分层架构,不就是建文件夹的艺术吗?
注:本文更适用于中大型项目,小项目开心就好了。因为时代的原因,对部分词汇描述可能不是那么准确,欢迎指正。
当我们开始一个新的项目,我们就开始创建一个个折文件夹。哦,不对,那我们在做分层架构设计。架构最后落到现有的计算机操作系统上,其的展示形式是分层架构。毕竟,硅基不如碳基。
可是呢,为什么我们要做分层架构设计呢?通过层(Layer)来隔离不同的关注点。
So,我要开始瞎扯了。
基本思想:关注点分离,划分边界
注:三层架构(controller-service-model)并非等于于 MVC 架构模式。对于其的错误等同,导致了架构上的一系列错误。
问题:落后的三层架构
过去,我总以为对于大部分项目来说,三层分层架构之外的部分是大泥球,即随意化的代码组织方式。然而,我发现对于大部分的项目来说,三层分层架构的 service 也是个大泥球,我忘记了三层分层架构的 model 层也是一堆大泥球。Controller 相对好一点,但是对于某些项目来说也是个小泥球。
大泥球是指一个随意化的杂乱的结构化系统,只是代码的堆砌和拼凑,往往会导致很多错误或者缺陷。
在今天 DDD + 整洁架构流行的今天, 三层分层架构已经完全不能满足现有应用的需求,甚至看上去一团糟糕。它存在这么一些问题:
- 统一管理是魔鬼,如 controller 文件夹下一堆的代码,到处乱放的 model。
- 缺乏明确的职责划分,如 controller 承担了 service 的职责
- 臃肿的 service,和贫血的 model
- 三层分层之后的随意文件组织方式,如 kafka 等到处乱放的代码
- ……
可是,为什么会这样呢?
- 职责(or 限界上下文)没有划分明确和清晰
- model 层存在大量的二义性
- 技术导向架构模式
- ……
于是,我们有了一些基本的解决方案,或者说是套路。
重新定义:消除二义性
当我们谈论 service 的时候,我们谈论的是同一个 service 吗?
当我们谈论 model 的时候,我们谈论的是同一种 model 吗?
若对于一个文法的某一句子存在两棵不同的语法树,则该文法是二义性文法。
如果有多种不同类型的类,都被放置在 model 包下。那么,你应该消除 model 这个包,改为更表意的名称,如 Entity、* Request、* Response 等等。同理,一旦你们展开对某个名称的讨论时,是时候好好考虑其中的二义性。
最后,你还需要有一个相关领域的名词表。
划分边界:业务导向架构
开始之前不得不说的是:
- 微服务是一种业务导向架构。
- 微服务是一种业务导向架构。
- 微服务是一种业务导向架构。
所以,如果你的微服务划分出现了不同的几个技术维度的服务,那么你需要好好反思一下。
