大数据文摘出品
来源:techtalks
编译:木槿、曹培信、钱天培
计算机算力的增强为人工智能发展铺平了道路。
通过强大的云计算平台,人工智能研究人员已经能够在较短的时间训练更复杂的神经网络,这使得AI能够在计算机视觉、语音识别和自然语言处理等许多领域取得进展。
与此同时,很少有人提及这一趋势对AI研究的负面意义。
目前,人工智能的进步主要体现在对深度学习模型和更多层和参数的神经网络的研究。根据OpenAI的说法,自2012年以来最大规模人工智能训练中使用的计算机数量一直呈指数增长,大概每3到4个月就翻一番,这意味着该指标在七年内增长了30万倍。
这种趋势严重限制了AI的研究,也产生了其他不好的影响。
目前来说,“大”即是好
OpenAI研究人员表示,当前许多领域中,更大的算力代表着更好的表现,并且通常也是对算法的补充。
我们可以在很多项目中看到,研究人员将取得的进步归功于他们投入了更多的计算机去处理问题。
2018年6月,OpenAI推出了能够玩Dota2专业水准的AI,Dota2是一款复杂的即时战略游戏。
该AI叫OpenAIFive,它参加了一场大型的电子竞技比赛,但在决赛中输给了人类玩家。
OpenAI研究室今年推出的改良版本Open Five回归赛季,最终战胜了人类选手获得冠军。AI相关研究人员透露说,与周六在Open International 2018的失利相比,Open Five的胜利主要归功于8倍的训练计算量。
还有很多类似的例子表明,通过增加计算量可以更好的计算结果,这种方法对强化学习来说这确实是对的。目前,强化学习也是AI研究领域最热门的方向之一。
训练大型AI模型的财务成本
财务成本直接影响了训练AI模型。OpenAI网站上的图表显示,该公司以1,800 petaflop/s-days的速度训练DeepMind的围棋AI——AlphaGoZero。
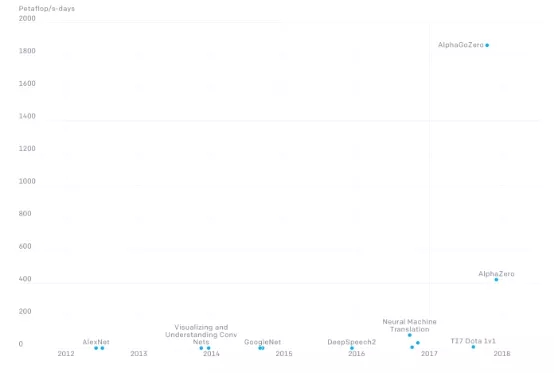
Flop代表浮点运算,petaflop/s-day (pfs-day)表示每天1020次运算。Google的TPU v3处理器是一个专门用于人工智能任务的处理器,它每天可以处理0.42 1020次运算,它每个小时花费2.4至8美元。这意味着大概需要246,800至822,800美元训练AlphaGo模型,并且这个只是单纯的计算操作的成本。
这一领域的其他显著成就也付出了类似的代价,例如,根据DeepMind发布的数据,它旗下的玩星际争霸AI由18部分组成,每一部分都使用16个Google的TPU v3处理器训练了14天,这意味着按照目前的价格水平,这家公司花费了77.4万美元训练玩星球争霸的人工智能。
AI研究的商业化
人工智能的计算需求对进入该领域的公司来说是一大门槛。
总部位于英国的著名人工智能实验室DeepMind的成功主要是因为其母公司谷歌的巨大的资源投入。2014年,谷歌以6.5亿美金收购DeepMind后,为其提供了足够的资金支持和技术帮助。根据DeepMind向英国公司注册处提交的文件显示,今年早些时候,DeepMind在2018年亏损5.7亿美金,高于2017年的3.41亿美金。DeepMind今年还欠10.4亿英镑债券,其中8.83亿英镑来自Alphabet。
另一个是“烧钱大户”是OpenAI。它最初是一个非盈利性人工智能研究实验室,2016年获得了萨姆•奥尔特曼和埃隆•马斯克10亿美元的资助。今年早些时候,OpenAI转型为盈利性人工智能研究实验室,以吸收投资者的资金。该实验室支持其研究的资金已所剩无几,今年微软又宣布将在实验室投资10亿美元。
