












1.Redis Cluster的基本概念
集群版的Redis听起来很高大上,确实相比单实例一主一从或者一主多从模式来说复杂了许多,互联网的架构总是随着业务的发展不断演进的。
- 单实例Redis架构
最开始的一主N从加上读写分离,Redis作为缓存单实例貌似也还不错,并且有Sentinel哨兵机制,可以实现主从故障迁移。
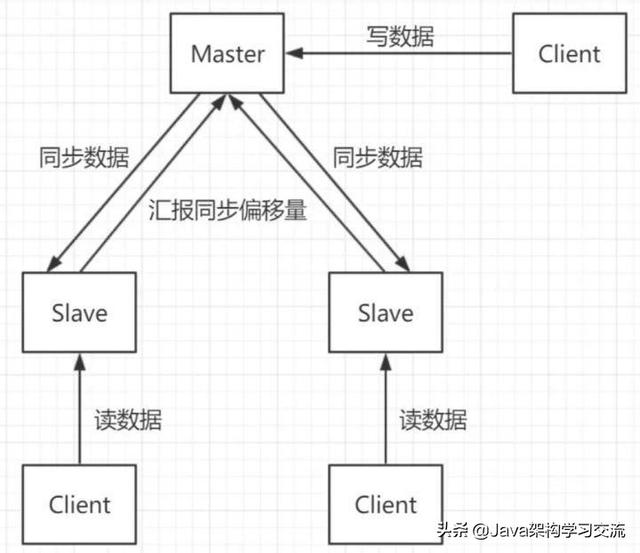
单实例一主两从+读写分离结构:
注:图片来自网络
单实例的由于本质上只有一台Master作为存储,就算机器为128GB的内存,一般建议使用率也不要超过70%-80%,所以最多使用100GB数据就已经很多了,实际中50%就不错了,以为数据量太大也会降低服务的稳定性,因为数据量太大意味着持久化成本高,可能严重阻塞服务,甚至最终切主。
如果单实例只作为缓存使用,那么除了在服务故障或者阻塞时会出现缓存击穿问题,可能会有很多请求一起搞死MySQL。
如果单实例作为主存,那么问题就比较大了,因为涉及到持久化问题,无论是bgsave还是aof都会造成刷盘阻塞,此时造成服务请求成功率下降,这个并不是单实例可以解决的,因为由于作为主存储,持久化是必须的。
所以我们期待一个多主多从的Redis系统,这样无论作为主存还是作为缓存,压力和稳定性都会提升,尽管如此,笔者还是建议:
如果你一意孤行,那么要么坑了自己,要么坑了别人。
- 集群与分片
要支持集群首先要克服的就是分片问题,也就是一致性哈希问题,常见的方案有三种:
客户端分片:这种情况主要是类似于哈希取模的做法,当客户端对服务端的数量完全掌握和控制时,可以简单使用。
中间层分片:这种情况是在客户端和服务器端之间增加中间层,充当管理者和调度者,客户端的请求打向中间层,由中间层实现请求的转发和回收,当然中间层最重要的作用是对多台服务器的动态管理。
服务端分片:不使用中间层实现去中心化的管理模式,客户端直接向服务器中任意结点请求,如果被请求的Node没有所需数据,则像客户端回复MOVED,并告诉客户端所需数据的存储位置,这个过程实际上是客户端和服务端共同配合,进行请求重定向来完成的。
- 中间层分片的集群版Redis
前面提到了变为N主N从可以有效提高处理能力和稳定性,但是这样就面临一致性哈希的问题,也就是动态扩缩容时的数据问题。
在Redis官方发布集群版本之前,业内有一些方案迫不及待要用起自研版本的Redis集群,其中包括国内豌豆荚的Codis、国外Twiter的twemproxy。
核心思想都是在多个Redis服务器和客户端Client中间增加分片层,由分片层来完成数据的一致性哈希和分片问题,每一家的做法有一定的区别,但是要解决的核心问题都是多台Redis场景下的扩缩容、故障转移、数据完整性、数据一致性、请求处理延时等问题。
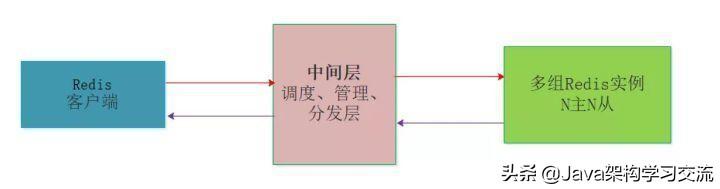
业内Codis配合LVS等多种做法实现Redis集群的方案有很多都应用到生成环境中,表现都还不错,主要是官方集群版本在Redis3.0才出现,对其稳定性如何,很多公司都不愿做小白鼠,不过事实上经过迭代目前已经到了Redis5.x版本,官方集群版本还是很不错的,至少笔者这么认为。
- 服务端分片的官方集群版本
官方版本区别于上面的Codis和Twemproxy,实现了服务器层的Sharding分片技术,换句话说官方没有中间层,而是多个服务结点本身实现了分片,当然也可以认为实现sharding的这部分功能被融合到了Redis服务本身中,并没有单独的Sharding模块。
