以下的分析主要针对etcd V3版本的实现。
概览
下图中展示了etcd如何处理一个客户端请求的涉及到的模块和流程。图中淡紫色的矩形表示etcd,它包括如下几个模块:
- etcd server:对外接收客户端的请求,对应etcd代码中的etcdserver目录,其中还有一个raft.go的模块与etcd-raft库进行通信。etcdserver中与存储相关的模块是applierV3,这里封装了V3版本的数据存储,WAL(write ahead log),用于写数据日志,etcd启动时会根据这部分内容进行恢复。
- etcd raft:etcd的raft库,前面的文章已经具体分析过这部分代码。除了与本节点的etcd server通信之外,还与集群中的其他etcd server进行交互做一致性数据同步的工作(在图中集群中其他etcd服务用橙色的椭圆表示)。
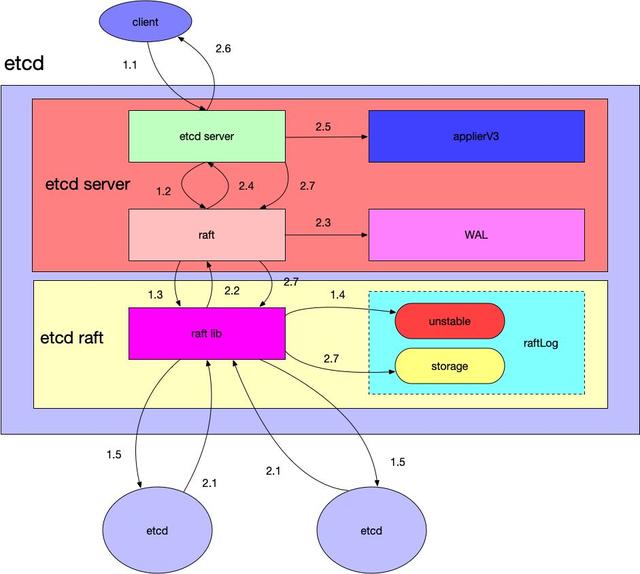
在上图中,一个请求与一个etcd集群交互的主要流程分为两大部分:
- 写数据到某个etcd server中。
- 该etcd server与集群中的其他etcd节点进行交互,当确保数据已经被存储之后应答客户端。
请求流程划分为了以下的子步骤:
- 1.1:etcd server收到客户端请求。
- 1.2:etcd server将请求发送给本模块中的raft.go,这里负责与etcd raft模块进行通信。
- 1.3:raft.go将数据封装成raft日志的形式提交给raft模块。
- 1.4:raft模块会首先保存到raftLog的unstable存储部分。
- 1.5:raft模块通过raft协议与集群中其他etcd节点进行交互。
注意在以上流程中,假设这里写入数据的etcd是leader节点,因为在raft协议中,如果提交数据到非leader节点的话需要路由到etcd leader节点去。
而应答步骤如下:
- 2.1:集群中其他节点向leader节点应答接收这条日志数据。
- 2.2:当超过集群半数以上节点应答接收这条日志数据时,etcd raft通过Ready结构体通知etcd server中的raft该日志数据已经commit。
- 2.3:raft.go收到Ready数据将首先将这条日志写入到WAL模块中。
- 2.4:通知最上层的etcd server该日志已经commit。
- 2.5:etcd server调用applierV3模块将日志写入持久化存储中。
- 2.6:etcd server应答客户端该数据写入成功。
- 2.7:最后etcd server调用etcd raft,修改其raftLog模块的数据,将这条日志写入到raftLog的storage中。
从上面的流程可以看到
- etcd raft模块在应答某条日志数据已经commit之后,是首先写入到WAL模块中的,因为这个模块只是添加一条日志,所以速度会很快,即使在后面applierV3写入失败,重启的时候也可以根据WAL模块中的日志数据进行恢复。
- etcd raft中的raftLog,按照前面文章的分析,其中的数据是保存到内存中的,重启即失效,上层应用真实的数据是持久化保存到WAL和applierV3中的。
以下就来分析etcd server与这部分相关的几个模块。
etcd server与raft的交互
