在最近的会议演讲中我经常会被问到:区块链数据分析很大的挑战是什么? 我的回答就一个词:去匿名化。我坚定地认为,识别不同类型的参与者并 理解其行为是解锁区块链分析潜力的核心挑战。我们花费了相当多的时间来 考虑这个问题以识别出与数字货币运动的伦理不发生冲突的正确边界。在 这篇文章里,我想进一步探讨这个思路。
市场上大多数区块链的架构依赖于匿名或伪匿名机制来保护其节点的隐私 并实现去中心化。数据混淆机制可以将加密资产交易数据记录在公开的 账本上让每个人都能访问,但是也让分析这些数据变得异常困难。如果不能 识别参与者的身份,就很难理解区块链数据集并分析出有意义的结果,而且 区块链分析只能徘徊在初级阶段。然而,重要的一点是要理解,去匿名化 区块链数据集并不是要知道账本中每个地址的真实身份,这个方向基本上是 不具备可扩展性的可能。相反的,我们可以识别并理解区块链中已知参与者 的行为,例如交易所、OTC柜台、矿工以及其他构成区块链生态系统的核心 成员。
并非所有的地址都一样
网络的量度是区块链分析中无所不在的一个指标,也是一个可以清晰地展示 去匿名化威力的指标。地址数量是最常见的一个具有误导性的指标,因为 并非所有的地址都同等重要。交易创建的一个用于临时性转账的地址,显然 不能和另一个长期持有资产的钱包地址相提并论。类似的,像币安这样的 交易所的热钱包,肯定也不同和我的个人钱包采用同样的方法和指标去分析。 同等对待所有地址的匿名性,注定会导致解读的有限性并且经常会得出误导性的结论。
匿名性 vs. 可解读性
匿名或伪匿名身份是可伸缩的去中心化架构的关键因素之一,但是这也让 从区块链数据集中获取有价值的信息变得极端困难。理解这一观点的一个 办法,就是把匿名性视为区块链分析的可解读性的一个反因子。
在区块链数据集中匿名性与可解读性之间的摩擦相对来说还比较小。一个 区块链数据集的匿名性越高,从中获取有意义的信息的难度就越大。参与 者的身份提供了其行为的上下文环境,而上下文环境则是可解读性的关键构建模块。
去匿名化 vs. 打标签
你是什么远比你是谁要重要。
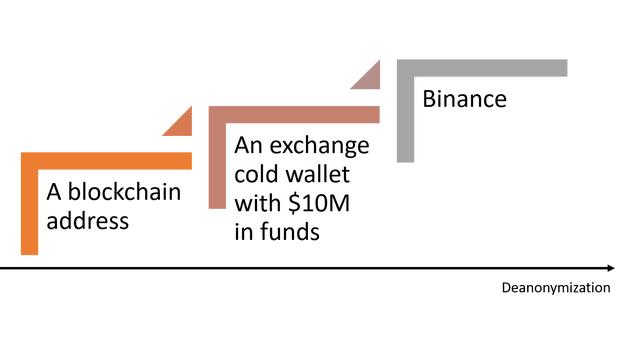
去匿名化区块链数据集并不涉及了解每个参与者的真实身份。试图了解每个 用户的真实身份不仅是一个意义重大的任务,而且也会让分析工作难以突破 一定的规模。相反,我们可以试着理解一个参与者的关键特征来让我们的分析 达到一定程度的可解读性。因此,不需要清楚地识别每个地址的真实身份,我们 可以给地址打标签或者附加一些描述性的元数据,来让其行为具备一定的 上下文环境。
在大规模数据中,打标签常常要比个体识别更有效果。理解区块链生态系统 中特定个体的行为当然会让分析达到更个性化的程度,但是对于在宏观层面 理解行为的趋势就显得相对受限了。
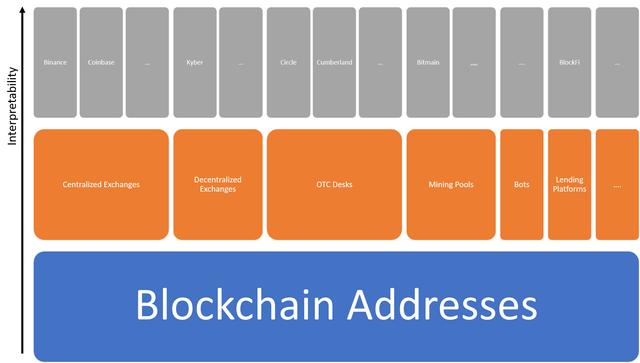
因此,相对与对区块链地址的个体真实身份的识别,去匿名性的挑战与地址 的关键性属性的标注的关系更大。我们如何实现这一点?
