【51CTO.com原创稿件】应用开发随着业务量的增加,数据量也在不断增加,为了应对海量的数据,通常会采用多线程的方式处理数据。
图片来自 Pexels
谈到 Java 的多线程编程,一定绕不开线程的安全性,线程安全又包括原子性,可见性和有序性等特性。今天,我们就来看看他们之间的关联和实现原理。
线程与竞态
开发的应用程序会在一个进程中运行,换句话说进程就是程序的运行实例。运行一个 Java 程序的实质就是运行了一个 Java 虚拟机进程。
如果说一个进程可以包括多个线程,并且这些线程会共享进程中的资源。任何一段代码会运行在一个线程中,也运行在多个线程中。线程所要完成的计算被称为任务。
为了提高程序的效率,我们会生成多个任务一起工作,这种工作模式有可能是并行的,A 任务在执行的时候,B 任务也在执行。
如果多个任务(线程)在执行过程中,操作相同的资源(变量),这个资源(变量)被称为共享资源(变量)。
当多个线程同时对共享资源进行操作时,例如:写资源,就会出现竞态,它会导致被操作的资源在不同时间看到的结果不同。
来看看多个线程访问相同的资源/变量的例子如下:
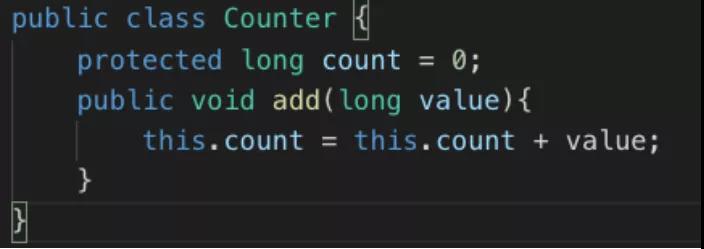
当线程 A 和 B 同时执行 Counter 对象中的 add() 方法时,在无法知道两个线程如何切换的情况下,JVM 会按照下面的顺序来执行代码:
- 从内存获取 this.count 的值放到寄存器。
- 将寄存器中的值增加 value。
- 将寄存器中的值写回内存。
上面操作在线程 A 和 B 交错执行时,会出现以下情况:

两个线程分别加 2 和 3 到 count 变量上,我们希望的结果是,两个线程执行后 count 的值等于 5。
但是,两个线程交叉执行,即使两个线程从内存中读出的初始值都是 0,之后各自加了 2 和 3,并分别写回内存。
然而,最终的值并不是期望的 5,而是最后写回内存的那个线程(A 线程)的值(3)。
最后写回内存的是线程 A 所以结果是 3,但也有可能是线程 B 最后写回内存,所以结果是不可知的。
因此,如果没有采用同步机制,线程间的交叉写资源/变量,结果是不可控的。
我们把这种一个计算结果的正确性与时间有关的现象称作竞态(Race Condition)。
线程安全
前面我们谈到,当多线程同时写一个资源/变量的时候会出现竞态的情况。这种情况的发生会造成,最终结果的不确定性。
