近期我们开发了一个银行卡 OCR 项目。需求是用手机对着银行卡拍摄以后,通过推理,可以识别出卡片上的卡号。
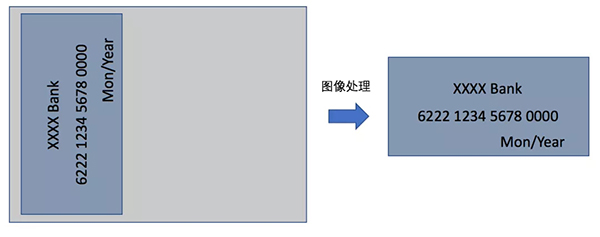
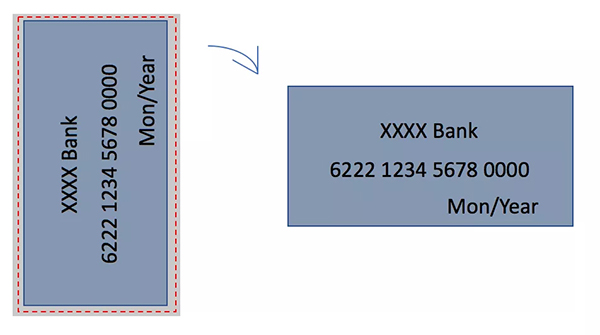
工程开发过程中,我们发现手机拍摄以后的图像,并不能满足模型的输入要求。以 Android 为例,从摄像头获取到的预览图像是带 90 度旋转的 NV21 格式的图片,而我们的模型要求的输入,只需要卡片区域这一块的图像,并且需要转成固定尺寸的 BGR 格式。所以在图像输入到模型之前,我们需要对采集到的图像做图像处理,如下图所示:
在开发的过程中,我们对 YUV 图像格式和 libyuv 进行了研究,也积累了一些经验。
下文我们结合银行卡 OCR 项目,讲一讲里面涉及到的一些基础知识:
- 什么是YUV格式
- 如何对YUV图像进行裁剪
- 如何对YUV图像进行旋转
- 图像处理中的Stride
- 如何进行缩放和格式转换
- libyuv的使用
想要对采集到的YUV格式的图像进行处理,首先我们需要了解什么是 YUV 格式。
什么是YUV格式
YUV 是一种颜色编码方法,YUV,分为三个分量:“Y” 表示明亮度(Luminance或Luma),也就是灰度值;“U”和“V” 表示的则是色度(Chrominance或Chroma)。主流的采样方式有三种YUV4:4:4YUV4:2:2YUV4:2:0这部分专业的知识,网络上有详细的解释。我们简单理解一下,RGB 和 YUV 都使用三个值来描述一个像素点,只是这三个值的意义不同。通过固定的公式,我们可以对 RGB 和 YUV 进行相互转换。
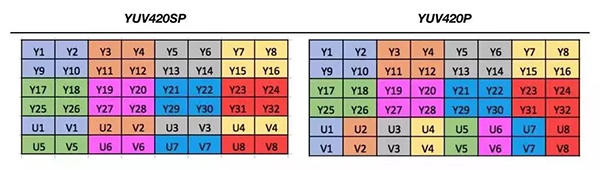
工程里常见的I420,NV21,NV12,都是属于YUV420,每四个Y共用一组UV分量。YUV420主要包含两种格式,YUV420SP 和YUV420P。★YUV420SP,先排列Y分量,UV分量交替排列,例如:NV12: YYYYYYYY UVUV 和★NV21: YYYYYYYY VUVU (上文中我们在安卓上采集到的图像就是这种格式)。
YUV420P,先排列U(或者V)分量,再排列V(或者U)分量。例如:I420: YYYYYYYY UU VV 和 YV12: YYYYYYYY VV UU。
了解了YUV的图像格式以后,我们就可以尝试对图片进行裁剪和旋转了。
我们的想法是先在图片上裁剪出银行卡的区域,再进行一次旋转。
如何对YUV图像进行裁剪
YUV420SP 和 YUV420P 裁剪的过程类似,以 YUV420SP 为例,我们要裁剪图中的这块区域:
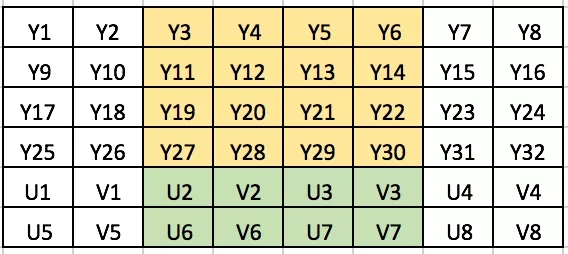
在图上看起来就非常明显了,只要找到裁剪区域对应的Y分量和UV分量,按行拷贝到目标空间里就可以了。

我们再来看一张图,是否可以用上面的方法来裁剪图中的这块区域呢?