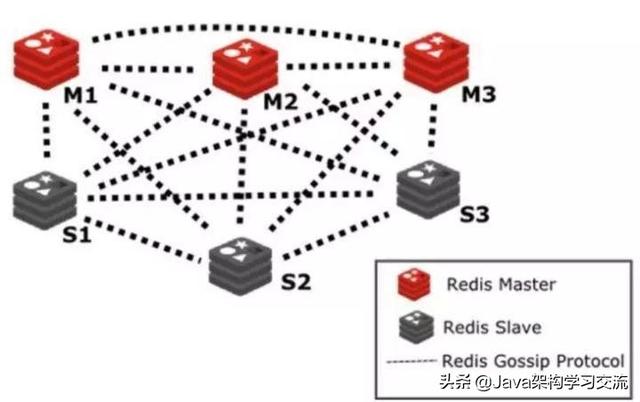
之前的文章也提到了官方集群引入slot的概念进行数据分片,之后将数据slot分配到多个Master结点,Master结点再配置N个从结点,从而组成了多实例sharding版本的官方集群架构。
Redis Cluster 是一个可以在多个 Redis 节点之间进行数据共享的分布式集群,在服务端,通过节点之间的特殊协议进行通讯,这个特殊协议就充当了中间层的管理部分的通信协议,这个协议称作Gossip流言协议。
分布式系统一致性协议的目的就是为了解决集群中多结点状态通知的问题,是管理集群的基础。
如图展示了基于Gossip协议的官方集群架构图:
注:图片来自网络
2.Redis Cluster的基本运行原理
- 结点状态信息结构
Cluster中的每个节点都维护一份在自己看来当前整个集群的状态,主要包括:
- 当前集群状态
- 集群中各节点所负责的slots信息,及其migrate状态
- 集群中各节点的master-slave状态
- 集群中各节点的存活状态及不可达投票
也就是说上面的信息,就是集群中Node相互八卦传播流言蜚语的内容主题,而且比较全面,既有自己的更有别人的,这么一来大家都相互传,最终信息就全面而且准确了,区别于拜占庭帝国问题,信息的可信度很高。
基于Gossip协议当集群状态变化时,如新节点加入、slot迁移、节点宕机、slave提升为新Master,我们希望这些变化尽快的被发现,传播到整个集群的所有节点并达成一致。节点之间相互的心跳(PING,PONG,MEET)及其携带的数据是集群状态传播最主要的途径。
- Gossip协议的概念
gossip 协议(gossip protocol)又称 epidemic 协议(epidemic protocol),是基于流行病传播方式的节点或者进程之间信息交换的协议。
在分布式系统中被广泛使用,比如我们可以使用 gossip 协议来确保网络中所有节点的数据一样。
gossip protocol 最初是由施乐公司帕洛阿尔托研究中心(Palo Alto Research Center)的研究员艾伦·德默斯(Alan Demers)于1987年创造的。https://www.iteblog.com/archives/2505.html
Gossip协议已经是P2P网络中比较成熟的协议了。Gossip协议的最大的好处是,即使集群节点的数量增加,每个节点的负载也不会增加很多,几乎是恒定的。这就允许Consul管理的集群规模能横向扩展到数千个节点。
Gossip算法又被称为反熵(Anti-Entropy),熵是物理学上的一个概念,代表杂乱无章,而反熵就是在杂乱无章中寻求一致,这充分说明了Gossip的特点:在一个有界网络中,每个节点都随机地与其他节点通信,经过一番杂乱无章的通信,最终所有节点的状态都会达成一致。每个节点可能知道所有其他节点,也可能仅知道几个邻居节点,只要这些节可以通过网络连通,最终他们的状态都是一致的,当然这也是疫情传播的特点。https://www.backendcloud.cn/2017/11/12/raft-gossip/