EtcdServer结构体,负责对外与客户端进行通信。内部有一个raftNode结构的成员,负责与etcd的raft库进行交互。
etcd V3版本的API,通过GRPC协议与客户端进行交互,其相关代码在etcdserver/v3_server.go中。以一次Put请求为例,最后将会调用的代码在函数EtcdServer::processInternalRaftRequestOnce中,代码的主要流程分析如下。
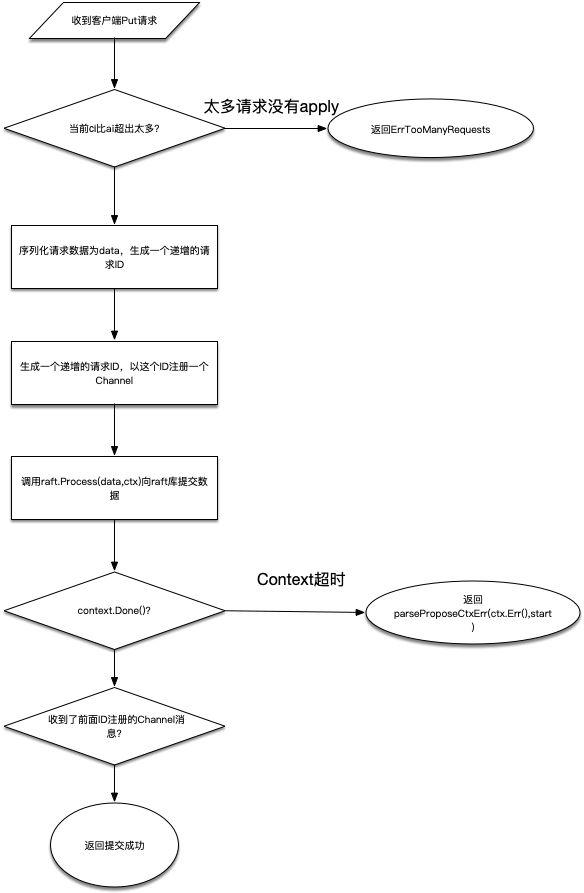
- 拿到当前raft中的apply和commit索引,如果commit索引比apply索引超出太多,说明当前有很多数据都没有apply,返回ErrTooManyRequests错误。
- 调用s.reqIDGen.Next函数生成一个针对当前请求的ID,注意这个ID并不是一个随机数而是一个严格递增的整数。同时将请求序列化为byte数据,这会做为raft的数据进行存储。
- 根据第2步中的ID,调用Wait.Register函数进行注册,这会返回一个用于通知结果的channel,后续就通过监听该channel来确定是否成功储存了提交的值。
- 调用Raft.Process函数提交数据,这里传入的参数除了前面序列化的数据之外,还有使用超时时间创建的Context。
- 监听前面的Channel以及Context对象: a. 如果context.Done返回,说明数据提交超时,使用s.parseProposeCtxErr函数返回具体的错误。 b. 如果channel返回,说明已经提交成功。
从以上的流程可以看出,在调用Raft.Process函数向Raft库提交数据之后,等待被唤醒的Channel才是正常提交数据成功的路径。
在EtcdServer.run函数中,最终会进入一个死循环中,等待raftNode.apply返回的channel被唤醒,而raftNode继承了raft.Node的实现,从前面分析etcd raft的流程中可以明白,EtcdServer就是在向raft库提交了数据之后,做为其上层消费Ready数据的应用层。
自此,整体的流程大体已经清晰:
- EtcdServer对外通过GRPC协议接收客户端请求,对内有一个raftNode类型的成员,该类型继承了raft.Node的实现。
- 客户端通过EtcdServer提交的数据修改都会通过raftNode来提交,而EtcdServer本身通过监听channel与raft库进行通信,由Ready结构体来通过EtcdServer哪些数据已经提交成功。
- 由于每个请求都会一个对应的ID,ID绑定了Channel,所以提交成功的请求通过ID找到对应的Channel来唤醒提交流程,最后通知客户端提交数据成功。
WAL
以上介绍了EtcdServer的大体流程,接下来看WAL的实现。
前面已经分析过了,etcd raft提交数据成功之后,将通知上面的应用层(在这里就是EtcdServer),然后再进行持久化数据存储。而数据的持久化可能会花费一些时间,因此在应答应用层之前,EtcdServer中的raftNode会首先将这些数据写入WAL日志中。这样即使在做持久化的时候数据丢失了,启动恢复的时候也可以根据WAL的日志进行数据恢复。
etcdserver模块中,给raftNode用于写WAL日志的工作,交给了接口Storage来完成,而这个接口由storage来具体实现:

可以看到,这个结构体组合了WAL和snap.Snapshotter结构,Snapshotter负责的是存储快照数据。
WAL日志文件中,每条日志记录有以下的类型:
- Type:日志记录类型,下面详细解释都有哪些类型。
- Crc:这一条日志记录的校验数据。
- Data:真正的数据,根据类型不同存储的数据也不同。
日志记录又有如下的类型:
- metadataType:存储的是元数据(metadata),每个WAL文件开头都有这类型的一条记录数据。
- entryType:保存的是raft的数据,也就是客户端提交上来并且已经commit的数据。
- stateType:保存的是当前集群的状态信息,即前面提到的HardState。
- crcType:校验数据。
- snapshotType:快照数据。
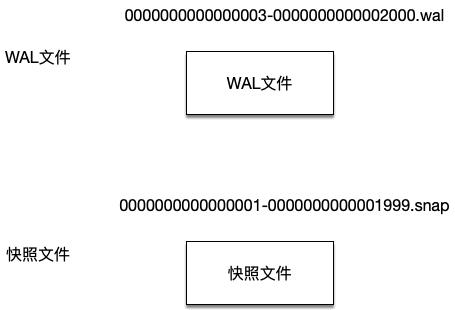
etcd使用两个目录分别存放WAL文件以及快照文件。其中,WAL文件的文件名格式是“16位的WAL文件编号-该WAL第一条entry数据的index号.wal”,这样就能从WAL文件名知道该WAL文件中保存的entry数据至少大于什么索引号。而快照文件名的格式则是“16位的快照数据最后一条日志记录任期号-16位的快照数据最后一条记录的索引号.snap”。
Etcd会管理WAL目录中的所有WAL文件,但是在生成快照文件之后,在快照数据之前的WAL文件将被清除掉,保证磁盘不会一直增长。
比如当前etcd中有三个WAL文件,可以从这些文件的文件名知道其中存放数据的索引范围。

在生成快照文件之后,此时就只剩一个WAL文件和一个快照文件了:
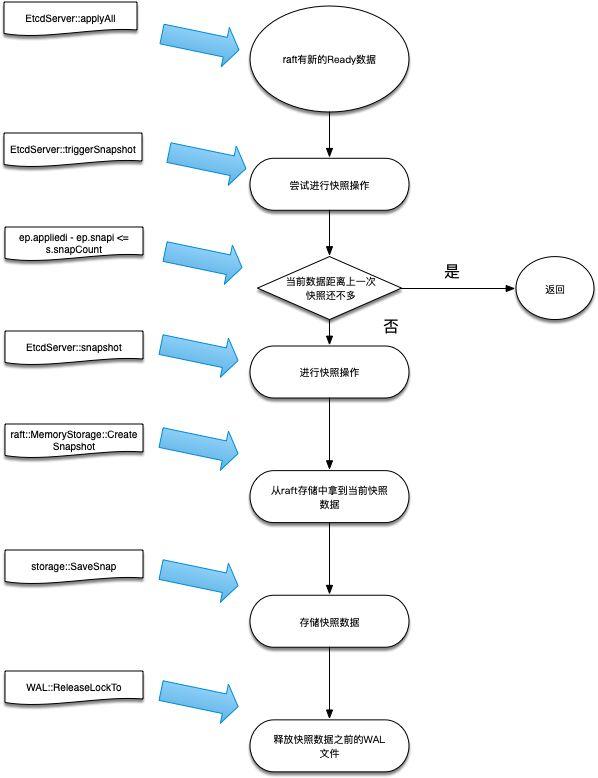
那么,又是在什么情况下生成快照文件呢?Etcdserver在主循环中通过监听channel获知当前raft协议返回的Ready数据,此时会做判断如果当前保存的快照数据索引距离上一次已经超过一个阈值(EtcdServer.snapCount),此时就从raft的存储中生成一份当前的快照数据,写入快照文件成功之后,就可以将这之前的WAL文件释放了。
以上流程和对应的具体函数见下面的流程图。
backend store的实现
revision概念
Etcd存储数据时,并不是像其他的KV存储那样,存放数据的键做为key,而是以数据的revision做为key,键值做为数据来存放。如何理解revision这个概念,以下面的例子来说明。
比如通过批量接口两次更新两对键值,第一次写入数据时,写入

而在第二次更新写入数据

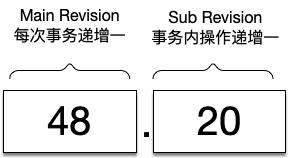
其中revision有两部分组成,第一部分成为main revision,每次事务递增1;第二部分称为sub revision,一个事务内的一次操作递增1。 两者结合,就能保证每次key唯一而且是递增的。
但是,就客户端看来,每次操作的时候是根据Key来进行操作的,所以这里就需要一个Key映射到当前revision的操作了,为了做到这个映射关系,Etcd引入了一个内存中的Btree索引,整个操作过程如下面的流程所示。

查询时,先通过内存中的btree索引来查询该key对应的keyIndex结构体,然后再根据这个结构体才能去boltdb中查询真实的数据返回。
所以,下面先展开讨论这个keyIndex结构体和btree索引。
