通过上一篇走进Golang之汇编原理,我们知道了目标代码的生成经历了那些过程。今天我们一起来学习一下生成的目标代码如何在计算机上执行。以及通过查阅 Golang 的 Plan9 汇编来了解Golang的一些内部秘密。
Golang的运行环境
当我们把编译后的Go代码运行起来,它会以进程的方式出现在系统中。然后开始处理请求、数据,我们会看到这个进程占用了内存消耗、cpu占比等等信息。本文就是要来解释在程序的运行过程中,内存、CPU、操作系统(当然还有其它的硬件,文中关系不大,就不说了)是如何进行配合,完成了我们代码所指定的事情。
内存
首先,我们先来说说内存。先来看一个我们运行的go进程。
代码如下:
- package main
- import (
- "fmt"
- "log"
- "net/http"
- )
- func main() {
- http.HandleFunc("/", sayHello)
- err := http.ListenAndServe(":9999", nil)
- if err != nil {
- log.Fatal("ListenAndServe: ", err)
- }
- }
- func sayHello(w http.ResponseWriter, r *http.Request) {
- fmt.Printf("fibonacci: %d\n", fibonacci(1000))
- _, _ = fmt.Fprint(w, "Hello World!")
- }
- func fibonacci(num int) int {
- if num < 2 {
- return 1
- }
- return fibonacci(num-1) + fibonacci(num-2)
- }
来看一下执行情况:
- dayu.com >ps aux
- USER PID %CPU %MEM VSZ RSS TT STAT STARTED TIME COMMAND
- xxxxx 3584 99.2 0.1 4380456 4376 s003 R+ 8:33下午 0:05.81 ./myhttp
这里我们先来不关注其它指标,先来看 VSZ 与 RSS。
- VSZ: 是指虚拟地址,他是程序实际操作的内存。包含了分配还没有使用的内存。
- RSS: 是实际的物理内存,包含了栈内存与堆内存。
每一个进程都是运行在自己的内存沙盒里,程序被分配的地址都是 “虚拟内存”,物理内存对程序开发者来说实际是不可见的,而且虚拟地址比进程实际的物理地址要大的多。我们经常编程中取指针对应的地址实际就是虚拟地址。这里一定要注意区分虚拟内存与物理内存。来一张图感受一下。
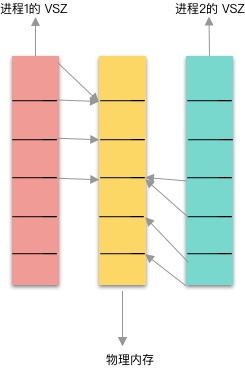
这张图主要是为了说明两个问题:
- 程序使用的是虚拟内存,但是操作系统会把虚拟内存映射到物理内存;你会发现自己机器上所有进程的VSZ要大得多;
- 物理内存可以被多个进程共享,甚至一个进程内的不同地址可能映射的都是同一个物理内存地址。
上面搞明白了程序中的内存具体是指什么,接下来说明程序是如何使用内存的(虚拟内存),内存说白了就是比硬盘存取速度更快的一个硬件,为了方便内存的管理,操作系统把分配给进程的内存划分成了不同的功能块。像我们经常说的:代码区,静态数据区,堆区,栈区等。
