今天我们就来一起学习下消息队列设计的底层模块, Broker 的架构设计。
Master Broker 与Slave Broker 消息如何同步
我们前面知道,要想 Broker 支持高可用,则将其设计成 主从架构,前面的分布式存储也讲了好多这种架构,可以自行查看历史文章哈。
首先,我们就来看第一个问题,为了保证我们的 MQ 里数据不丢失且还要支持该可用,所以我们就将 Broker 设计成 Master-Slave模式,即一个 Master Broker 对应着多个 Slave Broker 。
这样的好处就是,当我们Master Broker 接收到消息之后,它会将消息同步给 Slave ,那么即使Master Broker 宕机了话,Slave 上还是有数据的。
如上,我们思考一下,这个 Master Broker 是如何将数据同步给 Slave Broker 的?一般会有两种方案:
- Master Broker 主动推送消息给Slave Broker。
- Slave Broker 发送请求去 Master Broker 拉取消息数据。
我们采用第二种拉取的方案,比较靠谱一点,让 Slave Broker 不停的发送请求到 Master Broker 实现 pull 模式 拉取消息。
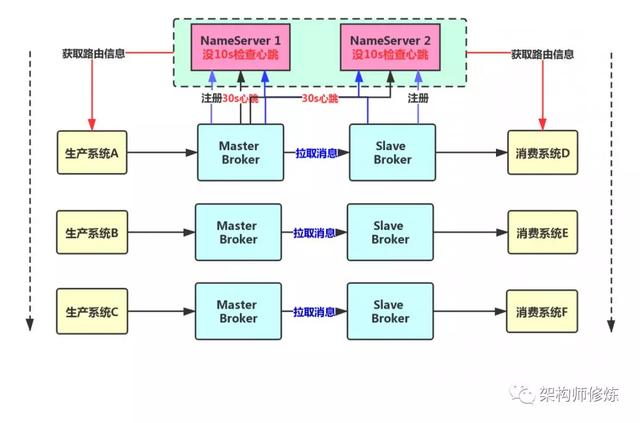
MQ 实现读写分离吗?
通过上面我们已经知道,Master Broker 主要用来接收消息的,然后会同步到 Slave Broker 中,因此 Slave Broker 也有一份一模一样的数据。
既然如此,那我们接下来一个问题是,消费者系统是从 Master Broker 中获取消息还是从Slave Broker 中获取呢?
其实我们不能那么简单从 master 还是 slave 中获取,应该更智能一点,既有可能去 Master 中获取也有可能从 Slave 中去获取。
作为消费者系统,在获取消息的时候会首先发送请求到 Master Broker 上去,然后Master Broker 会返回一批消息给消费者系统。
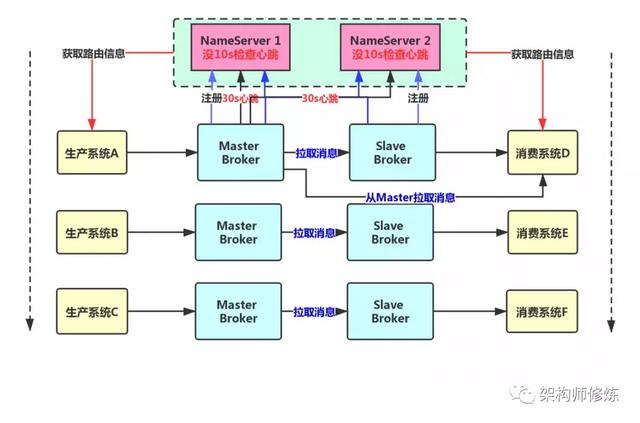
接着 Master Broker 在返回消息给消费者系统的时候,会根据自身负载情况以及和Slave 同步情况,向消费者系统建议下一次是从 Master Broker 获取还是 Slave Broker 中获取消息。
比如,现在Master 负载很重,本身要抗 10 万的写并发,然后你还要从它这里来获取消息,就会给 Master 带来更重的负担,那么Master Broker 就会建议你去Slave Broker 中去拉取消息。
还比如,现在Master Broker 收到了100 万条消息,结果Slave Broker 机器不知道怎么原因,才同步到 96 万条消息,落后了 4 万条消息数据,此时,作为消费者系统可能都获取到了 96 万条数据了,那么下次还是只能从Master 中拉取消息。因为,Slave Broker 同步消息太慢了,导致我们没法从那里获取最新的消息了。
所以,这一切都会由Master Broker 依据实际负载情况来决定从哪获取消息。

如图所示:
- 在写入消息的时候,一般肯定是选择 Master Broker 去写入的。
- 在消费消息的时候,是有可能在 Master Broker 中拉取 也有可能去 Slave Broker 中拉取的,视当时情况决定。
Slave Broker 挂了有何影响?