正如当前趋势所示,由于AI研究(特别是强化学习)的成本,使得这些实验室变得越来越依赖于有钱的公司,例如谷歌和微软。
这种趋势迫使人工智能研究商业化。随着商业组织在为AI研究实验室提供资金方面变得越来越重要,它们甚至可以影响研究方向。目前,像谷歌和微软这样的公司可以承受运行DeepMind和OpenAI等AI研究实验室的财务费用,但是他们也希望在不久的将来获得利润。
问题是,OpenAI和DeepMind都在追求诸如通用人工智能(AGI)之类的科学项目。这是人类尚未完全理解的领域,更不用说实现了。大多数科学家都认为目前人类距实现通用人工智能至少还要一个世纪的时间,这样的时间表使得最富有公司的耐心也得到了考验。
对于AI研究实验室来说,一种可能的情况是逐渐将目标从长期的学术和科学研究转向能短期收益的面向商业的项目,这将使他们的投资者高兴,但总体上却不利于AI研究。
OpenAI研究人员表示:“我们对未来AI系统中计算机的使用非常不确定,但是也很难断言算力快速增长的趋势会停止,而且我们也看到了很多因素导致这种趋势将继续下去。根据这一分析,我们认为决策者应该考虑增加AI学术研究经费,显而易见的是某些类型的AI研究所需的算力正在变得更高,因此费用会越来越高。”
AI研究的碳排放
训练大型人工智能模型所需的计算资源消耗了大量的能源,这也造成了碳排放问题。
根据马萨诸塞大学阿默斯特分校的研究人员发表的一篇论文,训练一个带有2.13亿个参数的Transformer模型(常用于与语言相关的任务)所造成的污染相当于5辆汽车开到报废的排放总量。Google著名的BERT语言模型和OpenAI的GPT-2分别有3.4亿和15亿个参数。
鉴于目前的AI研究被“越大越好”的口号所主导,人们对环境的担忧只会日益加重。不幸的是,人工智能研究者很少报道或关注他们工作的这些方面。麻省理工大学的研究人员建议人工智能论文要公开他们的模型的环境成本,并让公众更好地了解他们的研究对环境的影响。
人工智能领域的惨痛教训
对更大更复杂的神经网络的最后一个担忧,是它可能对AI研究的方向产生负面影响。目前,AI中一些障碍主要是通过使用更多数据并进行训练来解决。与此同时,就人类大脑和AI处理一些相同的最简单的任务来说,大脑所消耗的能量相比AI这小得多。
过于依赖不断增加的算力,可能会使我们无法找到更有效的新的人工智能解决方案。
将神经网络和符号派人工智能相结合的混合人工智能模型的开发是这一领域的一项有趣的领域。符号人工智能是经典的、基于规则的人工智能,与神经网络不同,符号派人工智能不是通过增加计算资源和数据来扩展的。它也很难处理现实世界中混乱的、非结构化的数据,但它在知识表示和推理方面非常出色,而这两个优势是神经网络严重缺乏的。探索混合人工智能的想法可能会为发明资源效率更高的人工智能开辟新的途径。
在此,我们不加赘述。感兴趣的读者可以阅读加里马库斯和欧内斯特戴维斯的新书《重启人工智能》(Rebooting AI),以及计算机科学家朱迪亚·珀尔撰写的《为什么》(The book of Why)。
“越大越好”的思想已经开始将AI研究带向深渊。科学界不应该等到下一个人工智能寒冬才开始认真思考这些问题。
相关报道:
https://bdtechtalks.com/2019/11/25/ai-research-neural-networks-compute-costs/

【本文是51CTO专栏机构大数据文摘的原创译文,微信公众号“大数据文摘( id: BigDataDigest)”】