如果把这个被写的资源看成 Java 中的一个类的话,这个类不是线程安全的。
即便这个类在单线程环境下运作正常,但在多线程环境下就无法正常运行。例如:ArrayList,HashMap,SimpledateFormat。
那么,为了做到线程安全,需要从以下三个方面考虑,分别是:
- 原子性
- 可见性
- 有序性
原子性
原子性是指某个操作或者多个操作,要么全部执行,要么就都不执行,不会出现中间过程。换成线程执行也一样,线程中执行的操作要么不执行,要么全部执行。
例如,在 Java 中,基本数据类型读取操作就是原子性操作,来看下面的语句:
- x = 10
- x = x + 1
第一句是原子性操作,因为其直接将数值 10 赋值给 x,线程执行这个语句时直接将 10 写到内存中。
第二句包含三个操作,读取 x 的值,进行加 1 操作,写入新的值。这三个操作合起来就不是原子性操作了。
Java 中的原子包括:
- lock(锁定)
- unlock(解锁)
- read(读取)
- load(载入)
- use(使用)
- assign(赋值)
- store(存储)
- write(写入)
假设 A,B 两个线程一起执行语句 2,同时对 x 变量进行写操作,由于不满足原子性操作,因此得到的结果也是不确定的。在 Java 中有两种方式来实现原子性。一种是使用锁(Lock)。
锁具有排他性,在多线程访问时,能够保障一个共享变量在任意时刻都能够被一个线程访问,也就是排除了竞态的可能。
另一种是利用处理器提供的 CAS(Compare-and-Swap)指令实现,它是直接在硬件(处理器和内存)这一层实现的,被称为“硬件锁”。
可见性
说完了原子性,再来谈谈可见性。名如其意,在多线程访问中,一个线程对某个共享变量进行更新以后,后续访问的线程可以立即读取更新的结果。
这种情况就称作可见,对共享变量的更新对其他线程是可见的,否则就称不可见。
来看看 Java 是如何实现可见性的。首先,假设线程 A 执行了一段指令,这个指令在 CPU A 中运行。
这个指令写的共享变量会存放在 CPU A 的寄存器中。当指令执行完毕以后,会将共享变量从寄存器中写入到内存中。
PS:实际上是通过寄存器到高速缓存,再到写缓冲器和无序化队列,最后写到内存的。