So,为了迎接业务导向架构,我们需要以采用水平 + 垂直架构的方式来重新划分架构,将各业务模板的代码聚合到各自的业务模板中,顺便把大量地 util 和 common 内聚到服务中。而它们都基于其它低层模板。
随后,我们还可以尝试将单体应用拆分到微服务。
但是,我们都不应该依赖于低层模块,于是就有了……。
关注点分离:针对接口编程
我们看到了整洁架构:
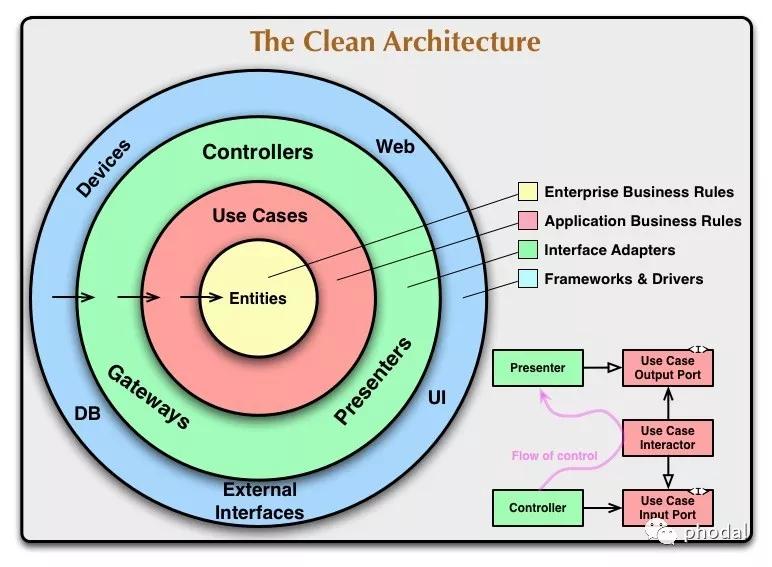
在其中有一个非常重要的原则:
依赖倒置原则:高层模块不应该依赖于低层模块,二者都应该依赖于抽象。
这一点在大部分的项目中,已经实践得相关的好。毕竟,有各种各样的 * Service + * ServiceImpl。
除此,为了实现这样的目标,对于采用 DDD 架构的应用来说,在我们的 domain 层的限界上下文,除了包含自身的 entity、vo 等,它应该还带有 repository 的抽象。这样一来,我们的 domain 层便不依赖
应用分层:DDD 与整洁架构
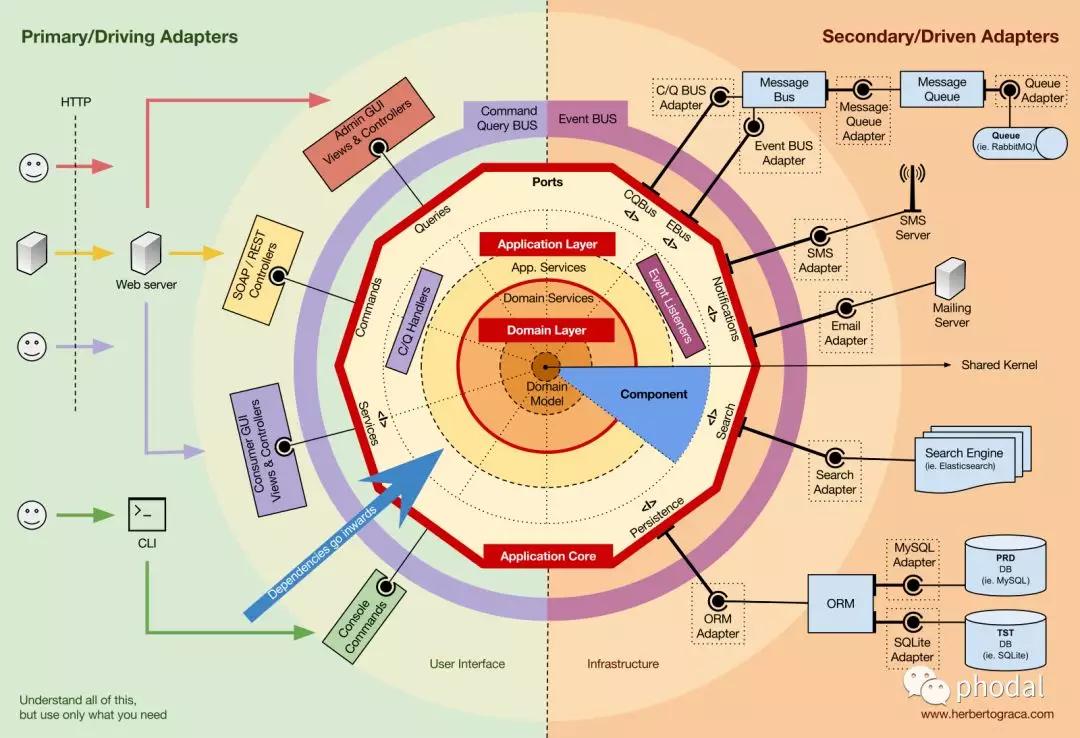
所以,让我们来看个问题。这是一个在 GitHub 上 star 数接近 15K 的 Java 语言编写的开源 CMS 中,某个模块的代码目录:
├── cms-admin/
├── cms-common/
├── cms-dao/
├── cms-job/
├── cms-rpc-api/
├── cms-rpc-service/
├── cms-search/
└── cms-web/
- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
这是一个技术导向的应用架构。所以,当我要新加一个功能的时候,我需要:
- 在 cms-dao 模块中加一个 model 和一个 mapper
- 在 cms-rpc-service 模块中加一个 service
- 在 cms-web 模块中中加一个 controller
“完美”,没有什么问题啊。
而随着时间的推移,你现在已经有一个巨大无比的 model 层,修改代码时需要在不同的模块跳转。而不能快速修改相关的代码。甚至于,你无法采用微服务架构,你是一个巨大的单体应用。
为了挽救这样的一个项目,我们不得不尝试做一些事情。
切割基础设施
你的基础设施自开发完成之后,基本不变,而你的业务代码一直在发生变化。
引起技术实现发生变化的原因与引起领域逻辑发生变化的原因显然不同,这就导致基础设施和领域逻辑问题会以不同速率发生变化。——《领域驱动设计模式、原理与实践》
当你来到一个项目一眼看到这么多基础设施相关的目录结构时:
├── controller
├── interceptor
├── jms
├── rocketmq
├── schedule
└── task
- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