keyIndex结构
keyIndex结构体有以下成员:
- key:存储数据真实的键。
- modified:最后一次修改该键对应的revision。
- generations:generation数组。
如何理解generation结构呢,可以认为每个generation对应一个数据从创建到删除的过程。每次删除key的操作,都会导致一个generation最后添加一个tombstone记录,然后创建一个新的空generation记录添加到generations数组中。
generation结构体存放以下数据:
- ver:当前generation中存放了多少次修改,其实就是revs数组的大小-1(因为需要去掉tombstone)。
- created:创建该generation时的revision。
- revs:存放该generation中存放的revision数组。
以下图来说明keyIndex结构体:
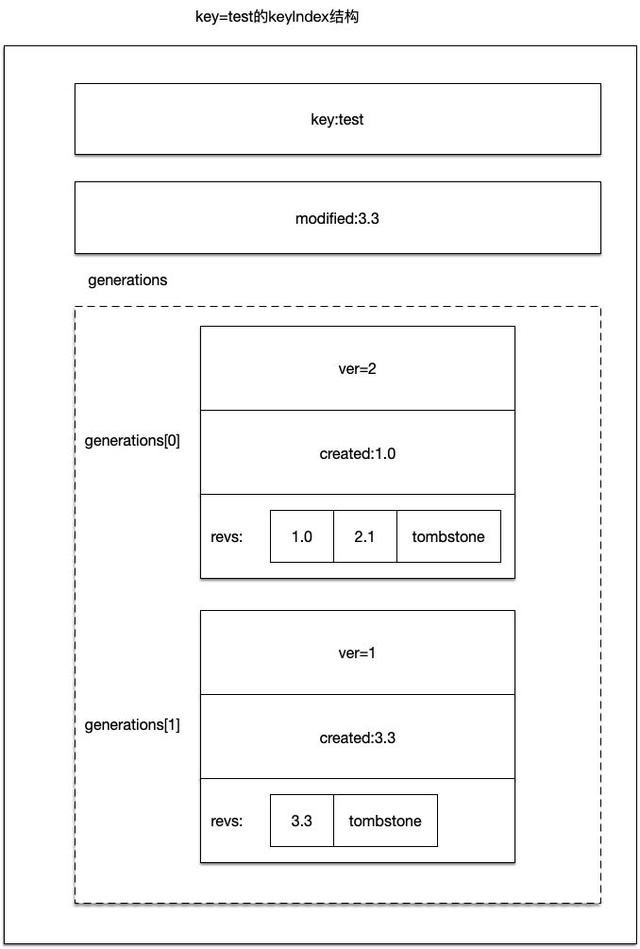
如上图所示,存放的键为test的keyIndex结构。
它的generations数组有两条记录,其中generations[0]在revision 1.0时创建,当revision2.1的时候进行tombstone操作,因此该generation的created是1.0;对应的generations[1]在revision3.3时创建,紧跟着就做了tombstone操作。
所以该keyIndex.modifiled成员存放的是3.3,因为这是这条数据最后一次被修改的revision。
一个已经被tombstone的generation是可以被删除的,如果整个generations数组都已经被删除空了,那么整个keyIndex记录也可以被删除了。
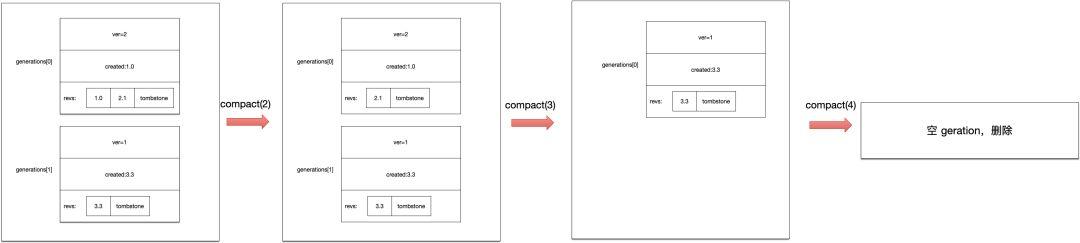
如上图所示,keyIndex.compact(n)函数可以对keyIndex数据进行压缩操作,将删除满足main revision < n的数据。
compact(2):找到了generations[0]的1.0 revision的数据进行了删除。
compact(3):找到了generations[0]的2.1 revision的数据进行了删除,此时由于generations[0]已经没有数据了,所以这一整个generation被删除,原先的generations[1]变成了generations[0]。
compact(4):找到了generations[0]的3.3 revision的数据进行了删除。由于所有的generation数据都被删除了,此时这个keyIndex数据可以删除了。
treeIndex结构
Etcd中使用treeIndex来在内存中存放keyIndex数据信息,这样就可以快速的根据输入的key定位到对应的keyIndex。
treeIndex使用开源的github.com/google/btree来在内存中存储btree索引信息,因为用的是外部库,所以不打算就这部分做解释。而如果很清楚了前面keyIndex结构,其实这部分很好理解。
所有的操作都以key做为参数进行操作,treeIndex使用btree根据key查找到对应的keyIndex,再进行相关的操作,最后重新写入到btree中。
store