这里为了举例,采用了简化的说法。这样做的目的是,让共享变量能够被另外一个 CPU 中的线程访问到。
因此,共享变量写入到内存的行为称为“冲刷处理器缓存”。也就是把共享变量从处理器缓存,冲刷到内存中。
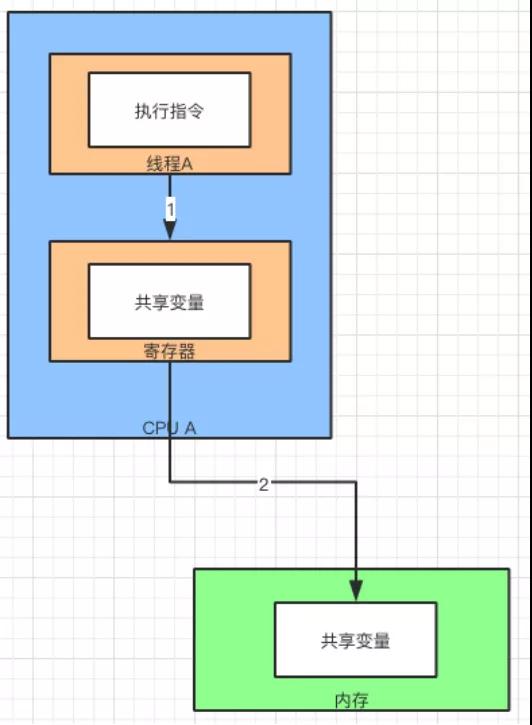
冲刷处理器缓存
此时,线程 B 刚好运行在 CPU B 上,指令为了获取共享变量,需要从内存中的共享变量进行同步。
这个缓存同步的过程被称为,“刷新处理器缓存”。也就是从内存中刷新缓存到处理器的寄存器中。
经过这两个步骤以后,运行在 CPU B 上的线程就能够同步到,CPU A 上线程处理的共享变量来。也保证了共享变量的可见性。
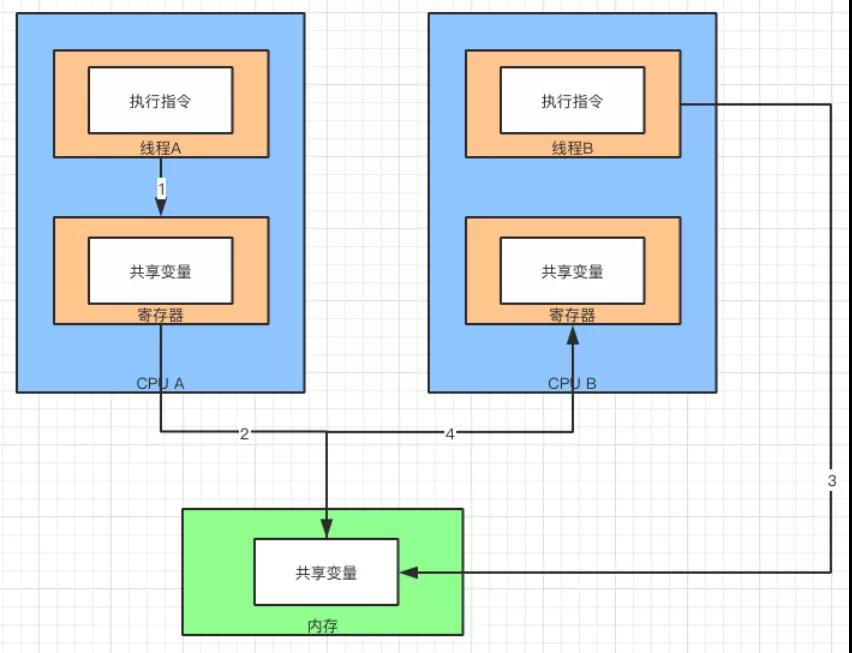
刷新处理器缓存
有序性
说完了可见性,再来聊聊有序性。Java 编译器针对代码执行的顺序会有调整。
它有可能改变两个操作执行的先后顺序,另外一个处理器上执行的多个操作,从其他处理器的角度来看,指令的执行顺序有可能也是不一致的。
在 Java 内存模型中,允许编译器和处理器对指令进行重排序,但是重排序过程不会影响到单线程程序的执行,却会影响到多线程并发执行的正确性。
究其原因,编译器出于性能的考虑,在不影响程序(单线程程序)正确性的情况下,对源代码顺序进行调整。
在 Java 中,可以通过 Volatile 关键字来保证“有序性”。还可以通过 Synchronized 和 Lock 来保证有序性。后面还会介绍通过内存屏障来实现有序性。
多线程同步与锁
前面讲到了线程竞态和线程安全,都是围绕多线程访问共享变量来讨论的。正因为有这种情况出现,在进行多线程开发的时候需要解决这个问题。
为了保障线程安全,会将多线程的并发访问转化成串行的访问。锁(Lock)就是利用这种思路来保证多线程同步的。
锁就好像是共享数据访问的许可证,任何线程需要访问共享数据之前都需要获得这个锁。
当一个线程获取锁的时候,其他申请锁的线程需要等待。获取锁的线程会根据线程上的任务执行代码,执行代码以后才会释放掉锁。
在获得锁与释放锁之间执行的代码区域被称为临界区,在临界区中访问的数据,被称为共享数据。
在该线程释放锁以后,其他的线程才能获得该锁,再对共享数据进行操作。
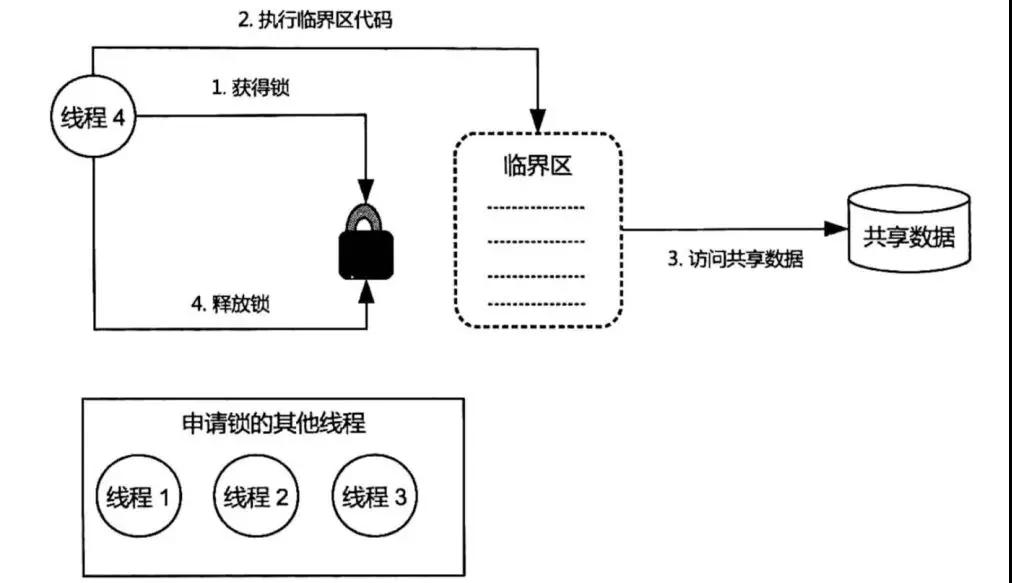
多线程访问临界区,访问共享数据