有一天,我们又加了一个 Kafka,我们又不新加一个文件夹,而这样的分层设计看上去没有一点组织。然后呢,我们打开目录的时候,无法快速定位到我们的代码。
除了从目录上 infrastructure 包/层,容纳相关的基础设施代码。我们还要考虑到分层上的单一职责,因为需要剥离基础设施与业务代码的关系。所以,为了实现 Clean Architecture 的大业,你还需要一层抽象接口,比如你要访问存储业务相关的数据。那么抽象在你的 domain 中,具体的 RepositoryImpl 实现是在你的基础设施。
离心分离模型
在一个系统中,你会存在这么一些不同的 model:
(PS:部分描述可能不准确,欢迎指正)
- 与数据库表结构对应的 DO( Data Object)/ PO(Persistant Object)。
- 查询数据的 Query、Request。
- 对外传输的对象:DTO( Data Transfer Object)。
- 业务层之间的数据对象:VO(Value Object) / BO(Business Object)。
- 访问数据库的:DAO (Data Access Object数据访问对象)。
- 以及我们想要的 DDD 中的实体 Entity
- 还有其它的 POJO( Plain Ordinary Java Object)
但是它们都是 model,所以它们都被扔到 model 中……,又或者是 bean 中……。导致,你有了一个巨大比的 model 层。
所以,在 DDD 又或者是 Clean Architecture,我们重新命名了不同的模式:
- 使用 Command / Request 作为输入参数。其中的 Command 模式在完成后需要发出对应的 Event。
- 使用 Response / DTO / Representation 作为返回结果。
- 对 Entity 大家保持了一致的意见
- 还有 PO / DO 作为作为数据库的存储模型
- DAO 作为数据库的访问模型
- ……
不过,其实你只要不再让使用 model 和 bean,相似会有更多地收获。
以领域为核心,丰富行为
当完成了大坨的移动文件夹操作之后,我们来到了最麻烦和复杂的一部分。
我们需要对领域模型进行重新建模,重新规划 model 和 service,让 model 变成了富血模型。也许,你需要一场 Event Storming,才能完成真正意义的事件风暴建模。不过,步骤上也不会有太多的差异。
- 重新划分包。即在保持业务不中断的情况下重构,以让新的代码运行在新的架构上。
- 分析抽象领域模型
- 编写 API 测试,保证现有的功能
- 编写抽象接口,进行依赖反转
- 拆分 service 层,重构代码。将行为绑定于是领域对象上。
其它的情况,还要进行 case by case 的分析。
剩下的呢?
