概要
1、从职业发展看选型
2、选型原则一二三
3、选型路线图
本次分享主要有三个大的方向,一是从职业规划的角度看为什么我会认为数据库选型很重要,第二个方向会根据这些经验说说选型的基本原则是什么,最后总结一下这些年数据库选型的路线图,希望能对大家以后做数据库选型时有帮助,可以根据你们公司的场景进行套用,当然这不一定适合所有场景,主要还是提供思路以方便大家借鉴。
一、从职业发展看选型
DBA这个行业有很多年了,随着时间的变化职业规划也有着不同的变化。我放了一张DB-Engine的图,这是DB的排名,前三的就不说了,老三位没什么可聊的。但是看下面的排名,除了常见的数据库,还有ES、HBase、Neo4j这些我们之前不太认为是DBA管理范畴内的DB。
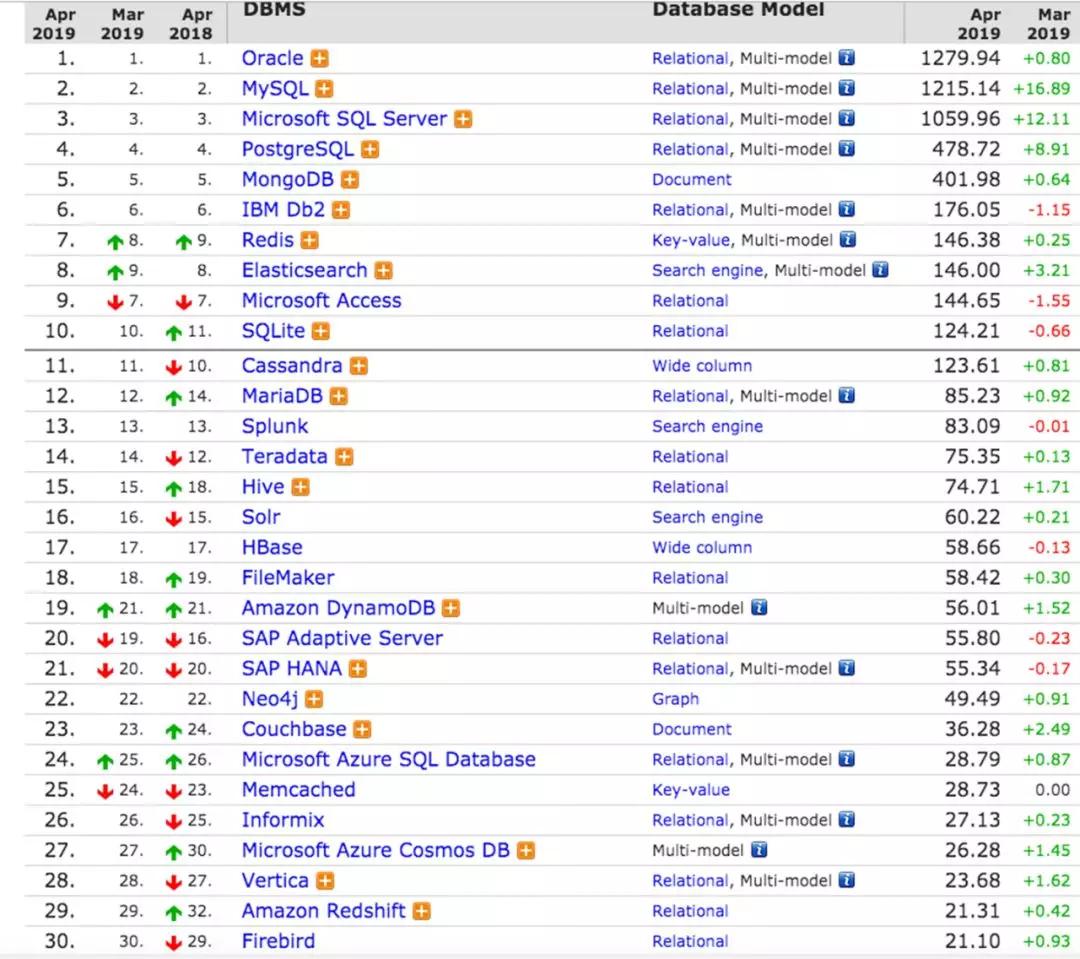
我经常跟团队小伙伴说咱们DBA的思维不要光局限于前面的老三位或者TOP5,我们是不是可以考虑到更多的数据库也是DBA可以从事的行业。比如你可不可以做HBase?你可不可以管理ES?这些东西都体现在这张表里,我们可以扩展自己职业的领域,这也是职业发展方向的一种横向扩展方式。
这张图是我对比去年和今年变化的展示图,去年关系型数据库(蓝色部分)占了半壁江山,今年关系型数据库仍然是第一,但是已经有很多份额被多用途的数据库占去了。
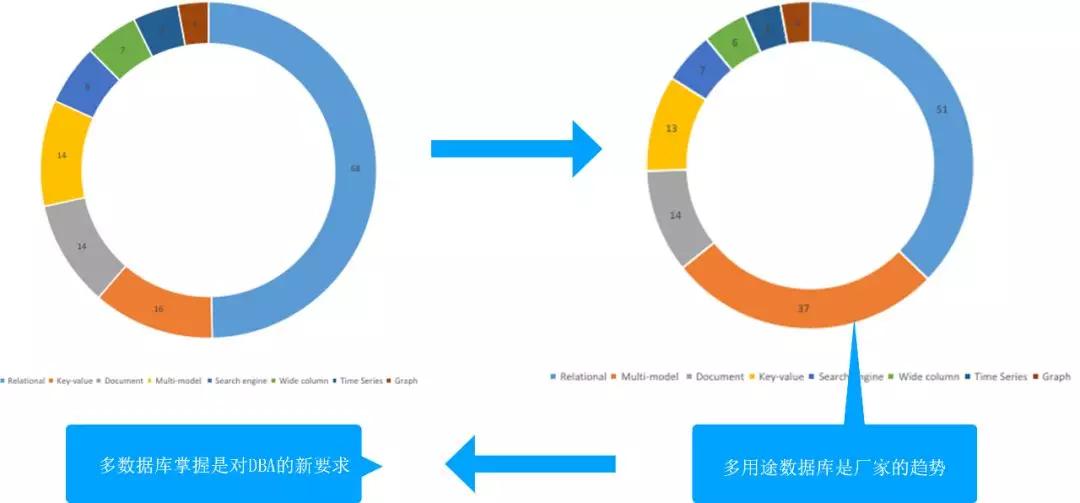
多用途数据库是厂商选择的趋势,他们研发了越来越多支持多用途的数据库。厂商为什么会这么做?供给侧的改变来源于需求侧,因为有很多需求已经不是单一的数据库能解决的了。