这里借用一张网络上的图来看一下。
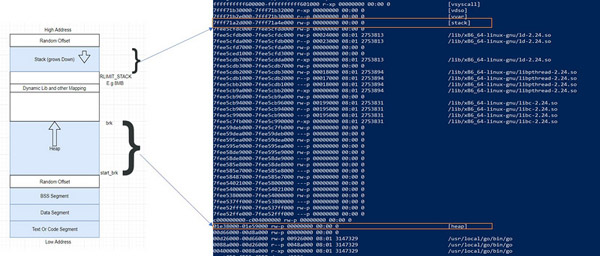
这里就是我们程序(进程)在虚拟内存中的分布。
代码区:存放的就是我们编译后的机器码,一般来说这个区域只能是只读。
静态数据区:存放的是全局变量与常量。这些变量的地址编译的时候就确定了(这也是使用虚拟地址的好处,如果是物理地址,这些地址编译的时候是不可能确定的)。Data与BSS都属于这一部分。这部分只有程序中止(kill掉、crasg掉等)才会被销毁。
栈区:主要是 Golang 里边的函数、方法以及其本地变量存储的地方。这部分伴随函数、方法开始执行而分配,运行完后就被释放,特别注意这里的释放并不会清空内存。后面文章讲内存分配的时候再详细说;还有一个点需要记住栈一般是从高地址向低地址方向分配,换句话说:高地址属于栈低,低地址属于栈底,它分配方向与堆是相反的。
堆区:像 C/C++ 语言,堆完全是程序员自己控制的。但是 Golang 里边由于有GC机制,我们写代码的时候并不需要关心内存是在栈还是堆上分配。Golang 会自己判断如果变量的生命周期在函数退出后还不能销毁或者栈上资源不够分配等等情况,就会被放到堆上。堆的性能会比栈要差一些。原因也留到内存分配相关的文章再给大家介绍。
内存的结构搞明白了,我们的程序被加载到内存还需要操作系统来指挥才能正确运行。
补充一个比较重要的概念:
寻址空间:一般指的是CPU对于内存寻址的能力,通俗地说,就是能最多用到多少内存的一个问题。比如:32条地址线(32位机器),那么总的地址空间就有 2^32 个,如果是64位机器,就是 2^64 个寻址空间。可以使用 uname -a 来查看自己系统支持的位数字。
操作系统、CPU、内存互相配合
为了讲清楚程序运行与调用,我们得先理清楚操作系统、内存、CPU、寄存器这几者之间的关系。
- CPU: 计算机的大脑,它才能理解并执行指令;
- 寄存器:严格讲寄存器是CPU的组成部分,它主要负责CPU在计算时临时存储数据;当然CPU还有多级的高速缓存,与我们这里相关度不大,就略过,大家知道其目的是为了弥补内存与CPU速度的差距即可;
- 内存:像上面内存被划分成不同区,每一部分存了不同的数据;当然这些区的划分、以及虚拟内存与物理内存的映射都是操作系统来做的;
- 操作系统:控制各种硬件资源,为其它运行的程序提供操作接口(系统调用)及管理。
这里操作系统是一个软件,CPU、寄存器、内存(物理内存)都是实打实的硬件。操作系统虽然也是一堆代码写出来的。但是她是硬件对其它应用程序的接口。总的来讲操作系统通过系统调用控制所有的硬件资源,他把其它的程序调度到CPU上让其它程序执行,但是为了让每个程序都有机会使用CPU,CPU又通过时间中断把控制权交给操作系统。
让操作系统可以控制我们的程序,我们编写的程序需要遵循操作系统的规定。这样操作系统才能控制程序执行、切换进程等操作。
最后我们的代码被编译成机器码之后,本质就是一条条的指令。我们期望的就是CPU去执行完这些指令进而完成任务。而操作系统又能够帮助我们让CPU来执行代码以及提供所需资源的调用接口(系统调用)。是不是非常简单?
Go程序的调用规约
