随着深度学习的发展,神经网络变得越来越大。例如,在ImageNet识别挑战中,获胜的模型在2012年到2015年间的大小增加了16倍。在短短一年的时间里,百度的深度语音模型的训练操作数增加了10倍。
一般来说,在嵌入式系统中深度学习有三个主要的挑战:
随着模型尺寸的增大,模型在手机上的部署变得更加困难。如果模型超过100 MB,(一般来说)只有连接到Wi-Fi才能下载。
训练速度变得极其缓慢。例如,与ResNet101相比,原始的ResNet152的准确率提升不到1%,它需要在4个分布式gpu上进行1.5周的训练。
如此庞大的模型也与能源效率斗争。例如,AlphaGo在围棋中击败李世石(Lee Sedol),需要训练1,920个cpu和280个gpu,用电成本约为3,000美元。
在这种情况下,在资源受限的设备上运行神经网络需要来自数据工程和数据科学的联合解决方案,这有时被称为“算法和硬件协同设计”。
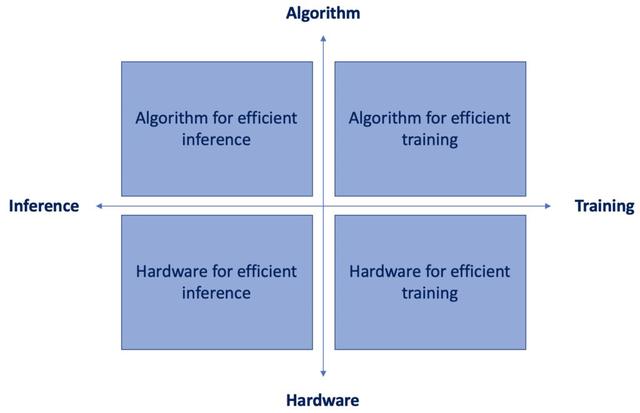
在本文中,我们只讨论象限的左上角。比较先进的推理算法是什么?
1.神经网络剪枝
与你所想的相反,剪枝与砍树无关。在机器学习中,为了得到一个更小、更快的网络,模型剪枝包括去除不重要的权重。
1989年,Yann Le Cun在他的论文“Optimal Brain Damage”中首次提出了模型剪枝。该思想是采取一个完全训练的网络,删除修剪权值将导致最小化的目标函数增加。各参数的贡献可用海森矩阵近似表示。一旦去除了不重要的权值,较小的网络就可以再次训练,这个过程可以重复几次,直到网络有一个令人满意的大小和一个合理的性能。
从那时起,大量的剪枝技术的变化发展起来。Han等人,2015年,在“Learning both Weights and Connections for Efficient Neural Networks”中,引入了一个三步方法,由神经网络的训练,然后修剪低于选择阈值的连接权值,最后再训练稀疏网络学习最后剩下的连接权重。
你可能想知道:如何确定剪枝阈值?好问题!卷积层和全连接层都可以修剪,然而,经验表明,卷积层比全连接层对剪枝更敏感。因此,需要根据各层的灵敏度选择阈值,如下图所示,该图取自Han等人的研究论文。
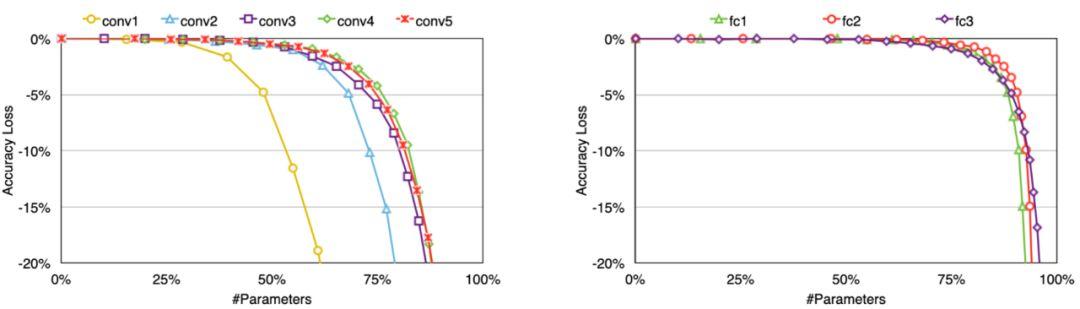
根据研究报告,在NVIDIA Titan X GPU上重新训练修剪过的AlexNet需要173个小时。但再训练时间不是一个关键问题,因为最终目标是让较小的模型在资源有限的设备上快速运行。
在ImageNet上,该方法将AlexNet的参数数量减少了9倍(从6100万个参数减少到670万个),将VGG-16的参数数量减少了13倍(从1.38亿个参数减少到1030万个)。经过剪枝后,AlexNet和VGGNet的存储需求大大降低,所有的权值都可以存储在芯片上,而不是存储在芯片外的DRAM上(访问DRAM需要消耗大量的能量)。
2 . 深度压缩