上面描述的操作也被称为互斥操作,锁通过这种互斥操作来保障竞态的原子性。
记得前面谈到的原子性吗?一个或者多个对共享数据的操作,要么完成,要么不完成,不能出现中间状态。
假设临界区中的代码,并不是原子性的。例如前文提到的“x=x+1”,其中就包括了三个操作,读取 x 的值,进行加 1 操作,写入新的值。
如果在多线程访问的时候,随着运行时间的不同会得到不同的结果。如果对这个操作加上锁,就可以使之具有“原子性”,也就是在一个线程访问的时候其他线程无法访问。
说完了多线程开发中锁的重要性,再来看看 Java 有那几种锁。
内部锁
内部锁也称作监视器(Monitor),它是通过 Synchronized 关键字来修饰方法及代码块,来制造临界区的。
Synchronized 关键字可以用来修饰同步方法,同步静态方法,同步实例方法,同步代码块。
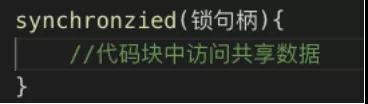
Synchronized 引导的代码块就是上面提到的临界区。锁句柄就是一个对象的引用,例如:它可以写成 this 关键字,就表示当前对象。
锁句柄对应的监视器被称为相应同步块的引导锁,相应的我们称呼相应的同步块为该锁引导的同步块。

内部锁示意图
锁句柄通常采用 final 修饰(private final)。因为锁句柄一旦改变,会导致同一个代码块的多个线程使用不同的锁,而导致竞态。
同步静态方法相当于当前类为引导锁的同步块。线程在执行临界区代码的时候,必须持有该临界区的引导锁。
一旦执行完临界区代码,引导该临界区的锁就会被释放。内部锁申请和释放的过程由 Java 虚拟机负责完成。
所以 Synchronized 实现的锁被称为内部锁。因此不会导致锁泄露,Java 编译器在将代码块编译成字节码的时候,对临界区抛出的异常进行了处理。
Java 虚拟机会给每个内部锁分配一个入口集(Entry Set),用于记录等待获取锁的线程。申请锁失败的线程会在入口集中等待再次申请锁的机会。
当等待的锁被其他线程释放时,入口集中的等待线程会被唤醒,获得申请锁的机会。
内部锁的机制会在等待的线程中进行选择,选择的规则会根据线程活跃度和优先级来进行,被选中的线程会持有锁进行后续操作。
显示锁
显示锁是 JDK 1.5 开始引入的排他锁,作为一种线程同步机制存在,其作用与内部锁相同,但它提供了一些内部锁不具备的特性。显示锁是 java.util.concurrent.locks.Lock 接口的实例。
