













一、背景
面对订单数据纸质文件或图片,仅靠人眼识别的话效率低,需引入机器学习来识别和解析图片以提高效率。当前市面已有收费的图片识别服务,包括阿里、百度等,识别效果较好,但针对订单类图片,不仅需要关注图片上的文字,还需要关注文字所在的行列,来分出每条数据和数据详细字段。
本篇内容主要介绍一种针对识别完结果进行行列解析的抽象流程和方案,来提高开发效率。
本文只提供思路,不提供源码。另外,本文不介绍人工智能图片识别,有兴趣的同学请关注大神们的文章,这里推荐“宜信技术学院官网文章AI板块”。
二、解析流程
对于图像处理,opencv算是比较优秀的,所以选做本文图像处理首选软件。为了使图片识别率更高,需要先做图片矫正,这里采用较为简单的霍夫变换加去噪声点算法矫正图片。图片矫正后,调用图片识别服务获取结果,一般结果格式包括响应码、错误描述、文字块列表(文字和四点坐标)等。根据识别结果使用抽象的俄罗斯方块法来识别结果获取行列信息。最后根据行列信息组装每一行数据并显示。
三、处理细节
3.1 opencv安装概要
opencv安装简单提示,这里不细说,以后有时间单独发文。
1)windows
- 下载编译好的包:https://opencv.org/releases/
- 解压缩到自定义文件夹。
2)linux
- 推荐使用ubuntu,并且最好是全新的系统,因为opencv会依赖很多包,对版本要求也高,解决冲突会很麻烦。
- 下载源码
- 安装依赖包
- 编译安装
我们使用java调用opencv,这里需要安装获取到开发包,windows为opencv_javaxxx.dll,linux为libopencv_javaxxx.so,程序初始化时需要加载到jvm。详细代码如下:
- System.load(PropertieUtil.getPropertie("这里是dll或so的完整路径");
3.2 图片矫正
3.2.1 矫正探索
图片矫正探索之路较为艰辛,起初我们想了一个比较简单的方案:先调用图片识别服务,获取到结果,再根据每一个字块的四角坐标判断出每个字块的倾斜角,然后再根据去噪算法算出平均的倾斜角。理论上这个方案是可行的,但实践证明我们是错的,因为图片识别服务返回的坐标图片不准确,多数的图片算出的结果都是错误的。
经查发现霍夫变换有可能解决这个问题,于是开始尝试学习霍夫变换和去燥算法,最终发现可行,并抽象出公共方法,仅需简单配置一些参数就能完成矫正。
图片矫正分为两步:
第一步:正反矫正,判断图片倾斜角度是90°、180°、270°、0°,这个通过数学方法是无法判断的,需要引用机器学习。
第二步:角度微调,一般为确定图片是正的,且倾斜角度在+-30°左右。
需要注意:上面说的办法不可能通过一套参数来对所有图片进行微调,但是线上数据证明,针对一类图片,一套参数基本能让大多数图片都矫正正确。
3.2.2 霍夫变换概要
霍夫变换是数学界经典空间变换算法,用于检测直线,通过大量检测到的直线的斜率就能计算出图片倾斜角度。先进行二值化和边缘检测,再进行霍夫变换效果更佳。详细算法内容请自行搜索,本文不细聊。
3.2.3 去噪声点算法
基本公式:
上限=均值+n*标准差
下限=均值-n*标准差
其中n取值一般为1-4,数值越大表示筛选率越高。最后再将符合的数据求均值。
核心代码如下:
- /**
- * 利用标准差筛选
- * @param values
- * @return
- */
- private static double[] calcBestCornList(double[] values) {
- // 计算标准差
- StandardDeviation variance = new StandardDeviation();
- double evaluate = variance.evaluate(values);
- Mean mean = new Mean();
- double meanValue = mean.evaluate(values);
- double biggerValue = meanValue + CHOOSE_POWER * evaluate;
- double smallerValue = meanValue - CHOOSE_POWER * evaluate;
- List<Double> selected = Lists.newArrayList();
- for (double value : values) {
- if (value >= smallerValue && value <= biggerValue) {
- selected.add(value);
- }
- }
- double[] selectedValue = new double[selected.size()];
- for (int i = 0; i < selected.size(); i++) {
- selectedValue[i] = selected.get(i);