共享的业务逻辑,可以采用 sharedkernel,或者其它模式来处理。
待继续补充。
代码共用分层:功能内聚
创建通用的共享组件导致了一系列问题,比如耦合、协调难度和复杂度增加。
当我看到一个个巨大的 common 包时,我开始痛恨 common、 base、 util 这些该死的包,还有它们目录下统一管理的 bean。我们真的已经把它们用烂了,所以你应该重新审视一下你的项目代码。
所以,从这种意义上来说:复用与低耦合,本身存在一定的互斥关系。
base 下的 base
过去,我曾经重构过一个 base 项目的代码,正是这次重构让我意识到 base 并不是一个好东西。如果在项目中已经抽取出了一个 base 模块,那么这个模块下是不应该存在 base 这样的业务逻辑。而且,base 这个东西导致了一个问题是,只要是共用的东西就会不加思索的扔到 base 中。
你会有一个 base 的包,放着各种抽象接口,但是你需要一个更好的名字,比如 concepts,比如 support。
总之,你不应该存在 base 模块,让开发人员思考一下哪去放新的类。
无比臃肿的 bean 和 model
“这本身是怪不得程序员的,要怪就怪该死的 Java 语言。”
转而,我开始考虑一个问题,当个包(文件夹)下的文件数是否不应该超过一定的数量?
如果一个包下的类数,超过一定的范围,那么我们应该考虑是否存在职责相似的类。
这部分可以参考上一部分的离心分离模型。
什么不是 common
common 这个名字真的很烂,比 base 和 model 更烂。
一旦你从项目中拆出了一个 common 模块,那只会有一个结果,你将得到一个 5G 时代的 jar 包。甚至于,你看到有一块代码在 IDE 中是灰色的、未使用的,你也不敢轻易去删除这些代码。直到有一天,这个 common 包构建出来的大小有 10M、20M,而你只需要引用一个 AESUtil 的时候,你才发现了问题:原本几十 K 的 hello, world,现在变成了几十 M。
不要事先创建 common 模块,你可能不会有这个模块。
任何的水平分层拆分应用,在项目复杂化的今天都是不靠谱的。
谁用谁管理,而不是觉得是 common 就扔 common 模块。
它真是个 util 吗?
哦,不,它是个恶魔,因为它是 util。
你会往 xxUtil 不加思索地扔入逻辑,正如你会往 common/bean 中扔入所有的 model,直次有一天,你拥有一个巨大无比的 base、common 代码。
大多数情况下,所有和业务相关的 Util 都存在一定的问题,如 CaptchaUtil,它要么应该划到自己的上下文中去,要么扔到诸如于 domain/shared 等共享上下文,而不是和其它 util 放到一起。
而诸如 FileUtil、DateUtil、RedisUtil、JdbcUtil 这些都可以说是基础设施相关的部分,它们可以划到 infrastructure/file 又或者是 infrastructure/date 目录下,而不是统一的管理这些 util。
如 StackOverflow 的相关问题所列,我们还有诸如 Coordinator、Builder、Writer、Reader、Handler、Container、Protocol、Target、Converter、Controller、View、Factory、Entity、Bucket 等名称。
试着干掉 Util,你将收获更多的类,笑~。
需要个例子?
看看 Spring Framework 的源码的分层结构,如 Spring Orm:
└── orm
├── ObjectOptimisticLockingFailureException.java
├── ObjectRetrievalFailureException.java
├── hibernate5a/
├── jpa/
└── package-info.java
- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
又或者是 spring-context 下的目录分层结构:
└── springframework
├── cache
│ ├── annotation
│ ├── concurrent
│ ├── config
│ ├── interceptor
│ └── support
├── context
│ ├── annotation
│ ├── config
│ ├── event
│ ├── expression
│ ├── i18n
│ ├── index
│ ├── support
│ └── weaving
- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
- 9.
- 10.
- 11.
- 12.
- 13.
- 14.
- 15.
- 16.
它们都在自己的限界上下文内,维护自己的 annotaion、bean、support、i18n 等等的包。
分层架构重构
所以,我们可以尝试这么去做架构重构
- 分析、诊断现有项目结构
- 划分新的分层架构
- 功能测试
- 使用抽象解耦依赖
- 进行细粒度的代码重构
- 重新划分领域服务
还有吗?
- 不要预先设计,而是定义原则与规范。
- 以简单的设计开始,在生命周期中演进架构。
- 以多个 common 包,替代统一的 common 包
- TBC。
结论
那么,我们怎么才能做好分层架构呢?
by experience。
哦,不对,DDD 大法好。