神经网络既需要大量计算,又需要大量内存,因此很难在硬件资源有限的嵌入式系统上部署它们。为了解决这个限制,“Deep Compression“论文,来自Han等,介绍了一个3步走的pipeline:剪枝,训练好模型的量化,霍夫曼编码,在共同努力下,减少神经网络的存储需求35 - 49倍,但是不影响其准确性。
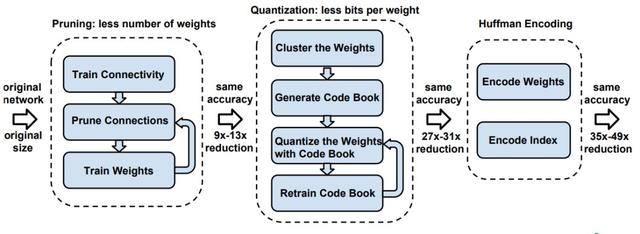
该方法首先通过只学习重要的连接来删除网络。接下来,该方法量化权重来执行权重共享。最后,该方法使用霍夫曼编码。在前两个步骤之后,作者对网络进行再训练,以调整剩余的连接和量化中心。剪枝将连接的数量减少9到13倍。量化后将代表每个连接的比特数从32减少到5。
在ImageNet上,该方法将AlexNet所需的存储空间减少了35倍(从240 MB减少到6.9 MB),并且没有造成精度损失。该方法还将VGG-16预训练模型的大小减少了49倍(从552 MB减少到11.3 MB),同时也没有精度损失。
最后,这种深度压缩算法有助于在移动应用程序中使用复杂的神经网络,而移动应用程序的大小和下载带宽都受到限制。在对CPU、GPU和移动GPU进行基准测试时,压缩后的网络具有3到4倍的分层加速和3到7倍的能效。
3 . 数据量化
近年来,基于卷积神经网络的方法在大量的应用中取得了巨大的成功,是计算机视觉中应用最广泛的架构之一。然而,基于cnn的方法是计算密集型和资源消耗的,因此很难集成到嵌入式系统中,如智能手机、智能眼镜和机器人。FGPA是一种很有前途的CNNs加速平台,但是有限的带宽和片上内存大小限制了CNNs FPGA加速器的性能。
清华大学研究人员的论文"Going Deeper with Embedded FPGA Platform for CNN"提出了一种用于ImageNet大规模图像分类的CNN嵌入式FPGA加速器设计方案。作者通过经验证明,在当前比较先进的CNN模型的架构中,卷积层是以计算为中心的,而全连接层是以内存为中心的。因此,他们提出了一种动态精确数据量化方法(如下图所示)来帮助提高带宽和资源利用率。
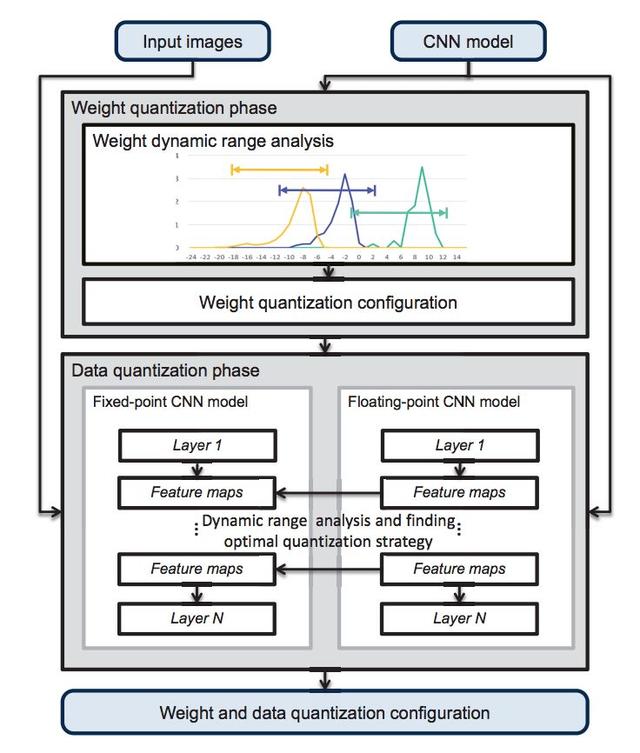
在该数据量化流中,任意两个定点数之间的分数长度对于不同的层和特征映射集是动态的,而对于同一层则是静态的,以最小化每一层的截断误差。
权值量化阶段的目标是找到一层权值的最优分数长度。在此阶段,首先分析各层权值的动态范围。然后,初始化分数长度以避免数据溢出。
数据量化阶段的目的是为两层之间的一组特征映射找到最优的分数长度。该阶段采用贪心算法对定点CNN模型和浮点CNN模型的中间数据进行逐层比较,以减少精度损失。
他们的结果(在进一步分析了不同的神经网络结构的不同策略之后)表明,动态精度量化比静态精度量化更有利。使用动态精确量化,他们可以使用更短的操作表示,同时仍然可以达到相当的精度。
4 .低秩估计