- }
- logger.info("占比:{}%,筛选后角度数组:{}", (selectedValue.length / (float)values.length) * 100F, selected);
- return selectedValue;
- }
3.2.4 霍夫变化抽象封装
基本流程:
1、定义相关参数。
2、读取图片。
3、灰度二值化处理。
4、使用opencv画出轮廓。
5、根据参数要求多次画霍夫变换线,直到线数量满足参数为止。
6、遍历画出的线,分出横线和竖线,根据配置计算出每条线角度。
7、使用去噪声算法(需要根据非0数自动重复计算)算出平均倾斜角度。
8、使用opencv旋转图片。
核心代码如下:
- /**
- * 矫正图片,通过霍夫变换矫正
- * @param oldImg 原始图片
- * @param rotateParam 旋转参数
- * @return
- */
- public static String rotateHoughLines(File oldFile, String oldImg, RotateParam rotateParam, String cid, String bankCode) throws Exception {
- Mat src= Imgcodecs.imread(oldFile.getAbsolutePath());
- //读取图像到矩阵中
- if(src.empty()){
- throw new Exception("no file " + oldFile.getAbsolutePath());
- }
- // 用于计算的图片矩阵
- Mat mathImg = src.clone();
- // 灰度化
- Imgproc.cvtColor(src, mathImg, Imgproc.COLOR_BGR2GRAY);
- logger.info("二值化完成");
- // 获取轮廓
- Imgproc.Canny(src, mathImg, rotateParam.getCvtThreshould1(), rotateParam.getCvtThreshould2());
- logger.info("轮廓完成");
- // 霍夫变换获取角度,详细代码略
- double corn = houghLines(mathImg, rotateParam, cid);
- logger.info("霍夫变换完成,角度:{}", corn);
- if(corn == 0) {
- return oldImg;
- }
- return rotateOpenv(oldFile, corn, cid, bankCode);
- }
3.3 常用图片识别方案
阿里、百度都有提供图片识别服务,另外如果有实力也可以自己实现,当然不建议自研,因为样本需求量巨大,时间成本过高。
3.4 识别结果解析
3.4.1 探索之路
本章节为本文重点内容,因为前面所提到的都是较为基础的服务和算法,大量开发内容都在本章。前期要开发的订单图片类型巨量(大于100种),每一类图片区别很大,我们有几个人分类型开发,但是每个人所用的方法都不同,且张三开发出来的李四看不懂,不过毕竟面对的是图片,比较抽象,是可以理解的。
开发一段时间后,我们发现了问题。每种类型最快也要一周才能开发完成,而且解析成功率极低。开发出一套抽象的方法来把行列数据提取出来迫在眉睫。
通过调研发现大家常用两种方法来提取行列数据,分别为坐标法和标题法,但是这两种方法解析率都不高。经过几周思考,终于想出了一套较好的方法,命名为俄罗斯方块法,解决了问题。
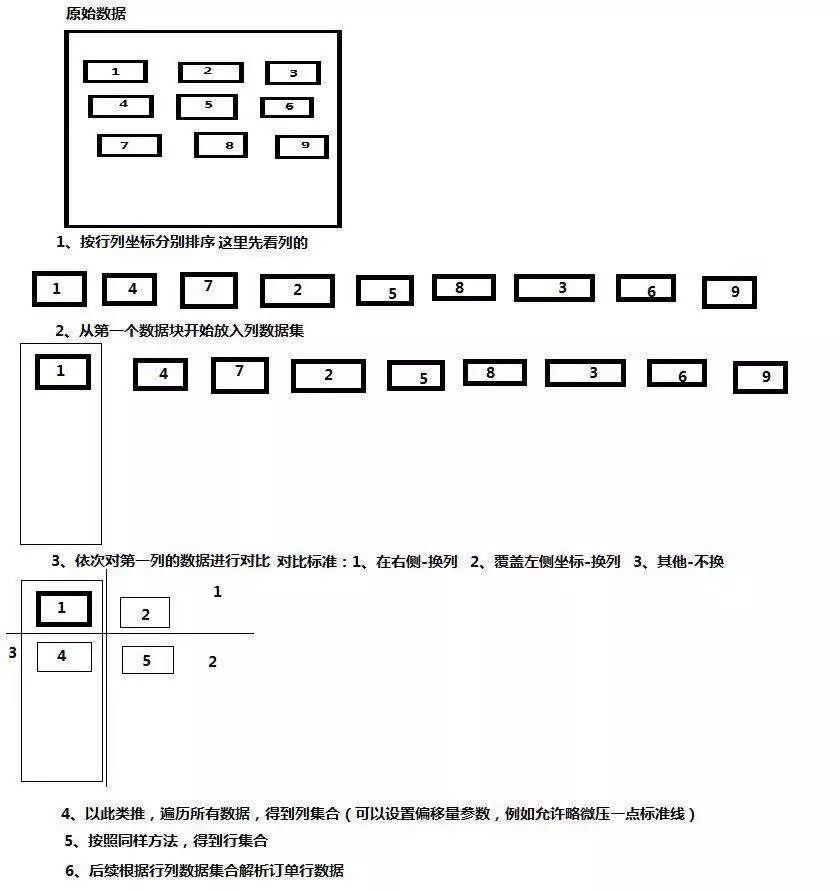
3.4.2 俄罗斯方块法
思路概要:
1. 拿到识别结果数据。
2. 先把所有数据的y坐标进行排序。
3. 遍历排序结果,先把第一条放入第一列结果集中。
4. 从第二条开始和第一列结果集对比。
5. 对比方法:
--如果在第一列结果集其中一条数据的右侧,则认为是新列。
--如果在y轴方法和第一列结果其中某些数据重叠了,则认为是新列。
6. 如果以上两条都不是,则认为本条数据还在当前列中,放入第一列结果集。
7. 以此类推,继续对比,直到对比到最后一列最后一条数据。
8. 按照上面方法,反过来,以x轴为标准,能够得到行结果集。
思路图如下:
概要代码如下:
- // 按照最左上角的x坐标排序
- OcrWordInfo[] sortL = NoTableParseResult.ParseUtil.bubbleSortX(ocrResponse.getPrism_wordsInfo(), false);
- NoTableParseResult ntpr = new NoTableParseResult(param);
- ntpr.setHeight(converImg.height());
- ntpr.setWight(converImg.width());
