概述
所谓的LRU(Least recently used)算法的基本概念是当内存的剩余的可用空间不够时,缓冲区尽可能的先保留使用者最常使用的数据,换句话说就是优先清除”较不常使用的数据”,并释放其空间.之所以”较不常使用的数据”要用引号是因为这里判断所谓的较不常使用的标准是人为的、不严格的.所谓的MRU(Most recently used)算法的意义正好和LRU算法相反。
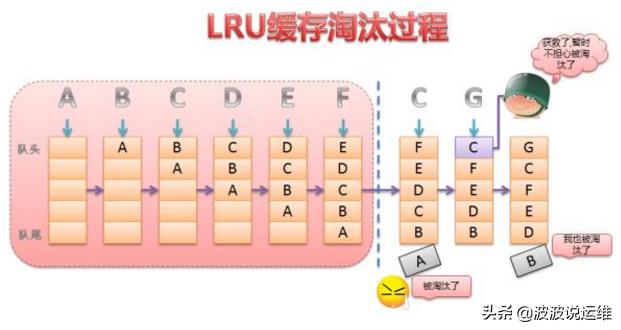
Oracle在高速缓冲区工作机制中就用到了这个算法,下面一起看看吧~
LRU链:
任何缓存的大小都是有限制的,并且总不如被缓存的数据多。就像Buffer cache用来缓存数据文件,数据文件的大小远远超过Buffer cache。
因此,缓存总有被占满的时候。当缓存中已经没有空闲内存块时,如果新的数据要求进入缓存,就只有从缓存中原来的数据中选出一个牺牲者,用新进入缓存的数据覆盖这个牺牲者。这个牺牲者的选择,是很重要的。缓存是为了数据可以重用,因此,通常应该挑选缓存中最没有可能被重用的块当作牺牲者。牺牲者的选择,从CPU的L1、L2缓存,到共享池、Buffer cache池,绝大多数的缓存池都是采用著名的LRU算法,不过在Oracle中,Oracle采用了经过改进的LRU算法。具体的算法它没有公布,不过LRU算法总的宗旨就是“最近最少”,其意义是将最后被访问的时间距现在最远的内存块作为牺牲者。
比如说,现在有三个内存块,分别是A、B、C,A被访问过10次,最后一次访问是在10:20,B被访问过15次,最后一次访问是10:18,C也被访问10次,最后一次被访问是在10:22。当需要选择牺牲者时,B访问次数最多,牺牲者肯定不是它。A、C访问次数一样,但A在10:20被访问,而C在10:22被访问,A最后被访问的更早些,牺牲者就是A。
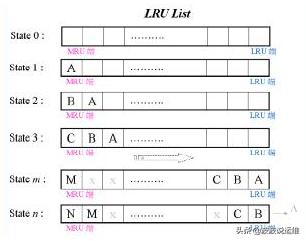
为了实现LRU的功能,Oracle在Buffer cache中创建了一个LRU链表,Oracle将Buffer cache中所有内存块,按照访问次数、访问时间排序串在链表中。链表的两头我们分别叫做热端与冷端, 如下图:

当你第一次访问某个块时,如果这个块不在Buffer cache中,Oracle要选将它读进Buffer cache。在Buffer cache中选择牺牲者时,Oracle将从冷端头开始选择,在上图的例子中,内存块U将是牺牲者。

如上图,新块将会被读入U,覆盖U原来的内容。这里,我们假设新块是V。但是块V不会被放在冷端头,因为冷端头的块,会很快被当作牺牲者权覆盖的。这不符合“将最后访问时间距现在最远的块作为牺牲者”的宗旨。块V是最后时间距当前时刻最近的,它不应该作为下一个牺牲者。Oracle是如何实验LRU的,我们继续看。

Oracle将LRU链从中间分为两半,一半记录热端块、一半记录冷端块。如上图,而刚刚被访问的块V,如下图:


如过再有新的块进入Buffer cache,比如块X被读入Buffer cache,它将覆盖T,并且会被移至块V的前面,如下图:

如果按照这面的方式继续下去,最右边冷端头处的块,一定是最后一次访问时间距现在最远的块。那么,访问次数多的块是不会被选做牺牲者的,这一点Oracle是如何实现的?这很简单,Oracle一般以2次为准,块被访问2次以上了,它就有机会进入热端。
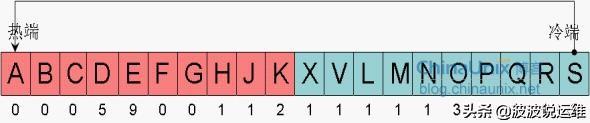
Oracle为内存中的每个块都添加了一个记录访问次数的标志位,假设图中每个块的访问次数如下:

如果现在又有新块要被读入Buffer cache,Oracle开始从冷端头寻找牺牲者,冷端头第一个块S,它的访问次数是2,那么,它不能被覆盖,只要访问次数大于等于2的块,Oracle会认为它可能会被经常访问到,Oracle要把它移到热端,它会选择R做为本次的牺牲者:

块S会被从冷端移到热端,并且它的访问次数会被清零。此时,块R就是牺牲者了,因为它的访问次数不到两次。

新块Y覆盖了块R,并被移到了冷端块开始处,它的访问次数是1。如果块Y再被访问了一次,它的访问次数变为了2:

虽然Y的访问次数达到了两次,但它不会马上被移到热端,它仍然留在原来的位置,随着不断有新块加入,被插入到它的前面,它会不断的被向后推移。

如上图,又加入了很多的新块,Y又被推到了冷端头,当再有新块进入Buffer cache时,Y不会是牺牲者,它会被移到热端头S的前面,Y后面的Z,它的访问次数没有达到2,它将会是牺牲者。
上面就是Oracle中Buffer cache管理LRU的原理。按照这种方式运作,Oracle可以把常用的块尽量长的保持在Buffer cache中。而且,每有新块进入Buffer cache,Oracle都会从冷端头处,从右向左搜索牺牲块。因为越靠近冷端,块的访问次数有可能越少、最后的访问时间离现在最远。
脏块与脏LRU链:
Oracle中修改块的规则是只对Buffer cache中的块进行修改,并不直接修改磁盘中的块。如果要修改的块不在Buffer cache中,Oracle会先将它读入Buffer cache,再在Buffer cache中进行修改。
当Buffer cache中的块被修改后,Oracle会把它标记为“脏”块。脏块含有脏数据,脏数据就是用户修改过的数据。Oracle会定期的将脏块写到磁盘中。有一个专门的后台进程就是专门负责写脏块到磁盘的,它就是DBWn。我们也把DBWn写脏块到磁盘这个过程叫做刷新脏块,刷新过后,脏块就不脏了,又变成了干净块。其实,有一个块A,如果Buffer cache中此块的数据和磁盘上块中数据不一致,那么,这个块就是脏块。否则,就是干净块。当修改完成后,因为Oracle只修改Buffer cache,因此,块中数据和磁盘肯定不一致,这时块就是脏块。当块被刷新后,块被写到磁盘,那么,磁盘中块数据和Buffer cache中块的数据又是一致的,此时,块就又变成了干净块。
脏块在被写回磁盘前,也就是在它还是脏块时,它是不能被覆盖的,因为,脏块含有用户修改过的数据,而这些数据还没被写到磁盘,如果此时覆盖了脏块,用户的修改结果将会丢失。

设当前LRU链如上图所示,其中V、L、O、P、Q是脏块。当新的块要进入Buffer cache时,Oracle从冷端头开始选择牺牲块,Q、P和O都不能做作牺牲块,因为它们是脏块,N是这一次的牺牲者,新进入的块将会覆盖N,然后将新的块插入到Y之前。然后呢,下一次有块进入Buffer cache时,Oracle从冷端头开始搜索,它还要检查一边Q、P和O,发现它们都不能覆盖,再将M定为牺牲者。等等,每一次都要检查一边O、P、Q,这太浪费时间了,Oracle不会这么傻,Oracle有准备了一个脏LRU链,专门保存脏块。当块变脏时,块不会马上被移到脏LRU中,只有当Oracle从冷端头开始,寻找牺牲者时,才会将发现的脏块移动到脏LRU链中。这样做的目的就是下次再寻找牺牲者时,可以不用再检查这些脏块。
总结
从LRU链与脏LRU链的原理,我们可以发现Oracle把很多工作,都留到了在LRU的冷端搜索牺牲者时。当块的访问次数增加的超过2时,块在LUR链的位置不变;当块变脏时,块的LRU链位置也不变。只有当从LRU的冷端搜索牺牲者时,才会将发现的脏块移到脏LRU链,将访问次数超过2的,插入到热端,这就是Oracle改进了的LRU算法。
当访问次数大于2的块太多,或才脏块太多,反正这些块都是不能覆盖的,Oracle不得不移动它们到它们该去的位置。当碰到的这样的块超过LRU中总块数的40%时,也就是说搜索了一小半LRU链,还是没有发现可以覆盖的牺牲者,Oracle就不在找了,它会唤醒DBWn刷新脏块。在DBWn刷新期间的等待,就会被记入到free buffer waits事件中。
在寻找牺牲者过程中发现脏块,Oracle将其移动到脏LRU链,但是脏LRU链中脏块数目达到限制,DBWn被唤醒开始刷新脏块,Oracle必须等待刷新脏块完毕,才能再继续寻找牺牲者,这其间的等待事件,也会被记入free buffer inspected。
总之,free buffer waits事件发生的主要原因就是在LRU中寻找牺牲者的时间过长。如果 这个等待事件频繁出现,说明Buffer cache中脏块太多了,这通常是DBWn写刷新速度慢造成的。