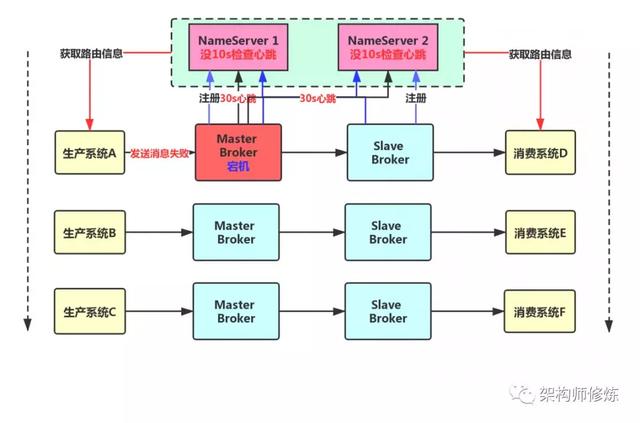
现在我们看下一个问题, 假如Slave Broker 挂掉了,会对我们整个系统有什么影响?影响是有一点的,但是不太大,无足畏惧。
因为消息在写入的时候是全部发到 Master Broker 上的,然后拉取消息的时候也可以走 Master Broker,只是有一些消息拉取可能是走 Slave Broker 上的。
所以,假如 Slave Broker 挂掉了,我们消息写入和获取都是可以走 Master Broker 的,是不会对我们整体系统造成大影响的。就是会可能导致Master Broker 读写压力增加。
Master Broker 挂掉了该怎么办?
上面我们分析了 Slave Broker 挂了并不影响整体系统,现在假设我们的 Master Brokker 抽风了挂掉了,会怎么样呢?
这个时候,对于消息的写入和获取就有一定影响了,但是就本质而言,Slave Broker 上是有一份数据的,只不过是有一些数据还没来得及从 Master Broker 中同步,一般我们就要设计 Slave Broker 自动接管 Master Broker 机制了,可以有两种方案解决:
- 人工运维,通过人手工切换
- 利用工具自动切换
手动切换
在 RocketMQ4.5 版本之前,都是这样的人工运维方式,当Master Broker 挂掉之后,人为的去修改配置,将 Slave Broker 进行相关修改,然后重启机器就给调整为 Master Broker,期间就是有点麻烦,而且会造成短时间的不可用。
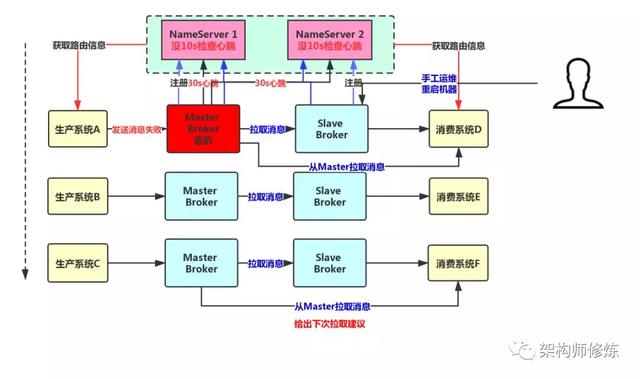
采用如上方式,并不能彻底的实现高可用,因为没办法自动将Slave Broker 升为 Master Broker。
基于Dledger 实现 MQ 自动切换
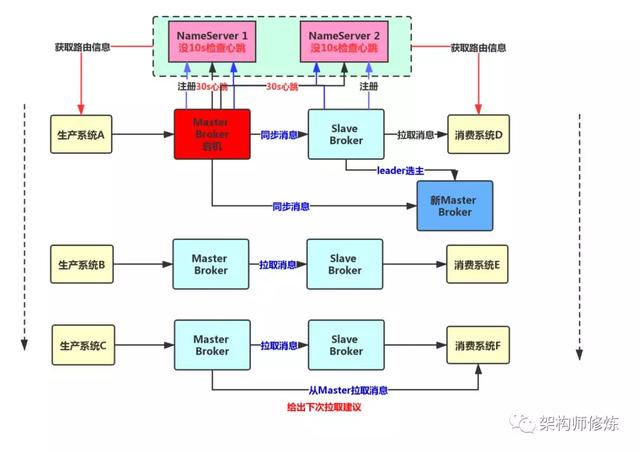
RocketMQ4.5 之后,开始引入新的机制,那就是Dledger,Dledger 是基于Raft 协议实现的机制,后面会单独对其底层原理进行详细讲解。我们先来看看基于Dledger 怎么实现 自动切换。
RocketMQ 引入 Dledger 之后,就可以让一个 Master Broker 对应多个 Slave Broker 也就是说一份数据会有多份副本。比如我们一个Master Broker 对应 两个 Slave Broker。
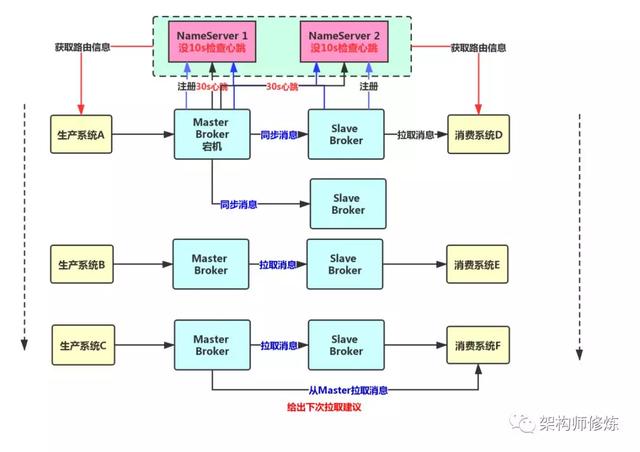
此时,如果一个Master Broker 宕机的话,还是会有多个 Slave ,然后通过Dledger 技术以及Raft 协议进行leader 选主,选主算法其实我前面有一篇专门讲了的,可以看看(面试是不是经常被问到分布式系统核心问题,这一次没人难倒你)。这样就会选出新的Master broker 对外提供服务。
如此一来,整个过程会很快,大概十几秒或者几十秒就能完成切换动作,完全的全自动的将Slave Broker 选为Master broker 对外提供服务,实现高可用模式。