- for (int i = 0; i < sortL.length; i++) {
- // 当前要比较的数据
- OcrWordInfo ocrWordInfo = sortL[i];
- // 处理当前列数据
- ntpr.getUtil().testCurColData(ocrWordInfo);
- }
- // 处理最后一列
- ntpr.lastCol();
- /**
- * 判断是否为下一列,并处理
- * @param ocrWordInfo
- * @return
- */
- public void testCurColData(OcrWordInfo ocrWordInfo) {
- // 遍历当前列已存在的所有数据
- int size = this.test.getCol().size();
- if(size == 0) {
- this.test.addCol(ocrWordInfo);
- return;
- }
- for (int i = 0; i < size; i++) {
- OcrWordInfo temp = this.test.getCol().get(i);
- // 最右边的数据
- int x1 = temp.getPos().get(1).getX();
- int x2 = temp.getPos().get(2).getX();
- // 当前数据最左边
- int xx0 = ocrWordInfo.getPos().get(0).getX();
- int xx3 = ocrWordInfo.getPos().get(3).getX();
- int threholdx = this.test.param == null ? 0 : this.test.param.getCoverColXThrehold();
- if(xx0 >= (x1 - threholdx) && xx0 >= (x2 - threholdx) && xx3 >= (x1 - threholdx) && xx3 >= (x2 - threholdx)) {
- // 当前数据在右边,说明换列了!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!
- this.test.colAdd();
- this.test.addCol(ocrWordInfo);
- return;
- } else {
- // 判断是否覆盖坐标
- int y0 = temp.getPos().get(0).getY();
- int y3 = temp.getPos().get(3).getY();
- int yy0 = ocrWordInfo.getPos().get(0).getY();
- int yy3 = ocrWordInfo.getPos().get(3).getY();
- int threhold = (int)Math.round((y3 - y0) * (this.test.param == null ? 0.25 : this.test.param.getCoverThrehold()));
- if(!(yy3 <= (y0 + threhold) || yy0 >= (y3 - threhold))) {
- // 当前列表数据重叠,说明换列了!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!
- this.test.colAdd();
- this.test.addCol(ocrWordInfo);
- return;
- }
- }
- }
- // 执行到这说明没覆盖
- this.test.addCol(ocrWordInfo);
- }
3.4.3 解析行数据技巧
技巧总结:
1、俄罗斯方块法提供去除干扰项的参数,可以根据图片特点,去除上下左右干扰数据来减少串行列现象。
2、解析数据大致有两种方法:
- 根据标题列号来判断数据,这种方法不通用,简单、规范的图片识别率高,但是无法适配乱的图。
- 把每一行数据以间隔符号分割拼到一起,使用正则表达式来‘扣’数据,因为一般同类型订单图片,关键字段的位置是有特点的,例如金额格式、借贷方向、日期等,这种方法通用,但识别率不高。
*具体使用哪种方法,还需要根据图片特点进行取舍。
3、 俄罗斯方块法提供一些微调参数,用于适配一些特殊场景,例如换行列阀值之类的。
4、中间需要保存一些过程图片,例如矫正过程的若干张图、俄罗斯方块法识别结果的连线图等,毕竟这种项目,查问题时靠日志是没用的,还得靠这些中间图才能更快查到问题。
四、总结
本文提到的方案不能完全解决所有订单类图片解析问题,但可以做到新手快速入门快速开发,如果您有更好思路欢迎交流。
【本文是51CTO专栏机构宜信技术学院的原创文章,微信公众号“宜信技术学院( id: CE_TECH)”】

















