2019年10月26日,由Testin主办的第二届NCTS中国云测试行业峰会在京召开,此次峰会以“AI+未来”为主题,汇聚来自国内外测试领域的知名专家学者、领先企业决策者、高层技术管理者、媒体从业者等,共同探讨高端云测试技术,帮助测试从业者了解最前沿行业趋势,及最新的行业实践。

会上,VIPKID性能测试方向负责人宁浩然做《千万级约课系统自动化压测实践》主题演讲。宁浩然分析了
VIPKID在链路压测过程中遇到的问题和挑战,介绍了自动化压测平台如何解决代码级定位链路上的性能问题,以及公司如何在无人值守的情况下完成自动化压测。他指出,“对于测试开发工程师,最重要的不是为了开发而开发,而是要发现工作过程中遇到的痛点问题,把那些可以重复化的或者可以用机器取代的工作通过技术手段替代掉,这才是我们主要的工作方向。”
以下为宁浩然演讲实录:
大家好,我是VIPKID的宁浩然,很高兴在这里给大家带来本次分享,我分享的主题是《千万级约课系统自动化压测实践》。我会基于VIPKID的特点,分析我们在链路压测过程中遇到的问题和挑战有哪些,简单介绍一下开发的自动化压测平台是如何解决代码级定位链路上的性能问题,以及我们如何敢在无人值守的情况下完成自动化压测。
首先简单介绍一下我们的业务,VIPKID目前的业务是在线教育。简单点来说,用户可以使用我们的软件进行课程预约,在约定的时间内通过视频的方式完成在线一对一线上上课。我们每周一中午会开放下周的课程预约,届时会有几十万的用户在短短1分钟时间内将下周要上的课全部约完,这种抢课模式给我们的系统造成了相当大的压力。每周一对于我们来讲都是一个大考。现在公司成立了专门的供需团队解决用户需求方面的问题,目前高峰期的流量已经有了一定程度上的缓解,所以本次分享我们会以业务和系统压力增长最快的2017-2018年为例,介绍我们是如何扛住每周一次的约课高峰。
从图里可以看到,我们在一年的时间里系统承载压力上涨了13倍左右,而单秒的约课量也达到了数千节,每周一这个“大考”,对于我们来说可以说是越来越严峻,而留给我们产研团队的时间永远只有一周。
挑战有哪些?首先可以看一下我们的约课链路,为了让我们的系统可以承载更高的压力,满足业务的增长预期,我们把链路上的每一个环节都做了调整或者优化,这些调整让我们的系统承载能力有了很大提高,但是在这个调整的过程中,无疑是非常痛苦的。我们上到ELB、SLB下到DB,每一次改动都有或多或少的隐患,这些隐患放到线上都是一种灾难,我们通过链路压测的方式把这些问题全部招回,保证我们近两年约课高峰期的稳定性,近两年共招回线上性能风险近百例。
总结一下,我们主要面临的挑战有以下几点:1、上线非常频繁,在座可能会说上线频繁算什么特点,作为互联网公司哪家上线不频繁呢?这里的上线有很大一部分都是服务重构、拆库拆表优化类的项目,这些改动都会影响我们核心的约课链路,所以每次的上线对于我们来讲都需要进行链路机的压测,当时平均每周大概需要压测2-3次,是链路级的。
同时由于我们的链路比较复杂,性能问题定位也是困难重重,对于我们来讲时间就是生命,我们需要在一周的时间内完成系统整体性能提高30%这个指标,这个数据是怎么来的呢?就是我们业务增长最快的一段时间里,每周的业务增长量就是30%左右。虽然我们做了一些整体的大规模的优化,来使我们的系统有一个质的提高,但是每周依然需要对特定服务或者接口做一些特定的优化。从设计再到开发,再到功能测试、到性能测试上线,我们只有一周的时间,这对于我们测试来讲,就需要有很高的速度方面的要求。我们当时给自己提出了一些指标,我们需要在一天的时间里完成数百个接口的准备工作,比如,当天提出了压测需求,当晚就要完成一个压测的实施。同时,当天压测如果发现问题,我们要在当晚就把这个问题做出一个初步的定位,因为我们一般是在周四或者周五进行压测,如果当天不定位,第二天就没有时间修复,紧接着马上就是高峰期了。