在这种场景下,厂商迫于这种需求开发了很多能适应更多场景的数据库。这种趋势对DBA来说意味着什么?这提醒我们,对多种数据库的掌握是现在这个时代对DBA的要求。
这是一个必然的发展趋势,因为你要解决的场景会越来越多,你需要掌握的数据库领域也越来越广,这就意味着之前「一招鲜」的玩法已经落伍了。
我们再看现在岗位的设置,往前其实是纯自建时代,现在的时代是云时代,这两个时代有着本质的区别。
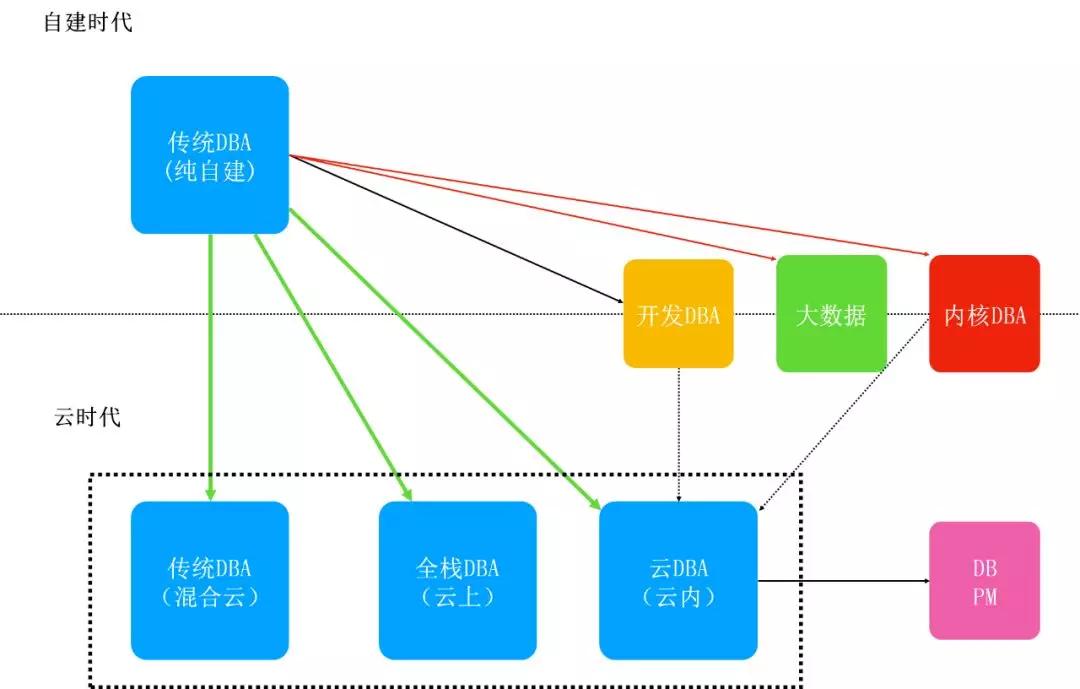
自建时代的DBA更多意义上是运维领域区分出来的一个更专业、门槛更高的职业领域,再往前都没有DBA,都是Ops管理的。后来出现DBA,再慢慢演化到DBA做一些细分,出现了开发DBA、内核DBA,还有部分同学转去专门做大数据,这就是在自建时代的整个状态。
但是云时代会有一些什么样的变化呢?其实自建时代的传统DBA现在还存在,因为有混合云的存在。那么变化是什么?是无论如何都不可能完全不谈云,一旦上云,自有的运维体系受到冲击是其次,主要还是业务可以选择的服务就多起来了。之前由于基础设施导致需要业务适配数据库的情况就会变成需要DBA掌握更多的数据库类型来满足业务了。
更有甚者是有的公司已经全部上云了,之前赖以生存的工作都变成了云服务,这时候的DBA要做什么转变?最后还有一种变化是云内DBA,作为云公司的DBA,孵化一个产品和提供对内服务又完全不是一回事。未来基本上我认为DBA就是这三个领域里面打转了(混合云DBA、云上DBA和云内DBA),但是无论哪种都需要掌握更多的数据库,这个是不变的。
综上,这个时代对DBA的要求就是需要掌握的数据库领域越来越多的,甭管你是在哪个线上的,都需要懂很多领域,至少精通一种,掌握N多种,这是我这次演讲想传递给大家的一个概念。