前面讲到了WAL数据的存储、内存索引数据的存储,这部分讨论持久化存储数据的模块。
etcd V3版本中,使用BoltDB来持久化存储数据(etcd V2版本的实现不做讨论)。所以这里先简单解释一下BoltDB中的相关概念。
BoltDB相关概念
BoltDB中涉及到的几个数据结构,分别为DB、Bucket、Tx、Cursor、Tx等。
其中:
- DB:表示数据库,类比于Mysql。
- Bucket:数据库中的键值集合,类比于Mysql中的一张数据表。
- 键值对:BoltDB中实际存储的数据,类比于Mysql中的一行数据。
- Cursor:迭代器,用于按顺序遍历Bucket中的键值对。
- Tx:表示数据库操作中的一次只读或者读写事务。
Backend与BackendTx接口
Backend和BackendTx内部的实现,封装了BoltDB,太简单就不做分析了。
Lessor接口
etcd中没有提供针对数据设置过期时间的操作,通过租约(Lease)来实现数据过期的效果。而Lessor接口就提供了管理租约的相关接口。
比如,使用etcdctl命令可以创建一个lease:
etcdctl lease grant 10 lease 694d67ed2bfbea03 granted with TTL(10s)
这样就创建了一个ID为694d67ed2bfbea03的Lease,此时可以将键值与这个lease进行绑定:
etcdctl put --lease=694d67ed2bfbea03 a b
当时间还没超过过期时间10S时,能通过etcd拿到这对键值的数据。如果超时了就获取不到数据了。
从上面的命令可以看出,一个Lease可以与多个键值对应,由这个Lease通过管理与其绑定的键值数据的生命周期。
etcd中,将Lease ID存放在名为“lease”的Bucket中,注意在这里只存放Lease相关的数据,其键值为:
即:Lease这边需要持久化的数据只有Lease ID与TTL值,而键值对这边会持久化所绑定的Lease ID,这样在启动恢复的时候可以将两者对应的关系恢复到内存中。
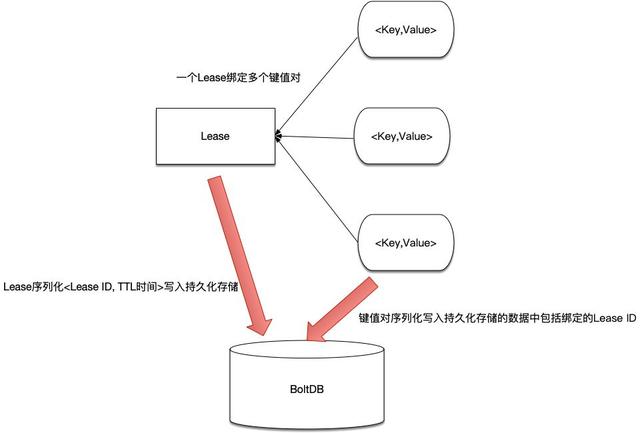
明白了以上关系再来理解Lessor的实现就很简单了。
lessor中主要包括以下的成员:
- leaseMap map[LeaseID]*Lease:存储LeaseID与Lease实例之间的对应关系。
- itemMap map[LeaseItem]LeaseID:leaseItem实际存放的是键值,所以这个map管理的就是键值与Lease ID之间的对应关系。
- b backend.Backend:持久化存储,每个Lease的持久化数据会写入名为“lease”的Bucket中。
- minLeaseTTL int64:最小过期时间,设置给每个lease的过期时间不得小于这个数据。
- expiredC chan *Lease:通过这个channel通知外部有哪些Lease过期了。
其他的就很简单了:
lessor启动之后会运行一个goroutine协程,在这个协程里定期查询哪些Lease超时,超时的Lease将通过expiredC channel通知外部。
而针对Lease的CRUD操作,都需要进行加锁才能操作。
KV接口
有了以上的准备,可以开始分析数据存储相关的内容了。在etcd V3中,所有涉及到数据的存储,都会通过KV接口。