显示锁实现的几个步骤分别是:
- 创建 Lock 接口实例
- 申请显示锁 Lock
- 对共享数据进行访问
- 在 finally 中释放锁,避免锁泄漏
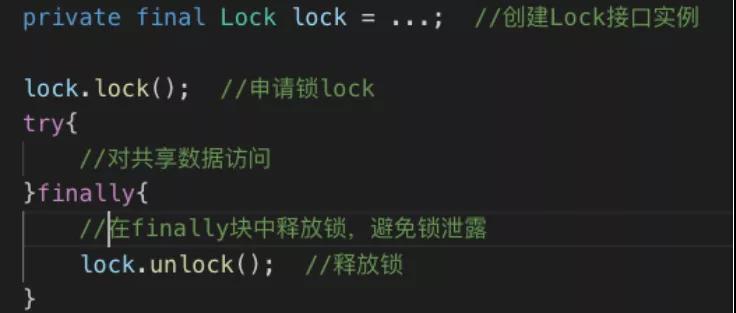
显示锁使用实例图
显示锁支持非公平锁也支持公平锁。公平锁中, 线程严格先进先出(FIFO)的顺序,获取锁资源。
如果有“当前线程”需要获取共享变量,需要进行排队。当锁被释放,由队列中排第一个的线程(Node1)获取,依次类推。
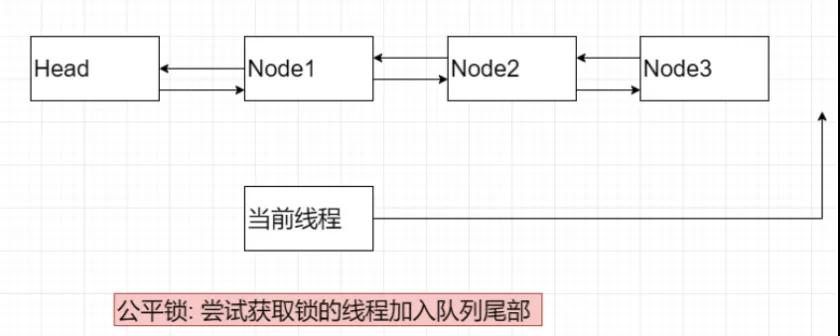
公平锁示意图
非公平锁中,在线程释放锁的时候, “当前线程“和等待队列中的第一个线程(Node1)竞争锁资源。通过线程活跃度和优先级来确定那个线程持有锁资源。
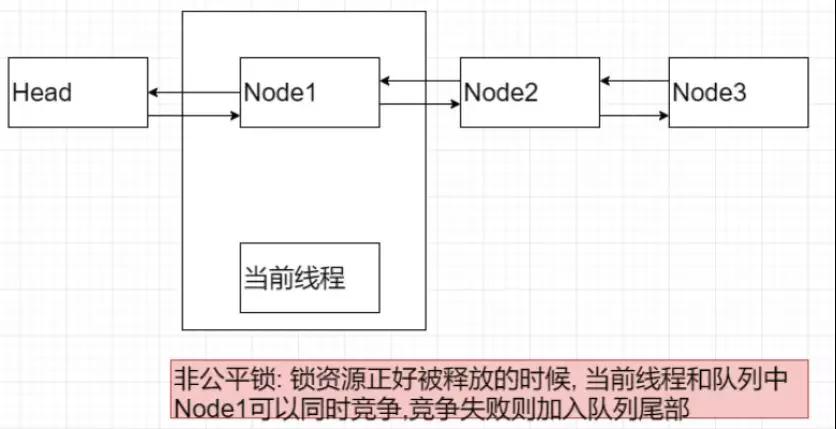
非公平锁示意图
公平锁保证锁调度的公平性,但是增加了线程暂停和唤醒的可能性,即增加了上下文切换的代价。非公平锁加入了竞争机制,会有更好的性能,能够承载更大的吞吐量。
当然,非公平锁让获取锁的时间变得更加不确定,可能会导致在阻塞队列中的线程长期处于饥饿状态。
线程同步机制:内存屏障
说了多线程访问共享变量,存在的竞态问题,然后引入锁的机制来解决这个问题。
上文提到内部锁和显示锁来解决线程同步的问题,而且提到了解决了竞态中“原子性”的问题。
那么接下来,通过介绍内存屏障机制,来理解如何实现“可见性”和“有序性”的。
这里就引出了内存屏障的概念,内存屏障是被插入两个 CPU 指令之间执行的,它是用来禁止编译器,处理器重排序从而保证有序性和可见性的。
对于可见性来说,我们提到了线程获得和释放锁时分别执行的两个动作:“刷新处理器缓存”和“冲刷处理器缓存”。
前一个动作保证了,持有锁的线程读取共享变量,后一个动作保证了,持有锁的线程对共享变量更新之后,对于后续线程可见。
另外,为了达到屏障的效果,它也会使处理器写入、读取值之前,将主内存的值写入高速缓存,清空无效队列,从而保障可见性。
对于有序性来说。下面来举个例子说明,假设有一组 CPU 指令:
- Store 表示“存储指令”
- Load 表示“读取指令”
- StoreLoad 代表“写读内存屏障”