我们如何快速的准备呢?这个我会放在后面来说。
从2016年开始,我们对系统进行例行的链路压测,首先会统计周一高峰期的数据,然后确定下周的性能指标及我们的优化方向并进行压测实施,包括一些问题修复回归,这是我们每周都在例行去做的。从最开始的人工准备阶段,到现在我们已经可以通过平台进行自动化的压测,包括自动周一拉取数据、生成脚本、如果有问题我们自动停掉、没有问题或者发现什么问题自动生成报告,第二天研发和测试的同学来了直接分析就好,后面我会再具体介绍。
对于我们的平台来讲,主要的目的无非是提高我们的压测数据和脚本准备上的效率以及压测结果分析的效率。所以我们主要分为三块,首先压测准备,主要是压测脚本和数据的准备。对于脚本来讲,我们希望压测的比例可以和线上高峰期实际接口请求比例是一致的,同样我们可以通过简单的配置对系统压力进行等比的增减。对于一些不想要压测的接口可以支持将它过滤掉。而数据方面,我们希望压测数据有足够高的复杂度和样本量,同时我们又希望压测过程中不要影响到线上的真实用户。目前我们是通过拉取线上NG日志的方式,高峰期时间段、接口请求状况、响应时间、请求量等等,计算我们分给每个接口的新增数是多少,以此来生成我们的压测脚本,数据同样是用高峰期实际用户请求数据并对这些流量进行打标,在保证我们尽可能模拟线上真实情况的同时,也不影响到线上真实用户的使用。
结果分析这部分也是在压测过程中一个老大难的问题,比如,一次压测出现了一个问题,研发可能会先去NG日志或者是sever日志去查,有各个监控平台,CPU、数据库等等,这些数据明明我们都有,但是排查起来对于一线开发或者测试来讲常常会不知道如何入手。
我们的压测平台会把所有和本次压测相关的数据全部汇总起来,通过平台进行分析,然后给出一个定位的结论,我们收集的数据不仅有本次压测的,还包括往期、线上高峰期的数据,一是看本次有没有异常,第二也通过对比的方式更精准的定位系统链路上的问题。打个比方,比如,整个系统需要承载的压力是10万qps,其中一个接口线上要求它到1000,实际上到500的时候可能就不行了,这种问题常常在我们的链路压测过程中十分难暴露出来,因为它对我们系统整体的影响太小了,我们根本就看不出来,但是通过平台可以很快的通过分析,本次数据的接口响应时间或者是预期QPS和实际QPS把这一块的结果定位出来,这只是其中一种,还包括主机上面的问题等等,我们的报告不光体现出压测结果,更重要的是可以把这次出现的问题抽离或者压测出来,辅助我们快速的定位。
再一个很重要的点是监控,目前运维的监控平台是基于grafana做的,优点是扩展性、兼容性比较强,可以添加各种类型的监控,但是缺点是它的入口成本或者添加成本比较高,往往要加一个链路级的监控,会花费很长的时间,如果改动的话还要让运维提供,需要他们操作,因为一线人员具备操作这个东西的能力。对于我们压测来讲,其实我们并不需要一个监控平台有如此好的扩展性,我们更期望的是可以通过一个简单的配置就能快速的把我们的数据大盘给生成出来,方便我们定位就行了,我们每次关注的点并不会有什么变化,比如主机,就看看cpu、load等等这些值。所以,我们目前的做法是按照目前监控的类型,只要把你的服务名还有它的类型填好就可以快速的生成大盘。
另外一点,就是我们平常所加的监控可能在压测过程中不一定完全适用,比如平常主机、CPU设成70%就需要报警,因为我认为这可能是代表流量异常的情况,但是压测过程中可能就把这个数值轻松打破掉了。然后每次的链路压测都会收到大量的无用的报警,其实报警多了和没有报警就没有什么区别,没有人会看所有的报警内容。这样一些很严重的问题往往就会被掩盖掉了,所以在我们的监控平台里面会单独把这部分监控给抽离出来,也就是说每次开启压测这部分监控才会启动,这部分监控又分为报警监控、停止监控,这也是我们做自动化压测的一个基础。比如,我们达到某一个阈值,我们认为需要报警通知、需要排查问题。然后到服务器承载不了的时候会自动把它停掉。