在上面我们知道整个虚拟内存被我们划分为:代码区、静态数据区、栈区、堆区。接下来要讲的Go程序的调用规约(其实就是函数、方法运行的规则),主要是涉及上面所说的栈部分(堆部分会在内存分配的文章里边去讲)。以及计算机软硬各个部分如何配合。接下来我们就来看一下程序的基本单位函数跟方法是怎么执行与相互调用的。
函数在栈上的分布
这一部分,我们先来了解一些理论,然后接着用一个实际的例子来分析一下。先通过一张图来看一下在 Golang 中函数是如何在栈上分布的。
几个涉及到的专业用语:
- 栈:这里说的栈跟上面的解释含义一致。无论是进程、线程、goroutine都有自己的调用栈;
- 栈帧:可以理解是函数调用时在栈上为函数所分配的区域;
- 调用者:caller,比如:a函数调用了b函数,那么a就是调用者;
- 被调者:callee,还是上面的例子,b就是被调者。
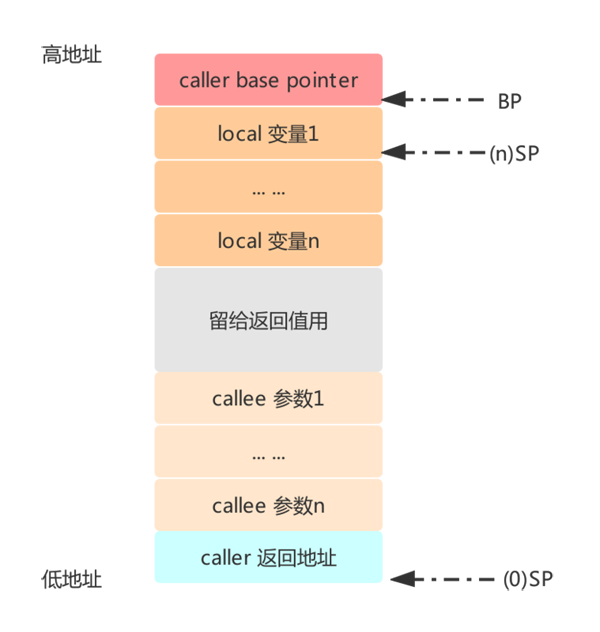
栈帧
这幅图所展示的就是一个 栈帧 的结构。也可以说栈桢是栈给一个函数分配的栈空间,它包括了函数调用者地址、本地变量、返回值地址、调用者参数等信息。
这里有几个注意点,图中的 BP、SP都表示对应的寄存器。
- BP:基址指针寄存器(extended base pointer),也叫帧指针,存放着一个指针,表示函数栈开始的地方。
- SP:栈指针寄存器(extended stack pointer),存放着一个指针,存储的是函数栈空间的栈顶,也就是函数栈空间分配结束的地方,注意这里是硬件寄存器,不是Plan9中的伪寄存器。
BP 与 SP 放在一起,一个表示开始(栈顶)、一个表示结束(栈低)。
有了上面的基础知识,接着下面用实际的例子来验证一下。
Go的调用实例
才开始,我们就从一个简单的函数开始来分析一下整个函数的调用过程(下面涉及到 Plan9 汇编,请别慌,大部分都能够看懂,并且我也会写注释)。
- package main
- func main() {
- a := 3
- b := 2
- returnTwo(a, b)
- }
- func returnTwo(a, b int) (c, d int) {
- tmp := 1 // 这一行的主要目的是保证栈桢不为0,方便分析
- c = a + b
- d = b - tmp
- return
- }
上面有两个函数,main 定义了两个本地变量,然后调用 returnTwo 函数。returnTwo 函数有两个参数与两个返回值。设计两个返回值主要是一起来看一下 golang 的多返回值是如何实现的。接下来我们把上面的代码对应的汇编代码展示出来。
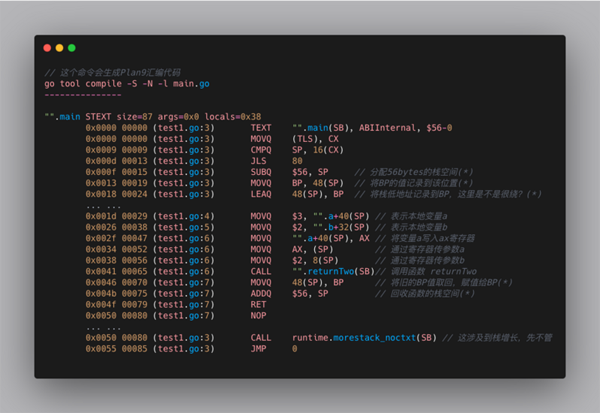
有几行代码需要特别解释下,
- 0x0000 00000 (test1.go:3) TEXT "".main(SB), ABIInternal, $56-0
这一行中的重点信息:$56-0。56 表示的该函数栈桢大小(两个本地变量,两个参数是int类型,两个返回值是int类型,1个保存base pointer,合计7 * 8 = 56);0表示 mian 函数的参数与返回值大小。待会可以在 returnTwo 中去看一下它的返回值又是多少。
接下来在看一下计算机是怎么在栈上分配大小的。
- 0x000f 00015 (test1.go:3) SUBQ $56, SP // 分配,56的大小在上面第一行定义了
- ... ...