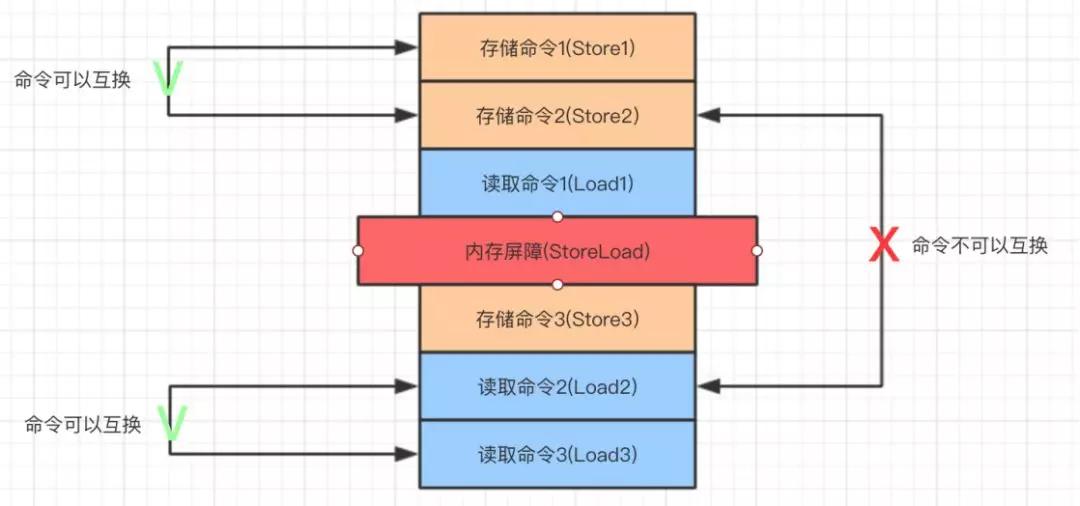
StoreLoad 内存屏障示意图
StoreLoad 屏障之前的 Store 指令,无法与 StoreLoad 屏障之后的 Load 指令进行交换位置,即重排序。
但是 StoreLoad 屏障之前和之后的指令是可以互换位置的,即 Store1 可以和 Store2 互换,Load2 可以和 Load3 互换。
常见有 4 种屏障:
- LoadLoad 屏障:指令顺序如:Load1→LoadLoad→Load2。 需要保证 Load1 指令先完成,才能执行 Load2 及后续指令。
- StoreStore 屏障:指令顺序如:Store1→StoreStore→Store2。需要保证 Store1 指令对其他处理器可见,才能执行 Store2 及后续指令。
- LoadStore 屏障:指令顺序如:Load1→LoadStore→Store2。需要保证 Load1 指令执行完成,才能执行 Store2 及后续指令。
- StoreLoad 屏障:指令顺序如:Store1→StoreLoad→Load2。需要保证 Store1 指令对所有处理器可见,才能执行 Load2 及后续指令。
这种内存屏障的开销是四种中最大的(冲刷写缓冲器,刷新处理器缓存)。它也是个万能屏障,兼具其他三种内存屏障的功能。
一般在 Java 常用 Volatile 和 Synchronized 关键字实现内存屏障,也可以通过 Unsafe 来实现。
总结
从线程的定义和多线程访问共享变量开始,出现了线程对资源的竞态现象。竞态会使多线程访问资源的时候,随着时间的推移,资源结果不可控制。
这个给我们的多线程编程提出了挑战。于是,我们需要通过原子性,可见性,有序性来解决线程安全的问题。
对于共享资源的同步可以解决这些问题,Java 提供内部锁和显示锁作为解决方案的最佳实践。
在最后,又介绍了线程同步的底层机制:内存屏障。它通过组织 CPU 指令的重排序解决了可见性和有序性的问题。
作者:崔皓
简介:十六年开发和架构经验,曾担任过惠普武汉交付中心技术专家,需求分析师,项目经理,后在创业公司担任技术/产品经理。善于学习,乐于分享。目前专注于技术架构与研发管理。
【51CTO原创稿件,合作站点转载请注明原文作者和出处为51CTO.com】