二、选型原则一二三
原则1:不讲场景的选型都是耍流氓
在座做过数据库选型相关工作的都知道场景很重要,但不是所有人都能把这个概念深入到骨子里。比如这个场景,我相信大家应该都有实际经历过。
你的用户对数据库的了解是没有DBA熟的,他的出发点跟你的出发点是不一样的,你想要的是长治久安,他想要的是把功能搞定。

如果你要做业务选型一定要对场景进行划分,如日志类、搜索类、离线需求等等,这些全部要跟线上分别开。业务模型是怎么样的?活动型还是规律型的,你是多读还是写多的?然后数据增长方式是怎样的,不能光满足上线一刹那的需求,业务增长是日期型的还是用户型的、位置型的?这些都需要跟你和业务聊清楚了,如果问不清楚,后期就面临一个最严重的问题:数据迁移。而数据迁移本身就可以成为一个主题,这就意味着这个事情会花费巨大的成本,如果能从初期就避免掉尽量从初期避免。
原则2:没有数据就没得聊
没法度量的东西就没法管,放在数据领域一样,没有数据就没法谈。
这是一个场景,你找业务聊天的时候一问三不知,经常会遇到,业务也确实没有办法。但我想说的是我们一定要让业务方拍出来的一个数据,因为我们所有的决策都是基于这些数据的,没有数据就没法决策。
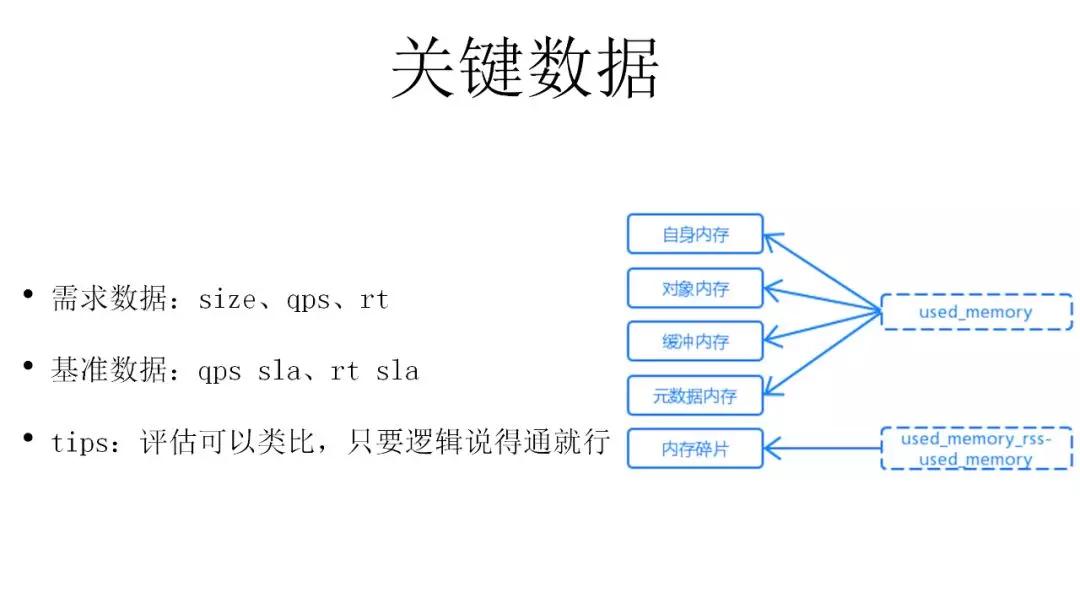
另外也期望可以让整个业务链条的同学养成有数据的习惯,评估多了自然就能积攒下来一些方法论来解决「拍数」的问题。这其中关键的几个点,也是最后选型图上关键的点,一个是size,第二个是qps,还有一个是rt。