- 0x004b 00075 (test1.go:7) ADDQ $56, SP // 释放掉,但是并未清空
这两行,一个是分配,一个是释放。为什么用了 SUBQ 指令就能进行分配呢?而 ADDQ 是释放?记得我们前面说过吗? SP 是一个指针寄存器,并且指向栈顶,栈又是从高地址向低地址分配。那么对它做一次减法,是不是表示从高地址向低地址方向移动指针了呢?释放也是同样的道理,一次加法操作又把 SP 恢复到初始状态。
再来看一下对 BP 寄存器的操作。
- 0x0013 00019 (test1.go:3) MOVQ BP, 48(SP) // 保存BP
- 0x0018 00024 (test1.go:3) LEAQ 48(SP), BP // BP存放了新的地址
- ... ...
- 0x0046 00070 (test1.go:7) MOVQ 48(SP), BP // 恢复BP的地址
这三行代码是不是感觉很变扭?写来写去让人云里雾里的。我先用文字描述一下,后面再用图来解释。
我们先做如下假设:此时 BP 指向的 值 是:0x00ff,48(SP) 的 地址 是:0x0008。
- 第一条指令 MOVQ BP, 48(SP) 是把 0x00ff 写入到 48(SP)的位置;
- 第二条指令 LEAQ 48(SP), BP 是更新寄存器指针,让 BP 保存 48(SP) 这个位置的地址,也就是 0x00ff 这个值。
- 第三条指令 MOVQ 48(SP), BP ,因为一开始 48(SP) 保存了最开始 BP 的所存的值 0x00ff,所以这里是又把 BP 恢复回去了。
这几行代码的作用至关重要,正因为如此在执行的时候,我们才能找到函数开始的地方以及回到调用函数的位置,它才可以继续往下执行(如果觉得饶,先放过,后面有图,看完后再回来理解)。接着来看一下 returnTwo 函数。
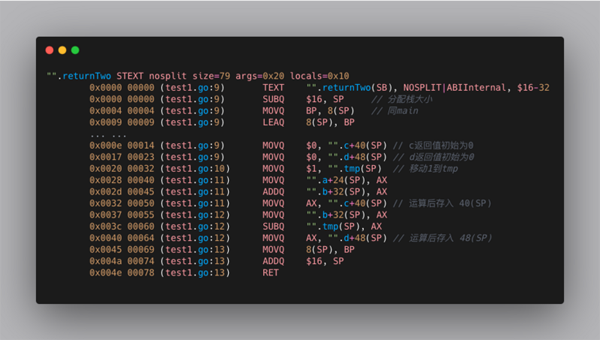
这里 NOSPLIT|ABIInternal, $0-32 说明,该函数的栈桢大小是0,由于有两个int参数,以及2个int返回值,合计为 4*8 = 32 字节大小,是不是跟上面的 main 函数对上了?。
这里有没有对 returnTwo 函数的栈桢大小是0表示迷惑呢?难道这个函数不需要栈空间吗?其实主要原因是:golang的参数传递与返回值都是要求使用栈来进行的(这也是为什么go能够支持多参数返回的原因)。所以参数与返回值所需空间都由 caller 来提供。
接下来,我们用完整的图来演示一下这个调用过程。
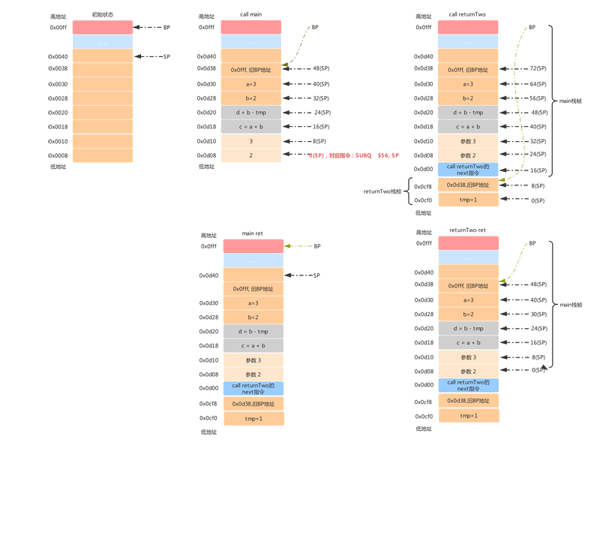
这个图就画了将近1个小时,希望对大家理解有帮助。
整个的流程是:初始化 ----> call main function ----> call returnTwo function ----> returnTwo return ----> main return。
通过这张图,在结合我上面的文字解释,相信大家能够理解了。不过这里还有几个注意点:
- BP 与 SP 是寄存器,它保存的是栈上的地址,所以执行中可以对 SP 做运算找到下一个指令的位置;
- 栈被回收 ADDQ $56, SP ,只是改变了 SP 指向的位置,内存中的数据并不会清空,只有下次被分配使用的时候才会清空;
- callee的参数、返回值内存都是caller分配的;
- returnTwo ret的时候,call returnTwo的next指令 所在栈位置会被弹出,也就是图中 0x0d00 地址所保存的指令,所以 returnTwo 函数返回后,SP 又指向了 0x0d08 地址。
由于上面涉及到一些 Plan9 的知识,就顺带一起介绍一些它的语法,如果直接讲语法会很枯燥,下面会结合一些实际中会用到的情况来介绍。既有收获又能学会语法。
Go的汇编plan9
