数据科学领域新的功能不断发展,并渗透到每个行业。随着全球各组织开始数字化转型,2019年出现了更多公司利用数据做出更好决策的趋势。这里我们看一下预计在2020年会起飞的数据科学新趋势。
2019年是数据科学领域重要的一年 。 全世界各行各业的公司都在经历着数字化转型,企业中的传统业务流程,例如招聘、营销、定价、战略等,都通过数字科技的运用使其效率提高了10倍以上。 数据科学已成为数字化转型不可或缺的组成部分。使用数据科学,组织不再需要根据预感、猜测或小型调查做出重要决策。取而代之的是,他们正在分析大量真实数据,以根据真实的、数据驱动的事实做出决策。这就是数据科学的全部意义所在——通过数据创造价值。
根据Google搜索趋势,在过去5年中将数据集成到核心业务流程中的趋势已经显着增长了四倍以上。
数据为公司提供了超越竞争对手的巨大优势。有了更多的数据和更好的数据科学家来使用它,公司可以获取其竞争对手甚至可能不知道的市场信息,它已成为数据或灭亡的游戏。
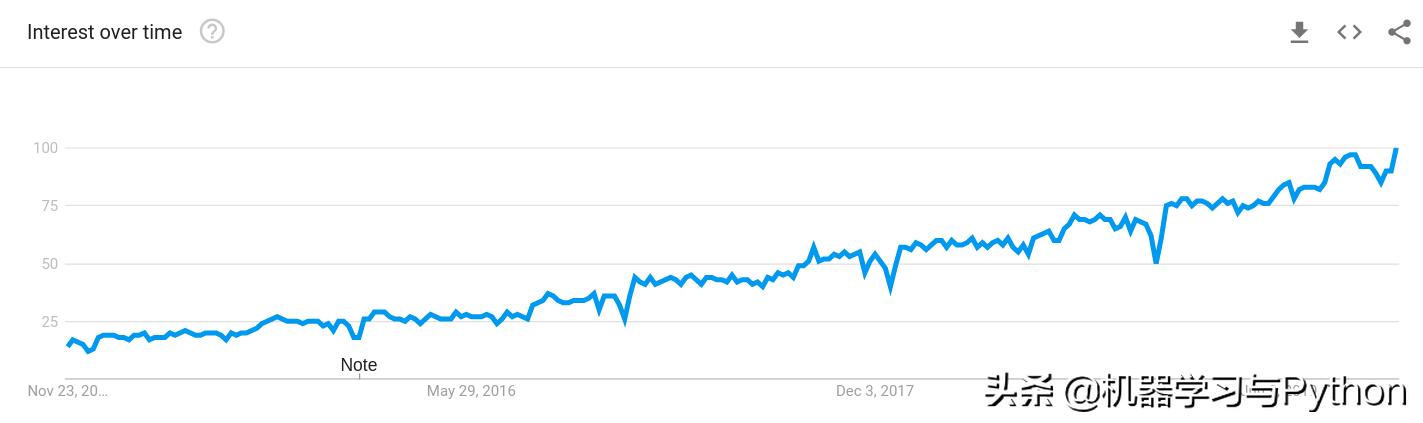
过去5年Google搜索“数据科学”趋势
在当今不断发展的数字世界中,要在竞争中保持领先地位需要不断的创新。专利已经过时,而敏捷方法论(译者注:也称轻量级方法,它是一组开发方法的统称)和快速捕捉新趋势非常重要。
组织不能再依靠其坚如磐石的旧方法。如果出现诸如数据科学、人工智能、区块链之类的新趋势,则需要预先进行预测并迅速适应。
以下是2020年最热门的4种数据科学趋势。这些趋势已在今年引起了越来越多企业的兴趣,并将在2020年继续增长。
(1)数据科学自动化
即便在当今的数字时代,数据科学仍然需要大量的手工作业。存储、清理、可视化和探索数据,最后对数据进行建模以获得实际结果。这些手工作业正在寻求自动化,于是数据科学自动化和机器学习已然兴起 。
数据科学流程的几乎每个步骤都已经或正在变得自动化。
在过去的几年中,自动数据清理已被广泛研究。清理大数据通常会占用数据科学家的大部分昂贵时间,初创公司和大型公司(例如IBM)都提供了用于数据清理的自动化操作和工具。
数据科学的另一大部分(称为特征工程)已遭受重大冲击。Featuretools(译者注:可自动构造机器学习特征的Python库)提供了自动特征工程的解决方案。最重要的是,诸如卷积和递归神经网络之类的现代深度学习技术无需手动特征设计即可学习其自身的特征。
最重要的自动化发生在机器学习领域。Data Robot和H2O已在行业通过提供终端到终端的机器学习平台,使数据科学家对数据管理和模型更容易掌握,从而确立了自己地位。
用于自动模型设计和训练的AutoML在2019年也蓬勃发展,因为这些自动模型已经超越了较新的技术。尤其是Google,正在Cloud AutoML上投入重金。
总的来说,公司在构建和购买用于自动化数据科学的工具和服务方面进行了大量投资,只要能让这个过程更便宜、更容易。同时,这种自动化还适合规模较小和技术含量较低的组织,这些组织可以利用这些工具和服务来使用数据科学,而无需建立自己的团队。
(2)数据隐私与安全
隐私和安全始终是技术领域中的敏感话题。所有公司都希望快速发展和创新,但是失去客户对隐私或安全问题的信任可能是致命的。因此,他们被迫将其作为优先事项,至少要做到不泄漏私人数据。
在过去的一年中,数据隐私和安全性已成为一个令人难以置信的热门话题,因为巨大的公共黑客事件使这一问题更加严重。就在最近的2019年11月22日,在Google Cloud上发现了一个没有安全性的公开服务器。该服务器包含12亿条个人信息,包括姓名,电子邮件地址,电话号码以及LinkedIn和Facebook个人资料信息。联邦调查局也介入调查,它是有史以来较大的数据泄露事件之一。
它是在任何人都可以创建的Google Cloud服务器上。数据如何到达那里?它属于谁?谁要为该数据的安全性负责?
