ZK介绍
- ZK = zookeeper
ZK是微服务解决方案中拥有服务注册发现最为核心的环境,是微服务的基石。作为服务注册发现模块,并不是只有ZK一种产品,目前得到行业认可的还有:Eureka、Consul。
这里我们只聊ZK,这个工具本身很小zip包就几兆,安装非常傻瓜,能够支持集群部署。
背景
在集群环境下ZK的leader&follower的概念,已经节点异常ZK面临的问题以及如何解决。ZK本身是java语言开发,也开源到Github上但官方文档对内部介绍的很少,零散的博客很多,有些写的很不错。
提问:
- zookeeper选举算法中的过半票数才提供正常服务,这是什么逻辑?
ZK集群单节点状态(每个节点有且只有一个状态),ZK的定位一定需要一个leader节点处于lading状态。
- looking:寻找leader状态,当前集群没有leader,进入leader选举流程。
- following:跟随者状态,接受leading节点同步和指挥。
- leading:领导者状态。
- observing:观察者状态,表名当前服务器是observer。
ZK投票处理策略
投票信息包含 :所选举leader的Serverid,Zxid,SelectionEpoch
- Epoch判断,自身logicEpoch与SelectionEpoch判断:大于、小于、等于。
- 优先检查ZXID。ZXID比较大的服务器优先作为Leader。
- 如果ZXID相同,那么就比较myid。myid较大的服务器作为Leader服务器。
过半选举算法
ZK中有三种选举算法,分别是LeaderElection,FastLeaderElection,AuthLeaderElection,FastLeaderElection和AuthLeaderElection是类似的选举算法,唯一区别是后者加入了认证信息, FastLeaderElection比LeaderElection更高效,后续的版本只保留FastLeaderElection。
理解:
在集群环境下多个节点启动,ZK首先需要在多个节点中选出一个节点作为leader并处于Leading状态,这样就面临一个选举问题,同时选举规则是什么样的。“过半选举算法”:投票选举中获得票数过半的节点胜出,即状态从looking变为leading,效率更高。
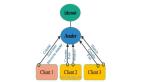
以5台服务器讲解思路:
服务器1启动,此时只有它一台服务器启动了,它发出去的Vote没有任何响应,所以它的选举状态一直是LOOKING状态;
服务器2启动,它与最开始启动的服务器1进行通信,互相交换自己的选举结果,由于两者都没有历史数据,所以id值较大的服务器2胜出,但是由于没有达到超过半数以上的服务器都同意选举它(这个例子中的半数以上是3),所以服务器1,2还是继续保持LOOKING状态.
服务器3启动,根据前面的理论,分析有三台服务器选举了它,服务器3成为服务器1,2,3中的老大,所以它成为了这次选举的leader.
服务器4启动,根据前面的分析,理论上服务器4应该是服务器1,2,3,4中最大的,但是由于前面已经有半数以上的服务器选举了服务器3,所以它只能接收当小弟的命了.
服务器5启动,同4一样,当小弟.
假设5台中挂了2台(3、4),其中leader也挂掉:
leader和follower间有检查心跳,需要同步数据 Leader节点挂了,整个Zookeeper集群将暂停对外服务,进入新一轮Leader选举
1)服务器1、2、5发现与leader失联,状态转为looking,开始新的投票 2)服务器1、2、5分别开始投票并广播投票信息,自身Epoch自增; 3) 服务器1、2、5分别处理投票,判断出leader分别广播 4)根据投票处理逻辑会选出一台(2票过半) 5)各自服务器重新变更为leader、follower状态 6)重新提供服务
脑裂问题
脑裂问题出现在集群中leader死掉,follower选出了新leader而原leader又复活了的情况下,因为ZK的过半机制是允许损失一定数量的机器而扔能正常提供给服务,当leader死亡判断不一致时就会出现多个leader。
方案:
ZK的过半机制一定程度上也减少了脑裂情况的出现,起码不会出现三个leader同时。ZK中的Epoch机制(时钟)每次选举都是递增+1,当通信时需要判断epoch是否一致,小于自己的则抛弃,大于自己则重置自己,等于则选举;
归纳
在日常的ZK运维时需要注意以上场景在极端情况下出现问题,特别是脑裂的出现,可以采用:
过半选举策略下部署原则:
- 服务器群部署要单数,如:3、5、7、...,单数是最容易选出leader的配置量。
- ZK允许节点最大损失数,原则就是“保证过半选举正常”,多了就是浪费。
详细的算法逻辑是很复杂要考虑很多情况,其中有个Epoch的概念(自增长),分为:LogicEpoch和ElectionEpoch,每次投票都有判断每个投票周期是否一致等等。