我们整个程序的编译最终会被翻译成机器码,而汇编可以算是机器码的文本形式,他们之间可以一一对应。所以如果我们能够看懂汇编一点点就能够分析出很多实际问题。
开发go语言的都是当前世界最TOP的那群程序员,他们选择了持续装逼,不用标准的 AT&T 也不用 Intel 汇编器,偏要自己搞一套,没办法,谁让人家牛呢!Golang的汇编是基于 Plan9 汇编的,个人觉得要完全学懂太复杂了,因为这涉及到很多底层知识。不过如果只是要求看懂还是能够做到的。下面我们就举一些例子来试试看。
PS: 这东西完全学懂也没有必要,投入产出比太低了,对于一个应用工程师能够看懂就行。
在正式开始前,我们还是补充一些必要信息,上文已经涉及过一些,为了完整这里在整体介绍一下。
几个重要的伪寄存器
- SB:是一个虚拟寄存器,保存了静态基地址(static-base) 指针,即我们程序地址空间的开始地址;
- NOSPLIT:向编译器表明不应该插入 stack-split 的用来检查栈需要扩张的前导指令;
- FP:使用形如 symbol+offset(FP) 的方式,引用函数的输入参数;
- SP:plan9 的这个 SP 寄存器指向当前栈帧的局部变量的开始位置,使用形如 symbol+offset(SP) 的方式,引用函数的局部变量,注意:这个寄存器与上文的寄存器是不一样的,这里是伪寄存器,而我们展示出来的都是硬件寄存器。
其它还有一些操作指令,根据名字多半都能够看出来,就不再介绍,直接开始干。
查看go应用代码对应的翻译函数
- package main
- func main() {
- }
- func test() []string {
- a := make([]string, 10)
- return a
- }
- --------
- "".test STEXT size=151 args=0x18 locals=0x40
- 0x0000 00000 (test1.go:6) TEXT "".test(SB), ABIInternal, $64-24 // 栈帧大小,与参数、返回值大小
- 0x0000 00000 (test1.go:6) MOVQ (TLS), CX
- 0x0009 00009 (test1.go:6) CMPQ SP, 16(CX)
- 0x000d 00013 (test1.go:6) JLS 141
- 0x000f 00015 (test1.go:6) SUBQ $64, SP
- 0x0013 00019 (test1.go:6) MOVQ BP, 56(SP)
- 0x0018 00024 (test1.go:6) LEAQ 56(SP), BP
- ... ...
- 0x001d 00029 (test1.go:6) MOVQ $0, "".~r0+72(SP)
- 0x0026 00038 (test1.go:6) XORPS X0, X0
- 0x0029 00041 (test1.go:6) MOVUPS X0, "".~r0+80(SP)
- 0x002e 00046 (test1.go:7) PCDATA $2, $1
- 0x002e 00046 (test1.go:7) LEAQ type.string(SB), AX
- 0x0035 00053 (test1.go:7) PCDATA $2, $0
- 0x0035 00053 (test1.go:7) MOVQ AX, (SP)
- 0x0039 00057 (test1.go:7) MOVQ $10, 8(SP)
- 0x0042 00066 (test1.go:7) MOVQ $10, 16(SP)
- 0x004b 00075 (test1.go:7) CALL runtime.makeslice(SB) // 对应的底层runtime function
- ... ...