虽然大家看到这个新闻之后不会删除他们的LinkedIn和Facebook帐户,但是确实引起了一些关注。消费者越来越关注将电子邮件地址和电话号码提供给了谁。
能够保证客户数据私密性和安全性的公司会发现,他们说服客户(通过继续使用其产品和服务)向他们提供更多数据会更加容易。如果政府制定了任何要求为客户数据提供安全协议的法律,这些公司还应该确保自己已经做好了充分的准备。所以,许多公司选择SOC2隐私性原则(译者注:美国注册会计师协会(AICPA) 制定的隐私保护审计标准)来证明其安全强度。
整个数据科学过程都由数据推动,但其中大多数不是匿名的。数据不仅代表原始数字,而且描述真实的人和真实的事物。如果使用不当,这些数据可能会助长全球隐私灾难,并影响人们的日常生活。
随着数据科学的发展,我们还将看到围绕数据的隐私和安全协议的转变。其中包括流程、法律以及建立和维护数据安全性和完整性的不同方法。如果网络安全成为今年的流行语,也不足为奇。
(3)云中的超大型数据科学
多年以来,数据科学已经从一个小众市场发展成为为完整的领域,可用于分析的数据也呈爆炸式增长,组织正在收集和存储比以往更多的数据。
一家典型的财富500强公司可能需要分析的数据量已经远远超出了个人计算机的处理能力。像样的个人电脑可能具有64GB的内存、8核CPU和4TB的存储空间。这对于个人项目来说效果很好,但是当您在一家拥有数百万客户数据的跨国公司(例如银行或零售商)工作时,效果就不那么理想了。
所以,云计算进入数据科学领域。云计算使任何地方的任何人都可以访问几乎无限的处理能力。诸如Amazon Web Services(AWS)之类的云供应商提供了多达96个虚拟CPU内核和高达768GB的内存。可以将这些服务器设置在一个自动扩展组中,按所需的计算能力启动或停止数百个服务器而不会产生太多延迟。
Google Cloud数据中心
除了计算之外,云计算公司还为数据分析提供了完善的平台。Google Cloud提供了一个称为BigQuery的平台,该平台是无服务器计算(译者注:Serverless是一种构建和管理基于微服务架构的完整流程)且可扩展的数据仓库,使数据科学家能够在单个平台上存储和分析PB级的数据。BigQuery也可以连接到其他用于数据科学的谷歌云服务。使用Cloud Dataflow创建数据流传输管道,使用Cloud DataProc在数据上运行Hadoop或Apache Spark,或使用BigQuery ML在庞大的数据集上构建机器学习模型。
从数据到处理能力的一切都在增长,随着数据科学的成熟和数据量更加巨大,我们最终可能会完全在云上完成数据科学。
(4)自然语言处理
在深度学习研究领域取得重大突破之后,自然语言处理(NLP)已牢固地进入数据科学领域。
数据科学最初是对纯原始数据的分析,因为这是处理数据并将其收集在电子表格中最简单的方法。如果需要处理任何类型的文本,通常都需要将其分类或以某种方式转换为数字。
然而,将一段文本压缩为一个数字是非常困难的。自然语言和文本包含了丰富的数据和信息,由于缺乏将这些信息表示为数字的能力,因此我们常常会失去很多有用的信息。
深度学习在NLP中取得的巨大进步推动了NLP与常规数据分析的全面集成。现在,神经网络可以快速地从大量文本中提取信息。他们能够将文本分为不同的类别、确定关于文本的情感、并对文本数据的相似性进行分析。最后,所有这些信息都可以存储在单个数字特征向量中。
NLP已成为数据科学中的强大工具。巨大的文本数据存储,不仅可以是一个单词的答案,还可以包含完整的段落,可以转换为数值数据以进行标准分析。现在,我们可以探索更为复杂的数据集。
例如,假设有一个新闻网站想要查看哪些主题正在获得更多的观看次数。如果没有高级的NLP,那么所有关键词都将失去作用,或者只是一个预感:为什么一个特定的标题相对于另一个标题效果很好?使用NLP,我们可以量化网站的文本,比较整个文本甚至是网页的各个段落,以获得更全面的见解。
总结
整体而言,数据科学仍在发展,它将会嵌入每个行业(无论是技术行业还是非技术行业)以及每个业务(无论大小)。随着该领域的长期发展,看到它成为我们软件工具箱中的常用工具并被大众大规模使用使用也就不足为奇了。