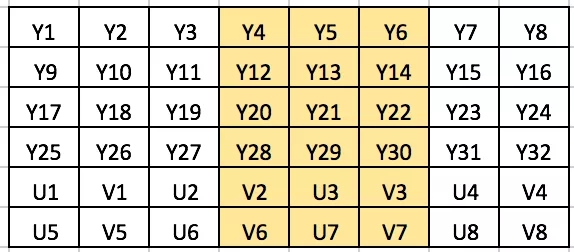
答案是否定的,如果你按照上面说的方法来操作,最后你会发现你保存出来的图,颜色基本是不对的,甚至会有内存错误。原因很简单,仔细观察一下,当 ClipLeft 或者 ClipTop 是奇数的时候,会导致拷贝的时候UV分量错乱。如果把错误的图像数据输入到模型里面,肯定是得不到我们期望的结果的。所以我们在做裁剪的时候,需要规避掉奇数的场景,否则你会遇到意想不到的结果。
如何对YUV图像进行旋转
对上文裁剪后的图像做顺时针90度旋转,相比裁剪,转换要稍微复杂一些。
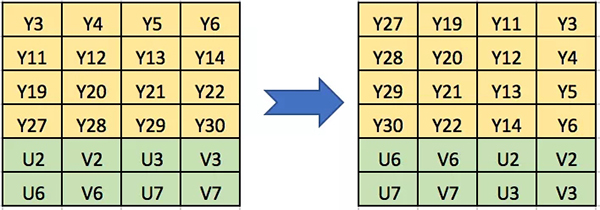
基本方法是一样的,拷贝对应的 Y 分量和 UV 分量到目标空间里。

在了解了裁剪和旋转的方法以后,我们发现在学习的过程中不可避免地遇到了 Stride 这个词。
那它在图像中的作用是什么呢?
图像处理中的Stride
Stride 是非常重要的一个概念,Stride 指在内存中每行像素所占的空间,它是一个大于等于图像宽度的内存对齐的长度。如下图所示:
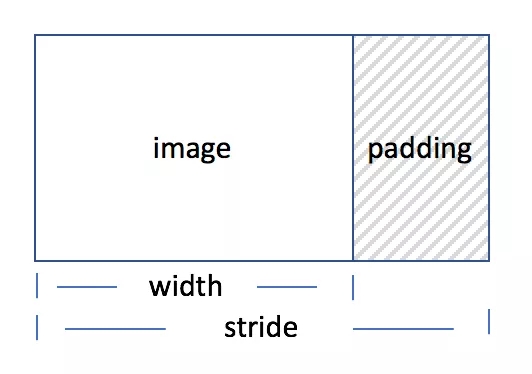
回过头来看我们上面说到的裁剪和旋转,是否有什么问题?
以 Android 上的YV12为例,Google Doc 里是这样描述的:
YV12 is a 4:2:0 YCrCb planar format comprised of a WxH Y plane followed by (W/2) x (H/2) Cr and Cb planes.
This format assumes
• an even width
• an even height
• a horizontal stride multiple of 16 pixels
• a vertical stride equal to the height
y_size = stride * height
c_stride = ALIGN(stride / 2, 16)
c_size = c_stride * height / 2
size = y_size + c_size * 2
cr_offset = y_size
cb_offize = y_size + c_size
- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
- 9.
- 10.
- 11.
- 12.
- 13.
- 14.
所以在不同的平台和设备上,需要按照文档和 stride 来进行计算。例如计算 Buffer 的大小,很多文章都是简单的 “*3/2” ,仔细考虑一下,这其实是有问题的。
如果不考虑 stride ,会有带来什么后果?如果 “运气” 足够好,一切看起来很正常。“运气”不够好,你会发现很多奇怪的问题,例如花屏,绿条纹,内存错误等等。这和我们平常工作中遇到的很多的奇怪问题一样,实际上背后都是有深层次的原因的。
经过裁剪和旋转,我们只需要把图像缩放成模型需要的尺寸,转成模型需要的BGR格式就可以了。
如何进行缩放和格式转换
以缩放为例,有临近插值,线性插值,立方插值,兰索斯插值等算法。YUV 和 RGB 之间的转换,转换的公式也有很多种,例如量化和非量化。这些涉及到专业的知识,需要大量的时间去学习和理解。
这么多的转换,我们是否都要自己去实现?
很多优秀的开源项目已经提供了完善的 API 给我们调用,例如 OpenCV,libyuv 等。我们需要做的是理解基本的原理,站在别人的肩膀上,做到心里有数,这样即使遇到问题,也能很快地定位解决。
经过调查和比较,我们选择了 libyuv 来做图像处理的库。libyuv 是 Google 开源的实现各种 YUV 与 RGB 之间相互转换、旋转、缩放的库。它是跨平台的,可在 Windows、Linux、Mac、Android 等操作系统,x86、x64、arm 架构上进行编译运行,支持 SSE、AVX、NEON等SIMD 指令加速。
libyuv的使用
引入libyuv以后,我们只需要调用libyuv提供的相关API就可以了。
在银行卡OCR工程使用的过程中,我们主要遇到了2个问题:
1.在Android开发的初期,我们发现识别率和我们的期望存在一定的差距。
我们怀疑是模型的输入数据有问题,通过排查发现是使用libyuv的时候,没注意到它是little endian。例如这个方法:int BGRAToARGB(...),BGRA little endian,在内存里顺序实际是ARGB。所以在使用的时候需要弄清楚你的数据在内存里是什么顺序的,修改这个问题后识别率达到了我们的预期。
2.在大部分机型上运行正常,但在部分机型上出现了 Native 层的内存异常。
通过多次定位,最后发现是 stride 和 buffersize 的计算错误引起的。通过银行卡 OCR 项目,我们积累了相关的经验。另外,由于 libyuv 是 C/C++ 实现的,使用的时候不是那么的便捷。为了提高开发效率,我们提取了一个 Vision 组件,对libyuv封装了一层 JNI 接口,包括了一些基础的转换和一些 sample,这样使用起来更加简单方便了。作为AOE SDK 里的图像处理组件,还在不断开发和完善中。