上面的描述都比较学术,其实Gossip协议对于我们吃瓜群众来说一点也不陌生,Gossip协议也成为流言协议,说白了就是八卦协议,这种传播规模和传播速度都是非常快的,你可以体会一下。所以计算机中的很多算法都是源自生活,而又高于生活的。
- Gossip协议的使用
Redis 集群是去中心化的,彼此之间状态同步靠 gossip 协议通信,集群的消息有以下几种类型:
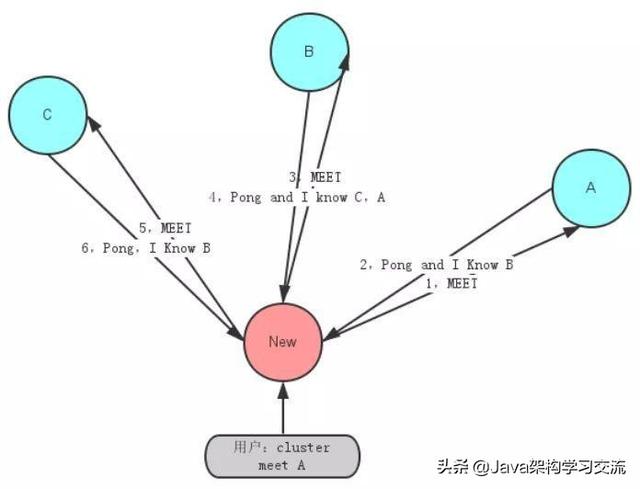
- Meet 通过「cluster meet ip port」命令,已有集群的节点会向新的节点发送邀请,加入现有集群。
- Ping 节点每秒会向集群中其他节点发送 ping 消息,消息中带有自己已知的两个节点的地址、槽、状态信息、最后一次通信时间等。
- Pong 节点收到 ping 消息后会回复 pong 消息,消息中同样带有自己已知的两个节点信息。
- Fail 节点 ping 不通某节点后,会向集群所有节点广播该节点挂掉的消息。其他节点收到消息后标记已下线。
由于去中心化和通信机制,Redis Cluster 选择了最终一致性和基本可用。
例如当加入新节点时(meet),只有邀请节点和被邀请节点知道这件事,其余节点要等待 ping 消息一层一层扩散。除了 Fail 是立即全网通知的,其他诸如新节点、节点重上线、从节点选举成为主节点、槽变化等,都需要等待被通知到,也就是Gossip协议是最终一致性的协议。
由于 gossip 协议对服务器时间的要求较高,否则时间戳不准确会影响节点判断消息的有效性。另外节点数量增多后的网络开销也会对服务器产生压力,同时结点数太多,意味着达到最终一致性的时间也相对变长,因此官方推荐最大节点数为1000左右。如图展示了新加入结点服务器时的通信交互图:
注:图片来自网络
总起来说Redis官方集群是一个去中心化的类P2P网络,P2P早些年非常流行,像电驴、BT什么的都是P2P网络。在Redis集群中Gossip协议充当了去中心化的通信协议的角色,依据制定的通信规则来实现整个集群的无中心管理节点的自治行为。
- 基于Gossip协议的故障检测
集群中的每个节点都会定期地向集群中的其他节点发送PING消息,以此交换各个节点状态信息,检测各个节点状态:在线状态、疑似下线状态PFAIL、已下线状态FAIL。
自己保存信息:当主节点A通过消息得知主节点B认为主节点D进入了疑似下线(PFAIL)状态时,主节点A会在自己的clusterState.nodes字典中找到主节点D所对应的clusterNode结构,并将主节点B的下线报告添加到clusterNode结构的fail_reports链表中,并后续关于结点D疑似下线的状态通过Gossip协议通知其他节点。
一起裁定:如果集群里面,半数以上的主节点都将主节点D报告为疑似下线,那么主节点D将被标记为已下线(FAIL)状态,将主节点D标记为已下线的节点会向集群广播主节点D的FAIL消息,所有收到FAIL消息的节点都会立即更新nodes里面主节点D状态标记为已下线。
最终裁定:将 node 标记为 FAIL 需要满足以下两个条件:
- 有半数以上的主节点将 node 标记为 PFAIL 状态。
- 当前节点也将 node 标记为 PFAIL 状态。
也就是说当前节点发现其他结点疑似挂掉了,那么就写在自己的小本本上,等着通知给其他好基友,让他们自己也看看,最后又一半以上的好基友都认为那个节点挂了,并且那个节点自己也认为自己挂了,那么就是真的挂了,过程还是比较严谨的。

