store结构体实现了KV接口,其中最重要的就是封装了前面提到的几个数据结构:
- b backend.Backend:用于将持久化数据写入BoltDB中。
- kvindex index:保存key索引。
- changes mvccpb.KeyValue:保存每次写操作之后进行了修改的数据,用于通知watch了这些数据变更的客户端。
在store结构体初始化时,根据传入的backend.Backend,初始化backend.BatchTx结构,后面的任何涉及到事务的操作,都可以通过这个backend.BatchTx来进行。
其实有了前面的准备,理解store结构做的事情已经不难,以一次Put操作为例,其流程主要如下图所示:

applierV3
EtcdServer内部实现中,实际使用的是applierV3接口来进行持久化数据的操作。
这个接口有以下几个实现,但是其中applierV3backend的实现是最重要的,其内部使用了前面提到的KV接口来进行数据的处理。
另外,applierV3接口还有其他几个实现,这里分别列举一下。
- applierV3backend:基础的applierV3接口实现,其他几个实现都在此实现上做功能扩展。内部调用EtcdServer中的KV接口进行持久化数据读写操作。
- applierV3Capped:磁盘空间不足的情况下,EtcdServer中的applierV3切换到这个实现里面来,这个实现的任何写入操作都会失败,这样保证底层存储的数据量不再增加。
- authApplierV3:在applierV3backend的基础上扩展出权限控制的功能。
- quotaApplierV3:在applierV3backend的基础上加上了限流功能,即底层的存储到了上限的话,会触发限流操作。
综述
下图将上面涉及到的关键数据结构串联在一起,看看EtcdServer在收到Raft库通过Ready channel通知的可以持久化数据之后,都做了什么操作。
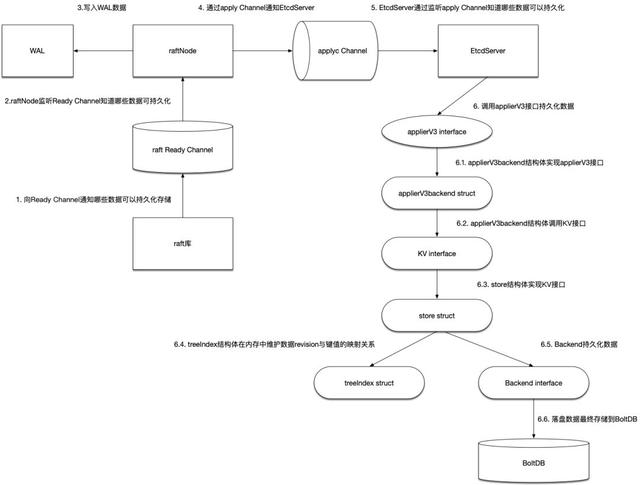
- raft库通过Ready Channel通知上层的raftNode哪些数据可以进行持久化。
- raftNode启动之后也是会启动一个Goroutine来一直监听这个Ready Channel,以便收到可以持久化数据的通知。
- raftNode在收到Ready数据之后,将首先写入WAL日志中。这里的WAL日志由storage结构体来管理,分为两大部分:WAL日志以及WAL快照文件数据Snapshotter,后者用来避免WAL文件一直增大。
- raftNode在写WAL数据完成之后,通过apply Channel通知EtcdServer。
- EtcdServer启动之后也是启动一个Goroutine来监听这个channel,以便收到可以持久化数据的通知。
- EtcdServer通过调用applierV3接口来持久化数据。applierV3backend结构体实现applierV3接口, applierV3backend结构体实现applierV3接口,内部通过调用KV接口进行持久化操作。而在实现KV接口的store结构体中,treeIndex负责在内存中维护数据键值与revision的对应关系即keyIndex数据,Backend接口负责持久化数据,最后持久化的数据将落盘到BoltDB中。