer.setStartFromGroupOffsets()
默认的设置。根据代码中设置的group.id设置的消费者组,去kafka中或者zookeeper中找到对应的消费者offset位置消费数据。如果没有找到对应的消费者组的位置,那么将按照auto.offset.reset设置的策略读取offset。
FlinkKafkaConsumer011<String> consumer011 = new FlinkKafkaConsumer011<>("FlinkTopic", new SimpleStringSchema(), props);
// consumer011.setStartFromEarliest();
// consumer011.setStartFromLatest();
// consumer011.setStartFromGroupOffsets();
// consumer011.setStartFromTimestamp(111111);
DataStreamSource<String> dateSource = env.addSource(consumer011);
dateSource… …
- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
2. Flink消费kafka数据,消费者offset提交配置
Flink提供了消费kafka数据的offset如何提交给Kafka或者zookeeper(kafka0.8之前)的配置。注意,Flink并不依赖提交给Kafka或者zookeeper中的offset来保证容错。提交的offset只是为了外部来查询监视kafka数据消费的情况。
配置offset的提交方式取决于是否为job设置开启checkpoint。可以使用env.enableCheckpointing(5000)来设置开启checkpoint。
(1) 关闭checkpoint:
如何禁用了checkpoint,那么offset位置的提交取决于Flink读取kafka客户端的配置,enable.auto.commit ( auto.commit.enable【Kafka 0.8】)配置是否开启自动提交offset, auto.commit.interval.ms决定自动提交offset的周期。
(2) 开启checkpoint:
如果开启了checkpoint,那么当checkpoint保存状态完成后,将checkpoint中保存的offset位置提交到kafka。这样保证了Kafka中保存的offset和checkpoint中保存的offset一致,可以通过配置setCommitOffsetsOnCheckpoints(boolean)来配置是否将checkpoint中的offset提交到kafka中(默认是true)。如果使用这种方式,那么properties中配置的kafka offset自动提交参数enable.auto.commit和周期提交参数auto.commit.interval.ms参数将被忽略。
3. 使用checkpoint + 两阶段提交来保证仅一次消费kafka中的数据
当谈及“exactly-once semantics”仅一次处理数据时,指的是每条数据只会影响最终结果一次。Flink可以保证当机器出现故障或者程序出现错误时,也没有重复的数据或者未被处理的数据出现,实现仅一次处理的语义。Flink开发出了checkpointing机制,这种机制是在Flink应用内部实现仅一次处理数据的基础。
checkpoint中包含:
- 当前应用的状态
- 当前消费流数据的位置
在Flink1.4版本之前,Flink仅一次处理数据只限于Flink应用内部(可以使用checkpoint机制实现仅一次数据数据语义),当Flink处理完的数据需要写入外部系统时,不保证仅一次处理数据。为了提供端到端的仅一次处理数据,在将数据写入外部系统时也要保证仅一次处理数据,这些外部系统必须提供一种手段来允许程序提交或者回滚写入操作,同时还要保证与Flink的checkpoint机制协调使用。
在分布式系统中协调提交和回滚的常见方法就是两阶段提交协议。下面给出一个实例了解Flink如何使用两阶段提交协议来实现数据仅一次处理语义。
该实例是从kafka中读取数据,经过处理数据之后将结果再写回kafka。kafka0.11版本之后支持事务,这也是Flink与kafka交互时仅一次处理的必要条件。【注意:当Flink处理完的数据写入kafka时,即当sink为kafka时,自动封装了两阶段提交协议】。Flink支持仅一次处理数据不仅仅限于和Kafka的结合,只要sink提供了必要的两阶段协调实现,可以对任何sink都能实现仅一次处理数据语义。
其原理如下:
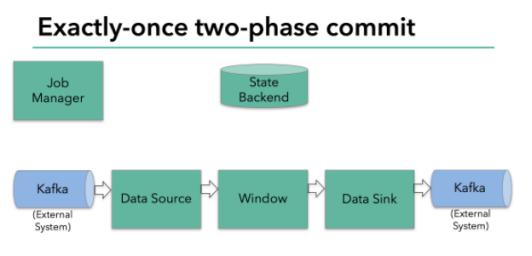
上图Flink程序包含以下组件:
- 一个从kafka中读取数据的source
- 一个窗口聚合操作
- 一个将结果写往kafka的sink。
