本文经AI新媒体量子位(公众号ID:QbitAI)授权转载,转载请联系出处。
用AI对歌曲音轨的分离研究很多,不过大多数都是在频域上进行的。这类方法先把声音进行傅立叶变换,再从频谱空间中把人声、乐曲声分别抽离出来。
比如,上个月在GitHub上大热的Spleeter,就是这样。
但是由于要计算频谱,这类工具存在着延迟较长的缺点。虽然之前也有一些对声音波形进行处理的方法,但实际效果与频域处理方法相差甚远。
最近,Facebook AI研究院提供了两种波形域方法的PyTorch实现,分别是Demucs和Conv-Tasnet,而且测试结果均优于其他常见的频域方法,目前登上了GitHub日榜
效果对比
话不多说,我们先来听听这段30s音频的分离实测效果。
vocals.mp3
00:30.069
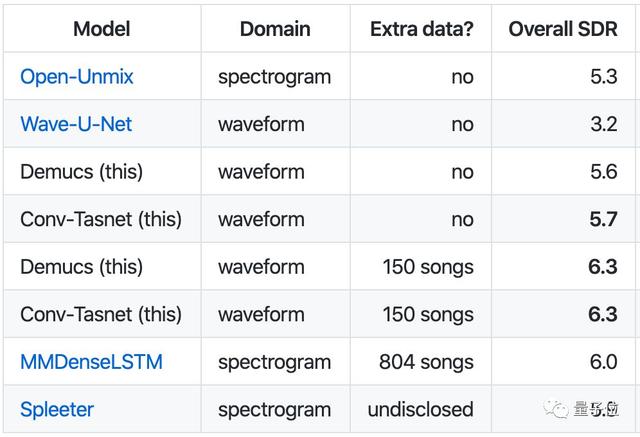
这两种方法在MusDB上的训练结果已经接近了频域方法的最优结果,加入150首额外的训练数据后,总体信号失真比(overall SDR)达到了6.3,超过了其他所有方法。
安装与使用方法
先将代码下载到本地,根据自己用CPU还是GPU来选择不同的安装环境:
- conda env update -f environment-cpu.yml # if you don’t have GPUs
- conda env update -f environment-cuda.yml # if you have GPUs
- conda activate demucs
在代码库的根目录下运行以下代码(Windows用户需将python3换为python.exe):
- python3 -m demucs.separate --dl -n demucs PATH_TO_AUDIO_FILE_1 [PATH_TO_AUDIO_FILE_2 ...] # for Demucs
- python3 -m demucs.separate --dl -n tasnet PATH_TO_AUDIO_FILE_1 ... # for Conv-Tasnet
- # Demucs with randomized equivariant stabilization (10x slower, suitable for GPU, 0.2 extra SDR)
- python3 -m demucs.separate --dl -n demucs --shifts=10 PATH_TO_AUDIO_FILE_1
其中—dl将自动下载预训练模型,-n后的参数代表选用的预训练模型类型:
demucs:表示在MusDB上进行训练的Demucs;
demucs_extra:使用额外数据训练的Demucs;
tasnet:表示在MusDB上进行训练的Conv-Tasnet;
tasnet_extra:使用额外数据训练的Conv-Tasnet。
在—shifts=SHIFTS执行多个预测与输入和平均他们的随机位移(又名随机等变稳定)。这使预测SHIFTS时间变慢,但将Demucs的精度提高了SDR的0.2点。它对Conv-Tasnet的影响有限,因为该模型本质上几乎是等时的。原始纸张使用10的值,尽管5产生的增益几乎相同。默认情况下禁用它。
原理简介
Demucs是Facebook人工智能研究院在今年9月提出的弱监督训练模型,基于受Wave-U-Net和SING启发的U-Net卷积架构。
研究人员引入了一个简单的卷积和递归模型,使其比Wave-U-Net的比信号失真比提高了1.6个点。
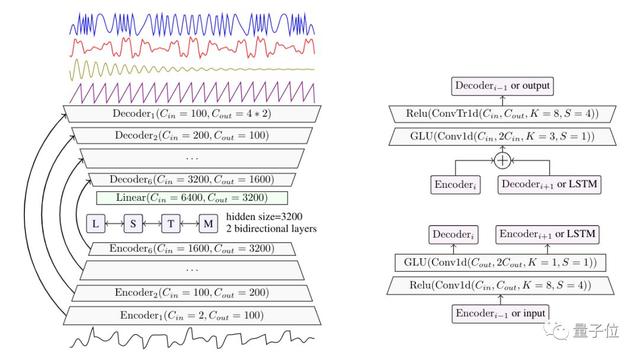
上图是Demucs的完整框架结构,右侧是编码器和解码器层的详细表示。
与之前的Wave-U-Net相比,Demucs的创新之处在于编码器和解码器中的GLU激活函数,以及其中的双向LSTM和倍增的通道数量。
Conv-TasNet是哥大的一名中国博士生Yi Luo提出的一种端到端时域语音分离的深度学习框架。
Conv-TasNet使用线性编码器来生成语音波形的表示形式,该波形针对分离单个音轨进行了优化。音轨的分离则是通过将一组加权函数(mask)用于编码器输出来实现。
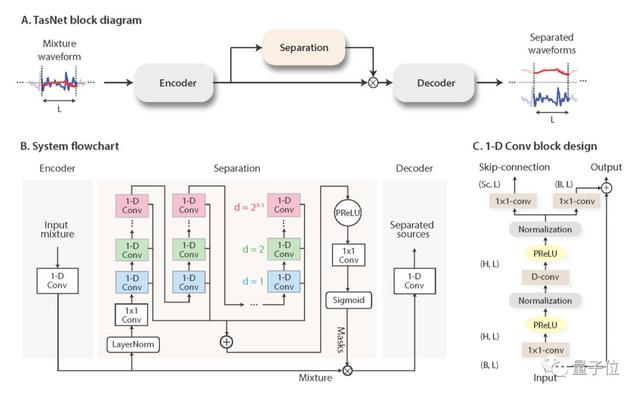
然后使用线性解码器将修改后的编码器表示形式反转回波形。由卷积的一维扩张卷积块组成的时间卷积网络(TCN)查找mask,使网络可以对语音信号的长期依赖性进行建模,同时保持较小的模型尺寸。
Conv-TasNet具有显着较小的模型尺寸和较短的延迟,是脱机和实时语音分离应用程序的合适解决方案。
传送门
项目地址:
https://github.com/facebookresearch/demucs
测试结果论文:
https://hal.archives-ouvertes.fr/hal-02379796/document