另外我们还需要提供一些基准数据。什么叫基准数据,像刚才那个场景,你问业务,他一问三不知,还有一种情况是业务问你MySQL能扛多久,你说我也不知道,咱们先跑再说,这肯定是不行的。
你如果管理一个类型的数据库一定要对自己的东西有一个非常基准的认知,这个场景来了,我是给他做一主两从还是分布式,要不要上来就千库万表,还是用分区表等等,这些都一定要门清的。
最后有一个tips,评估是可以类比,只要逻辑说得通就行。来了一个需求你也说不清楚到底是多大量,你就看之前这个部门做没做过类似的活动,是在什么时间点做的,它跟你这个是什么样的逻辑,是否是近似的逻辑,如果是近似的逻辑我们就往上套。比如上次热点事件的峰值是多少,如果这个产品功能也可能和热点页面相关联,那么就按照上次热点事件的峰值进行对应的预估也算是符合逻辑的。
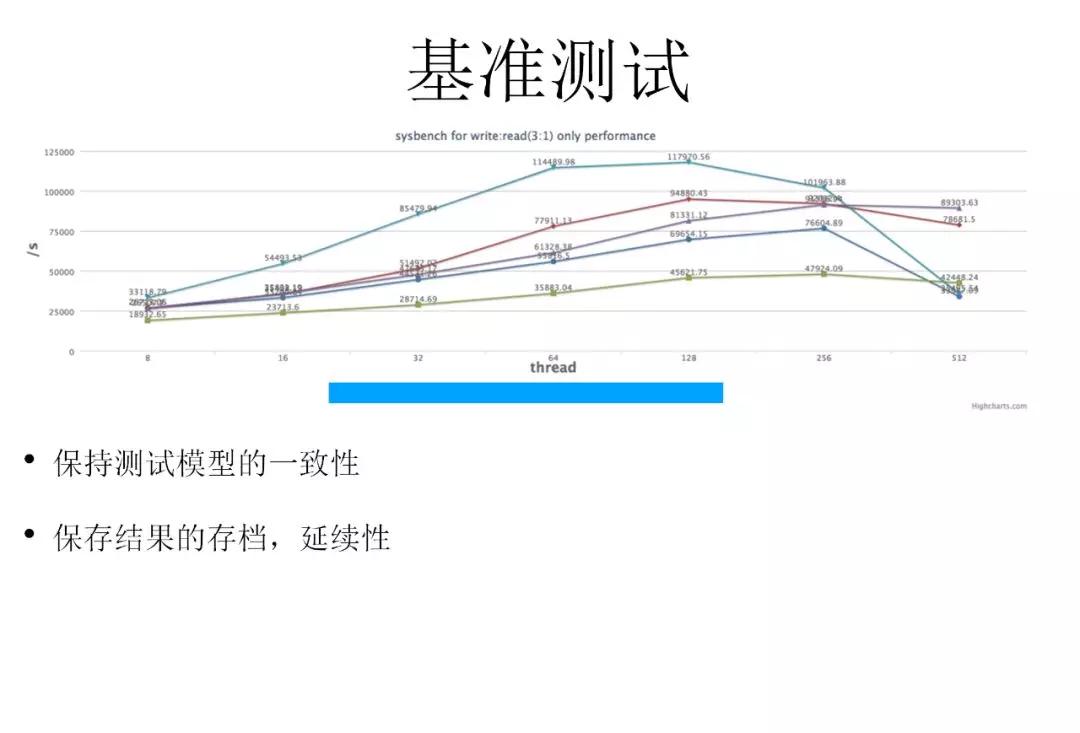
这里给大家展示一下基准测试,这是我们在做混合云运维解决方案时做的测试,因为我们需要用多家厂商的数据,需要门儿清,我把这个服务部署到那家云上性能到底有什么样的波动,也方便业务方对业务有更直观的理解和认知。
原则3:不考虑可运维性的都应该枪毙
最后一个原则跟前两个区别比较大,前两个原则基本都是知道的,但是难在落地。第三个原则其实很多DBA也不太关注,但真的是很重要的一个原则,那就是可运维性。
我开始说了,DBA跟业务方评估不一样,你的KPI也不一样,需求的点也不一样,业务要求上线,你要求可运维性,这关系到你的幸福度,关系到你的起夜率。如图的这个例子就很经典,业务和DBA双方根本没有在一个频道上沟通,最后只可能是不欢而散。
我认为的可运维性是什么?有四个方面:

一个是社区活跃度,社区活跃度决定着你获取信息的难易程度。获得信息的难易程度决定了什么?关系到你出现了故障的定位速度甚至是能不能定位出来,如果社区很活跃,自然就能得到更多的帮助。
第二个是有没有USER CASE,最好是自己认识的人,因为眼见为实,耳听为虚,认识的人往往能告诉你一些真实的「坑」,而不是宣传用的「功能」。
第三个是自身团队的情况、上手成本。你这个团队有多大,团队具备了什么样技术储备?毕竟你开辟一个新的战场,每一种数据库都不是这么简单的,可能三四个人都不见的搞得定,但是实际业务到底使用多少却说不清楚,这就很麻烦了。
最后一个是很隐性的事情,所谓的市场人才情况,这是可持续的成本。你如果选择了一种数据库,但如果市场对应的人才很少,那么一旦出现人员流失,就会让这种数据库处于无人维护的情况,这对于公司来说是绝对不允许发生的事情。
三、选型路线图
最后给大家聊一下选型路线图,如果你没有一个专门的DBA团队,云就是最好的选型,没有了。至于这几家之间他们到底谁好,我认为根据投资关系选更合适一点,至于原因你懂的。
再讲讲这个技术选型路线图,这是我根据这么多年团队经验做的一个选型路线图:
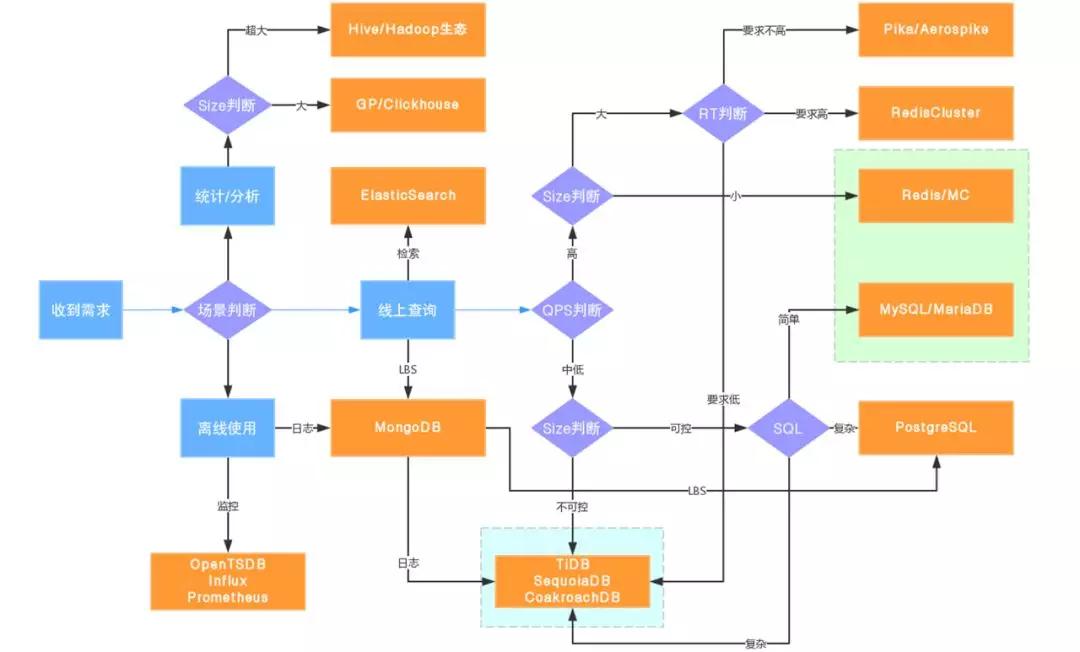
首先一定要做场景分析,到底是线上业务、离线业务还是统计类业务必须分出来,如果是离线的那么走hadoop生态,如果是统计监控类的可以走专门的时序数据库或者ES等,即使不走也要严格和线上的区分。
然后是线上,特殊需求走特殊的数据库更合适,如果是一个纯粹线上TOC端的产品需求,我们需要进行QPS的判断。如果是中低的QS那往下面走,根据size来判断扩展性,如果有高扩展需求那么选目前比较火的分布式数据库是个好选择,如果不高,那么再往下看SQL复杂程度,一般简单的互联网应用MySQL足以,如果是用了很多存储过程或者复杂大查询的,那么PG更适合一些。