要使sink支持仅一次处理数据语义,必须以事务的方式将数据写往kafka,将两次checkpoint之间的操作当做一个事务提交,确保出现故障时操作能够被回滚。假设出现故障,在分布式多并发执行sink的应用程序中,仅仅执行单次提交或回滚事务是不够的,因为分布式中的各个sink程序都必须对这些提交或者回滚达成共识,这样才能保证两次checkpoint之间的数据得到一个一致性的结果。Flink使用两阶段提交协议(pre-commit+commit)来实现这个问题。
Filnk checkpointing开始时就进入到pre-commit阶段,具体来说,一旦checkpoint开始,Flink的JobManager向输入流中写入一个checkpoint barrier将流中所有消息分隔成属于本次checkpoint的消息以及属于下次checkpoint的消息,barrier也会在操作算子间流转,对于每个operator来说,该barrier会触发operator的State Backend来为当前的operator来打快照。如下图示:
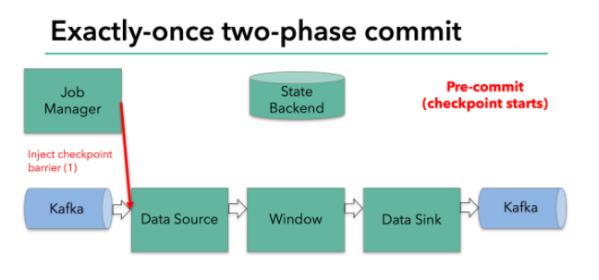
Flink DataSource中存储着Kafka消费的offset,当完成快照保存后,将chechkpoint barrier传递给下一个operator。这种方式只有在Flink内部状态的场景是可行的,内部状态指的是由Flink的State Backend管理状态,例如上面的window的状态就是内部状态管理。只有当内部状态时,pre-commit阶段无需执行额外的操作,仅仅是写入一些定义好的状态变量即可,checkpoint成功时Flink负责提交这些状态写入,否则就不写入当前状态。
但是,一旦operator操作包含外部状态,事情就不一样了。我们不能像处理内部状态一样处理外部状态,因为外部状态涉及到与外部系统的交互。这种情况下,外部系统必须要支持可以与两阶段提交协议绑定的事务才能保证仅一次处理数据。
本例中的data sink是将数据写往kafka,因为写往kafka是有外部状态的,这种情况下,pre-commit阶段下data sink 在保存状态到State Backend的同时,还必须pre-commit外部的事务。如下图:
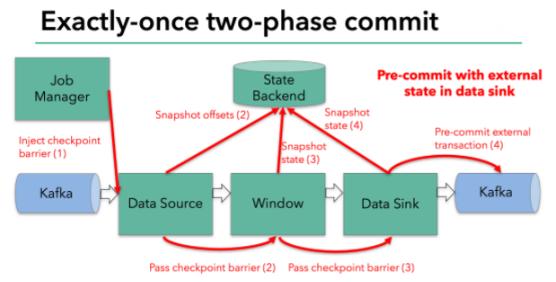
当checkpoint barrier在所有的operator都传递一遍切对应的快照都成功完成之后,pre-commit阶段才算完成。这个过程中所有创建的快照都被视为checkpoint的一部分,checkpoint中保存着整个应用的全局状态,当然也包含pre-commit阶段提交的外部状态。当程序出现崩溃时,我们可以回滚状态到最新已经完成快照的时间点。
下一步就是通知所有的operator,告诉它们checkpoint已经完成,这便是两阶段提交的第二个阶段:commit阶段。这个阶段中JobManager会为应用中的每个operator发起checkpoint已经完成的回调逻辑。本例中,DataSource和Winow操作都没有外部状态,因此在该阶段,这两个operator无需执行任何逻辑,但是Data Sink是有外部状态的,因此此时我们需要提交外部事务。如下图示:
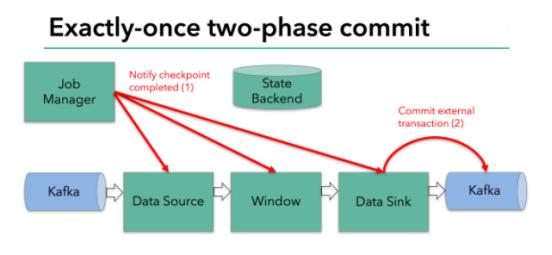
汇总以上信息,总结得出:
(1) 一旦所有的operator完成各自的pre-commit,他们会发起一个commit操作。
(2) 如果一个operator的pre-commit失败,所有其他的operator 的pre-commit必须被终止,并且Flink会回滚到最近成功完成的checkpoint位置。
(3) 一旦pre-commit完成,必须要确保commit也要成功,内部的operator和外部的系统都要对此进行保证。假设commit失败【网络故障原因】,Flink程序就会崩溃,然后根据用户重启策略执行重启逻辑,重启之后会再次commit。
因此,所有的operator必须对checkpoint最终结果达成共识,即所有的operator都必须认定数据提交要么成功执行,要么被终止然后回滚。
(4) Flink中外部状态实现两阶段提交
Flink外部状态实现两阶段提交将逻辑封装到TwoPhaseComitSinkFunction类中,下面扩展TwoPhaseCommitSinkFunction来实现就文件的sink。若要实现支持exactly-once语义的文件sink,需要实现以下4个方法:
- beginTransaction:开启一个事务,创建一个临时文件,将数据写入到临时文件中
- preCommit:在pre-commit阶段,flush缓存数据到磁盘,然后关闭这个文件,确保不会有新的数据写入到这个文件,同时开启一个新事务执行属于下一个checkpoint的写入操作
- commit:在commit阶段,我们以原子性的方式将上一阶段的文件写入真正的文件目录下。【注意:数据有延时,不是实时的】
- abort:一旦异常终止事务,程序如何处理。这里要清除临时文件。
