- 0x008c 00140 (test1.go:8) RET
- 0x008d 00141 (test1.go:8) NOP
- 0x008d 00141 (test1.go:6) PCDATA $0, $-1
- 0x008d 00141 (test1.go:6) PCDATA $2, $-1
- 0x008d 00141 (test1.go:6) CALL runtime.morestack_noctxt(SB)
- 0x0092 00146 (test1.go:6) JMP 0
根据对应的代码行数与名字,很明显的可以看到应用层写的 make 对应底层是 makeslice。
逃逸分析
这里先说一下逃逸分析的概念。这里牵扯到栈、堆分配的问题。如果变量被分配到栈上,会伴随函数调用结束自动回收,并且分配效率很高;其次分配到堆上,则需要GC进行标记回收。所谓逃逸就是指变量从栈上逃到了堆上(很多人对这个概念都不清楚就在谈逃逸分析,面试遇到了好几次😓)。
- package main
- func main() {
- }
- func test() *int {
- t := 3
- return &t
- }
- ------
- "".test STEXT size=98 args=0x8 locals=0x20
- 0x0000 00000 (test1.go:6) TEXT "".test(SB), ABIInternal, $32-8
- 0x0000 00000 (test1.go:6) MOVQ (TLS), CX
- 0x0009 00009 (test1.go:6) CMPQ SP, 16(CX)
- 0x000d 00013 (test1.go:6) JLS 91
- 0x000f 00015 (test1.go:6) SUBQ $32, SP
- 0x0013 00019 (test1.go:6) MOVQ BP, 24(SP)
- 0x0018 00024 (test1.go:6) LEAQ 24(SP), BP
- ... ...
- 0x001d 00029 (test1.go:6) MOVQ $0, "".~r0+40(SP)
- 0x0026 00038 (test1.go:7) PCDATA $2, $1
- 0x0026 00038 (test1.go:7) LEAQ type.int(SB), AX
- 0x002d 00045 (test1.go:7) PCDATA $2, $0
- 0x002d 00045 (test1.go:7) MOVQ AX, (SP)
- 0x0031 00049 (test1.go:7) CALL runtime.newobject(SB) // 堆上分配空间,表示逃逸了
- ... ...
这里如果是对 slice 使用汇编进行逃逸分析,并不会很直观。因为只会看到调用了 runtime.makeslice 函数,该函数内部其实又调用了 runtime.mallocgc 函数,这个函数会分配的内存其实就是堆上的内存(如果栈上足够保存,是不会看到对 runtime.makslice 函数的调用)。
实际go也提供了更方便的命令来进行逃逸分析:go build -gcflags="-m" ,如果真的是做逃逸分析,建议使用该命令,别折腾用汇编。
传值还是传指针
对于golang中的基本类型:字符串、整型、布尔类型就不多说了,肯定是值传递,那么对于结构体、指针到底是值传递还是指针传递呢?
- package main
- type Student struct {
- name string
- age int
- }
- func main() {
- jack := &Student{"jack", 30}
- test(jack)
- }
- func test(s *Student) *Student {
- return s
- }
- -------
- "".test STEXT nosplit size=20 args=0x10 locals=0x0
- 0x0000 00000 (test1.go:14) TEXT "".test(SB), NOSPLIT|ABIInternal, $0-16
- ... ...
- 0x0000 00000 (test1.go:14) MOVQ $0, "".~r1+16(SP) // 初始返回值为0
- 0x0009 00009 (test1.go:15) PCDATA $2, $1
- 0x0009 00009 (test1.go:15) PCDATA $0, $1
- 0x0009 00009 (test1.go:15) MOVQ "".s+8(SP), AX // 将引用地址复制到 AX 寄存器
- 0x000e 00014 (test1.go:15) PCDATA $2, $0
- 0x000e 00014 (test1.go:15) PCDATA $0, $2
- 0x000e 00014 (test1.go:15) MOVQ AX, "".~r1+16(SP) // 将 AX 的引用地址又复制到返回地址
- 0x0013 00019 (test1.go:15) RET
通过这里可以看到在go里边,只有值传递,因为它底层还是通过拷贝对应的值。
总结
今天的文章到此结束,本次主要讲了下面几个点:
- 计算机软硬资源之间的相互配合;
- Golang 编写的代码,函数与方法是怎么执行的,主要讲了栈上分配与相关调用;
- 使用 Plan9 分析了一些常见的问题。
希望本文对大家在理解、学习Go的路上有一些帮助。