返回刚才的分叉,如果QPS高的话,那么基本就是kv数据库的天下了,我们需要先根据size来判断,如果可控那么纯内存的kv数据库是最佳选择。接下来是基于RT的判断,如果size也大、rt要求也高,那就只有分布式内存kv数据库(RedisCluster)选,如果对于rt要求不那么高,那么Pika/Aerospike都是比较好的节省成本的选择。

最后说一下我们目前的最佳实践,我们目前常规需求都使用MySQL+Cache的方案解决,特殊需求交给云RDS去解决(比如PG、MongoDB等),并且选择了一种HTAP的分布式数据库来解决扩展性问题。
Q & A
Q:现在所谓的云原生DB比较流行,但是我们目前还没有使用到。一些宣传上说云原生DB是可以扩展的,并且和传统数据库也是类似的,我想问一下对于传统数据库来说它的不足在哪里?
A:这个不足点就是它要求升高了,分布式数据库的门槛变高了,对业务来说,在功能、扩展性上它现在是全面是超过了传统的数据库。但是对于DBA的要求来说,有非常高的门槛,这对我们之前的问题分析、调优、故障定位思路都会有很大的冲击。

讲师介绍
肖鹏,前新浪微博研发中心技术副总监,主要负责微博数据库(MySQL、Reids、HBase、Memcached)相关的业务保障、性能优化、架构设计,以及周边的自动化系统建设。经历了微博数据库各个阶段的架构改造,包括服务保障及SLA体系建设、微博多机房部署、微博平台化改造等项目。10年互联网数据库架构和管理经验,专注于数据库的高性能和高可用技术保障方向。