机器学习是解药
标注或者去匿名化区块链的思路可以让区块链分析更好地生态中已知参与者 的行为模式和特征。直觉上我们可以考虑创建一些规则来分析区块链生态系统 中的不同成员,例如:
如果一个地址持有大量比特币地址并且一次执行100个交易,那么这是一个交易所地址...
虽然很有吸引力,但是基于规则的方法将很快失效,无法再提供有用的信息。 下面列出了部分原因:
- 预置知识的完整性:基于规则的分类会假定我们对于如何识别区块链生态中的 不同参与者有足够的知识。这显然是不正确的假设。
- 持续的变化:区块链解决方案的架构一直都在演变,这对任何嵌入的规则而言都是挑战。
- 特征属性的数量:创建一条有两三个参数的规则很简单,但是试图创建一条有几十个 甚至上百个参数的规则就没那么简单了。要识别出像交易所或OTC柜台这样的 地址需要大量的特征。
因此我们不能使用预置的规则,我们需要一种可以从区块链数据集中学习模式的机制 来自动推断出有意义的规则让我们可以标注相关的参与方。从概念上来说,这是一个 经典的机器学习问题。
从机器学习的观点,我们应该从两个主要途径来考虑应对去匿名化的挑战:
- 无监督学习:无监督学习聚焦于学习指定数据集中存在的模式并识别相关分组。在 区块链数据集的上下文中,可以使用无监督学习模型基于地址的特征将其匹配到 不同的分组中并对这些分组进行标注。
- 监督学习:监督学习方法可以利用已有的知识来学习指定数据集中的新的特性。 在区块链上下文中,可以使用监督学习方法基于已有的交易所地址数据集训练一个 模型来识别出新的交易所地址。
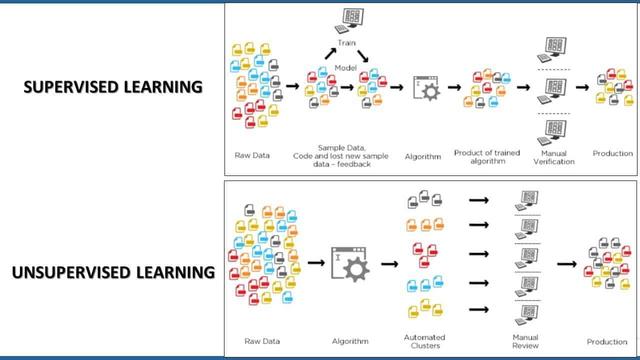
去匿名化或者给区块链数据集打标签很少是只用监督学习或者只用非监督学习, 更多的情况下需要两种方法的结合。机器学习模型可以有效地学习区块链生态 系统中特定参与者的特征,并利用这些特征来理解其行为。
在使用区块链ETL工具将区块链 原始数据加载到数据库或大数据分析平台后,将标注层引入区块链数据集是进行更有 价值的区块链数据分析的一个关键挑战。这些标签提供了更好的上下文环境,也让区 块链分析模型具有更好的可解读性。不过尽管我们有机器学习这样强大的工具,去匿 名性依然是分析理解区块链生态系统的道路上一个不可忽视的重大路障。