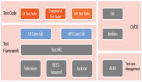
如图,这是我们平台设计的图,主要分为四个部分,一个任务调度处理模块主要负责各模块之间的调度任务,包括压测启停、监控开关等等。压测这块主要是接口还有数据方向上的准备,监控和报告服务就是刚才说的开启监控、停止减亏等等,还有生成报告的服务。数据来源主要有两个,一个是运维的监控平台,这块主要负责拿取各种的像主机、DB、还有一些信息,elk是日志平台,通过它拉取流量也可以根据线上流量情况进行数据的分析。
下面是我们平台使用的界面,首先,会先配置一下需要压哪个域名、哪个时间段的、总的Qps期望是多少,再就是添加一个监控,包括各个监控阈值。这些添加好之后,我们一键开始,剩下的工作全是平台来代替我们去生成脚本、去运行、去监控、去报告分析。
我们的报告维度也是比较多的,包括按域名维度、主机维度、接口维度的,还有一些下游接口的报告,看这个接口它下游的响应情况等等。如图,这是我们监控的快照,包括主机、数据库这四部分。这是我们结果分析的报告页,首先我们会把一些错误率比较高、响应时间比较长的一些接口拿出来,可以看它的问题点,点进去可以看它的单个接口,下游或者本层的响应情况。右边是Qps和RT的曲线,现在大部分的压测工具生成报告只有最高Qps、平均Qps、平均RT这样的数据,但是中间出现服务的抖动这种情况是看不到的,这种往往代表服务出现了一些问题,比如一次压测结果拿了监测值,当我们用线上的量去评估,可能往往带来的是一些误区。我们的报告里可以看到本次压测实际每秒的响应时间的情况和Qps情况,分为按服务级别、按域名级别、按接口级别的。
这是我们一个下游API的调用情况,比如,一次压测出现了,某个接口出现问题我们可以看它下游的情况是什么样的,可以把下游的异常接口抽离出来并代码级定位是在上游服务得哪行调用,和往期比,响应时间增加了,错误率高了等等这种情况,我们是通过重新封装组件来达到这一功能的。
下面来分享一个压测过程中的实际案例,对于一个让我们性能下降30%的性能问题,我们在10分钟内完成了链路问题的定位,并且修复上线了,当时情况是这样的,一次例行压测发现我们系统的总Qps下降了30%左右,而且当时已经没有一个很大规模的代码改动,顶多是一些业务上的需求上线,我们的自动化平台会第一时间定位出我们网络服务是入口IO有异常,入口IO已经基本上打满了,同时接口报告里发现是某一个下游接口响应时间较以往有一个很大的增长,我们可以看到这个接口的下游报告里面,下游调用的某一个接口也是响应时间急剧增加,我们还定位到了接口的调用位置,当时直接去那行代码发现这个确实是我们本周上线的,当时的情况是多取了一个无用的数据,可能是列表型接口,直接把详情数据取出来了,因为数据量比较大,直接把服务器的IO打满了,我们当时把这个无用字段删除掉了,然后再重新验证,符合预期。
这种问题其实如果是人工调查可能周期就会比较长,因为像网络入口IO打满这种问题,会导致所有的接口响应时间都会增长,在NG层查load来讲,每个接口响应时间都增长了,根本很难区分或者很难定位。
我们用平台不管在数据准备还有结果定位上都大大缩减了人力还有时间,可能会有人问,我们做一个平台什么时候做合适或者应不应该做?我认为对于咱们各个业务来讲,可能不一样,不一定每个公司都需要一个这样的平台。比如,你们的压测场景是单接口压测或者单服务,定位问题比较简单,或者用jmeter做这件事不一定比一个平台做这件事差到哪儿去,我感觉效果有可能是一样的,但是比如我们这种频繁的重复化的压测需求可能是比较适用的场景,对于测试开发工程师,最重要的不是为了开发而开发,而是要发现工作过程中遇到的痛点问题,把那些可以重复化的或者可以用机器取代的工作通过技术手段替代掉,这才是我们主要的工作方向。
希望这次的分享可以给大家带来一些帮助。