对于超级菜鸟来说,首要任务是要了解什么是数据分析?
数据分析是一种从数据中获取洞见,并驱动商业决策的知识发现行为。
这里分两点来讲,一是如何从数据中获取洞见?数据往往是冰冷的,不会说话,作为专业的数据分析人员,无疑是要具备非常丰富的业务知识,才能通过数据知道已经发生了什么?即将要发生什么?诸如python、excel、Fine BI是实现数据分析挖掘的重要工具,很多初学者往往重视工具,而忽略作为数据分析人员应该要具备的专业素养。
二是如何驱动商业决策?这可能不是普通数据分析师所能决定的层面,但作为优秀的数据分析人员,需要具备敏锐的商业眼光。单纯的数据分析结果是没有任何助益的,将分析结果与真实场景结合,产生有指导性的结论,才是一个数据分析师的价值所在。
我知道,大家很在意怎么去学习数据分析过程,对于python、R、sql、tableau、FineBI等等充满了疑惑和向往,这也是我当初接触数据分析时候的心态。很多东西要学,该学哪一样?怎么学习?学到什么程度?下面就要讲到数据分析工具。
分析工具的选择
一般来说,如果想要成为高阶的数据分析师,至少要掌握三类工具——自助式BI工具、取数工具、编程语言。这三类工具的选型标准都是不一样的,对于超级菜鸟来说,优先级是先学会自助式工具,保证能够尽快上手数据分析,掌握数据分析的基本知识;其次,再学一种取数工具,接触数据库的概念;最后,再高一等级要学会编程,甚至是数据分析库,具体选型我下面一一介绍。
1、自助式BI工具
什么叫做自助式分析工具呢?其实很简单,就是专门面向业务人员的BI分析工具,可以完全摆脱IT人的束缚,对于超级菜鸟来说,学习成本和门槛也比较低,能够很容易上手,独立完成数据分析工作。
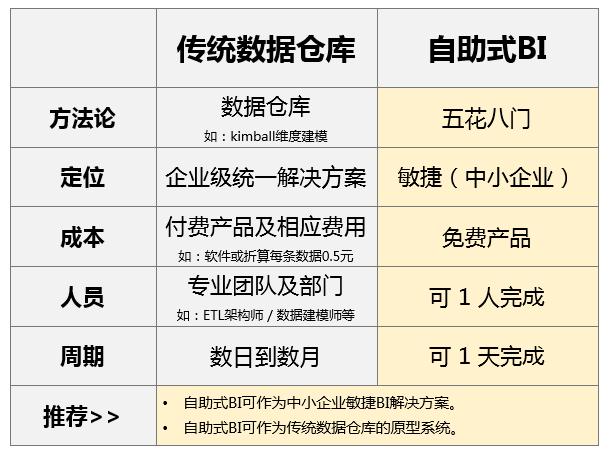
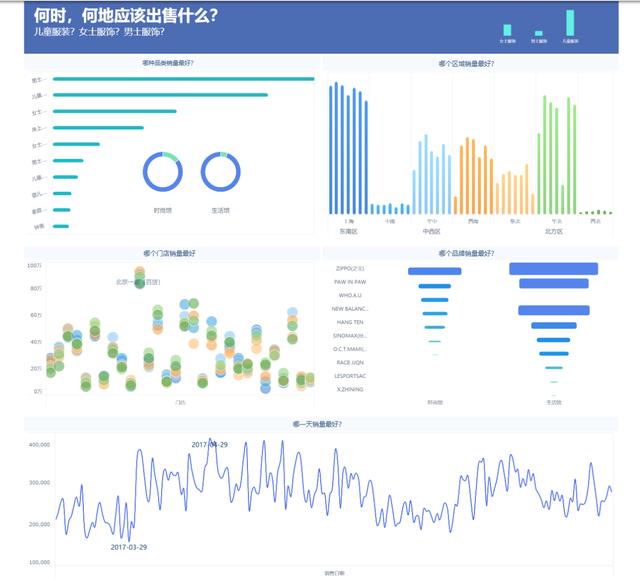
这里我推荐FineBI,它是一种能连接各类数据源,对原始数据(尤其是大数据量)进行快速分析,制作明细报表和酷炫可视化图表的工具,在IT信息部门分类准备好数据业务包的前提下,给与数据,让业务人员或领导自行分析,满足即席数据分析需求,是分析型产品。
其实FineBI的使用感同Tableau类似,都主张可视化的探索性分析,有点像加强版的数据透视表。上手简单,可视化库丰富。可以充当数据报表的门户,也可以充当各业务分析的平台。
而对于新手来说,FineBI的学习难度比较低,但是分析性能很强大,更重要的是个人版免费,完全可以支持个人进行自助式分析;即使你已经成为了企业的数据分析师,仍然需要FineBI来脱离IT部门,去IT化是一种大趋势,所以说不得不学。
2、取数工具
一般企业的数据保存在本地数据库或者公有云里,有的会采用mysql、oracle、mongodb等,有的会采用hbase、parquet等。我会建议初学者把sql学精,有余力者可以看看hbase、parquet等大数据存储方式。
sql是数据领域最常用的语言,无论是hive、spark、flink都支持sql,以至于机器学习也支持sql,像阿里开源的sqlflow。sql永不落伍。
3、编程语言
Python和R是数据分析领域的绝代双骄,我觉得这两个都适合作为数据分析的核心语言,但最好选择一个来学。
由于很多咨询我的人问的都是关于python的问题,我自己也是在用python工作,所以这里讲一下用python来做数据分析的利与弊。
python这几年的火爆程度堪称编程界的小鲜肉,虽然它诞生也快30年了,但风头正劲。作为一门高级编程语言,python除了不善于开发底层应用,几乎可以做任何事情。拿数据分析来说,从数据库操作、数据IO、数据清洗、数据可视化,到机器学习、批量处理、脚本编写、模型优化、深度学习,python都能完美地完成,而且提供了不同的库供你选择。
除此之外,Jupyter notebook是进行数据分析非常优秀的交互式工具,为初学者提供了方便的实验平台。
4、数据分析库
除了上面提高的三类工具,其实还有一类数据分析库,是比较适合高等数据分析师的,如果你还是一名刚刚入门的新手,可以忽略这一小节的内容。
pandas是一款不断进步的python数据科学库,它的数据结构十分适合做数据处理,并且pandas纳入了大量分析函数方法,以及常用统计学模型、可视化处理。如果你使用python做数据分析,在数据预处理的过程,几乎九成的工作需要使用pandas完成。
numpy是python的数值计算库,包括pandas之类的很多分析库都建立在numpy基础上。
numpy的核心功能包括:
- ndarray,一个具有矢量算术运算和复杂广播能力的快速且节省空间的多维数组。
- 用于对整组数据进行快速运算的标准数学函数(无需编写循环)。
- 用于读写磁盘数据的工具以及用于操作内存映射文件的工具。
- 线性代数、随机数生成以及傅里叶变换功能。
- 用于集成由C、C++、Fortran等语言编写的代码的A C API。
numpy之于数值计算特别重要是因为它可以高效处理大数组的数据。这是因为:
- 比起Python的内置序列,numpy数组使用的内存更少。
- numpy可以在整个数组上执行复杂的计算,而不需要Python的for循环。
matplotlib和seaborn是python主要的可视化工具,建议大家都去学学,数据的展现和数据分析同样重要。
sklearn和keras,sklearn是python机器学库,涵盖了大部分机器学习模型。keras是深度学习库,它包含高效的数值库Theano和TensorFlow。