卷积神经网络的另一个问题是其昂贵的测试时间评估,这使得该模型在现实系统中不切实际。例如,一个云服务需要每秒处理数千个新请求,手机、平板电脑等移动设备大多只有cpu或低端gpu,一些识别任务,如物体检测,即使在高端GPU上,处理单个图像仍然很耗时。因此,加快CNNs测试时间的计算具有重要的现实意义。
微软亚洲研究院的"Efficient and Accurate Approximations of Nonlinear Convolutional Networks"论文提出了一种加速非线性卷积神经网络的方法。该方法以最小化非线性响应的重构误差为基础,采用低秩约束来减少计算量。为了解决具有挑战性的约束优化问题,作者将其分解为两个可行的子问题并迭代求解。然后,他们提出了最小化非对称重构误差的方法,有效地减少了多个近似层的累积误差。
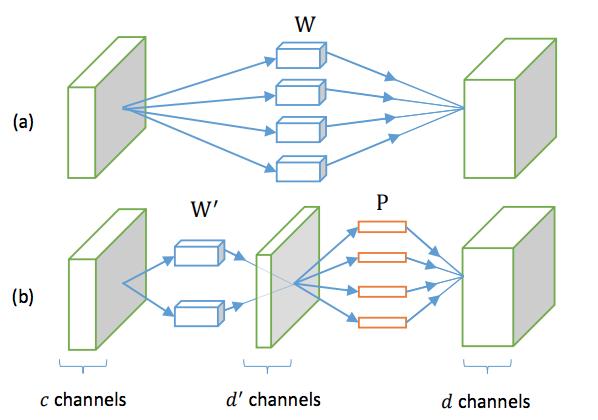
从左看,作者用W'和P替换原来的层W。实际上是d '滤波器的大小是k×k×c 。
这些滤波器产生一个d '维的特征图。在此特征图中,d-by-d '矩阵P可以通过1×1×d '实现。因此,P对应一个卷积层,它具有1×1的空间支持,将d '维特征映射到d维特征。
他们将这种低秩近似应用于为ImageNet训练的大型网络,并得出训练加速比增加了4倍的结论。事实上,与AlexNet相比,他们的加速模型执行的推断相对较快,但准确性提高了4.7%。
5 . 训练后的3值量化
另一种可以解决移动设备上有限功率预算下的大型神经网络模型部署问题的算法是训练后三值量化,它可以将神经网络中的权值精度降低到三元值。该方法精度下降很小,甚至可以提高部分模型在CIFAR-10和ImageNet上的精度。在本文中,AlexNet模型是从零开始训练的,这意味着它与训练一个正常的、全精度的模型一样容易。
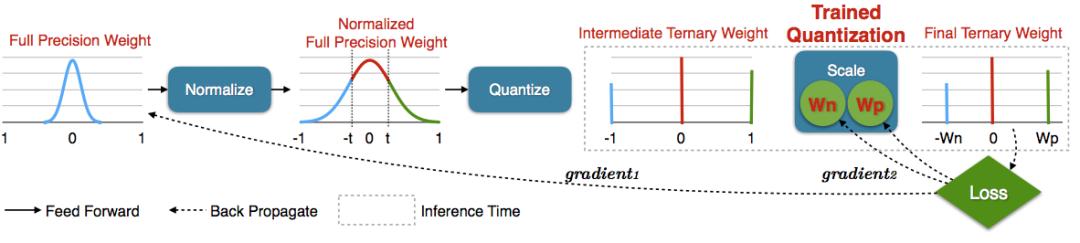
训练后的量化方法既可以学习三元的值,又可以学习三个值的分配,如上图所示。首先,作者通过将每个权值除以最大权值,将全精度权值规范化为[-1,+1]范围。
接下来,通过阈值化将中间全分辨率权重量化为{- 1,0,+1}。阈值因子t是一个超参数,为了减少搜索空间,它在所有层中都是相同的。
最后,他们通过反向传播两个梯度(短线)进行训练后量化:将gradient1传播到全分辨率权值,将gradient2传播到尺度系数。前者可以学习三元的值,后者可以学习三元值的分配。
他们在CIFAR-10上的实验表明,用这种经过训练的量化方法得到的三元模型分别比全精度的ResNet32、ResNet44、ResNet56模型的性能好0.04%、0.16%和0.36%。在ImageNet上,他们的模型比全精度的AlexNet模型的精度高0.3%,比之前的三元模型的精度高3%。
总结
我希望本文能帮助你认识到你正在使用的深度学习库背后使用了多少优化。这里介绍的这5种算法允许从业者和研究人员更有效地执行模型推断,从而在移动电话等小型边缘设备上实现了越来越多的实际应用。