












今年 8 月份,毕业于斯坦福、现就职于英伟达人工智能应用团队的一位小姐姐在推特上列出了十大优质的免费机器学习课程资源,并将它们串成了一条高效的学习路线。该课程资源现已获得 8000 多赞。近日,她又为读者带来了新的福利,这次是深度学习系统的设计教程。
将机器学习模型变为可以提供服务和 AI 能力的系统是近来备受关注的话题。Chip Huyen 此次公开的深度学习系统设计教程是一篇 8000 字的长文,得到了广泛的关注。目前其推特已有 5000 赞,而 GitHub 项目也在一天内获得了 1000 多星。
教程地址:https://github.com/chiphuyen/machine-learning-systems-design/blob/master/build/build1/consolidated.pdf
项目地址:https://github.com/chiphuyen/machine-learning-systems-design
从理论到实践,八千字教程解读 ML 系统设计
该教程共包含四个部分:引言、机器学习系统的设计、案例教学和习题。其中,案例教学和习题部分分别包含 10 个生产环境经典案例和 27 个面试中可能遇到的问题。
全书主要以方法论为主,重点在于提供相应的指导原则,帮助读者思考构建系统的必要步骤。

引言
在第一部分,作者介绍了机器学习研究和生产的主要区别。这些区别体现在两个方面:性能需求和计算需求。
在性能需求方面,对于机器学习研究者而言,SOTA 就是一切。他们会不惜使用各种复杂的技术及其组合来追求百分之一的性能提升,但这种提升在生产环境中可能并不适用,而且会因为过于复杂而消耗更多计算资源。
在计算需求方面,由于目前流行的大模型需要昂贵的计算资源,因此如果想把这些模型应用到生产环境中,还需要社区去探索模型压缩、预训练等技术,使得模型更小、更快。生产领域的开发者应该时刻牢记以生产为目标进行机器学习系统的设计。
机器学习系统设计四部曲
第二部分是这本书的核心内容,即如何设计一个机器学习系统。作者将这一设计过程分为四步:项目设置、数据 pipeline、建模(选择、训练和调试模型)和服务(测试、部署和维护模型)。
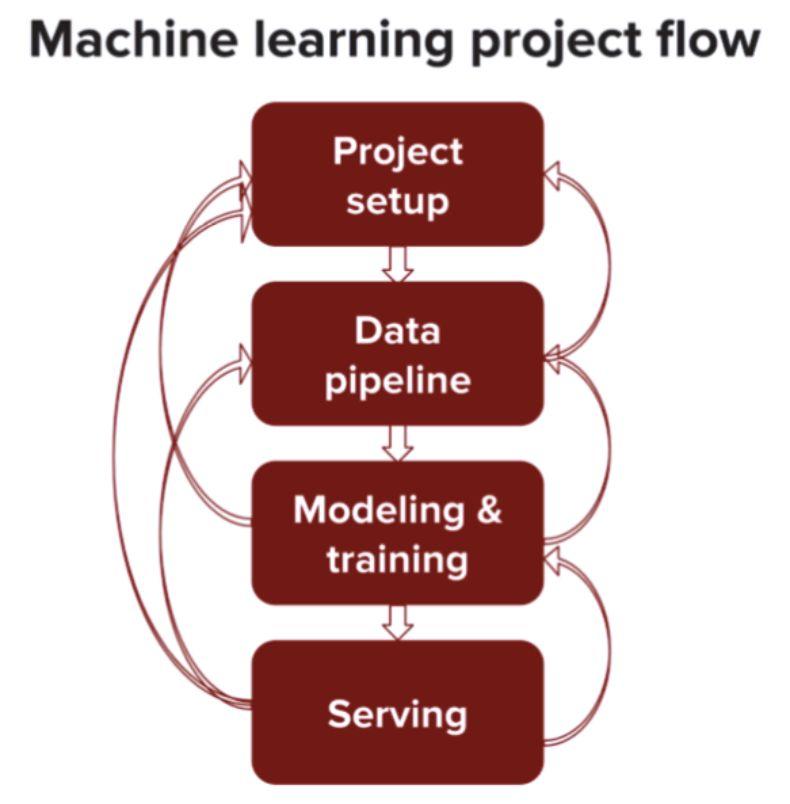
作者提出的深度学习系统构建流程。
项目设置即对项目进行评估、设计的环节。这一环节的目标在于定义深度学习所需要解决的实际问题(产品的意义)、性能限制、项目限制、评估方法和个性化等。只有定义清楚项目的目标和实现方法,才能够确保构建的系统能够满足要求,解决实际问题。
数据是深度学习最不可或缺的部分,尽管研究领域的大部分模型都有着充足、平衡且干净的数据集,但是生产条件下则不一定。因此,系统设计中也需要考虑到数据的问题,包括如何获得可靠、充足、大量的数据,同时需要面对隐私保护、数据安全、数据存储和数据平衡方面的问题,并提供可行的解决方案。
在建模过程中,需要经过模型选型、训练、调试和评估几个环节。其中,在模型选择时需要考虑找到最合适的基准,如随机基准、人类基准或启发式基准。采用的模型则应当从简单到复杂,训练的过程也应当是从少量的数据开始,如果行得通就扩大模型规模,增加投入的数据批的大小,并进行调参工作。如果模型的推理性能不佳,则需要考虑是否是数据问题、错误的假设和模型/数据拟合,超参选择错误等。
在服务阶段,设计者需要考虑模型怎样根据接收到的输入提供合适的结果,用户怎样收到这些结果,怎样能够让他们的反馈更好地改进现有的模型。同时,模型也不是一成不变的,它需要不断地训练。从现有数据进行训练使其变得更精准与给模型增加一个新标签进行训练是不同的。前者只需要在现有模型上进行训练,而后者则需要从头开始训练。
10 个经典案例
为了避免理论上的「纸上谈兵」,在全书的第三部分,作者提供了 10 个案例教学,用于帮助读者理解理论,学习实践。
阅读这些案例可以学到如何在生产环境中克服种种部署要求和约束。Airbnb、Lyft、Uber、Netflix 等很多公司都开设了博客来介绍自己使用机器学习改进产品或生产流程的经验。需要面试的小伙伴可以经常浏览这些博客。本教程介绍了其中的一些精华案例,包括:
1. 利用机器学习预测 Airbnb 上的房屋价值。
链接:https://medium.com/airbnb-engineering/using-machine-learning-to-predict-value-of-homes-on-airbnb-9272d3d4739d
2. 利用机器学习提高 Netflix 上的数据流质量。
链接:https://medium.com/netflix-techblog/using-machine-learning-to-improve-streaming-quality-at-netflix-9651263ef09f
3. 缤客网 150 个成功的机器学习模型:从中学到的 6 个经验教训 。
链接:https://blog.acolyer.org/2019/10/07/150-successful-machine-learning-models/
4. 从零到 400 万女性用户的时尚 APP——Chicisimo。
链接:https://medium.com/hackernoon/how-we-grew-from-0-to-4-million-women-on-our-fashion-app-with-a-vertical-machine-learning-approach-f8b7fc0a89d7
5. 用机器学习驱动 Airbnb 搜索体验。
链接:https://medium.com/airbnb-engineering/machine-learning-powered-search-ranking-of-airbnb-experiences-110b4b1a0789
6. Lyft 公司的反欺诈机器学习系统。
链接:https://eng.lyft.com/from-shallow-to-deep-learning-in-fraud-9dafcbcef743
7. Instacart 外送服务中的路径优化。
链接:https://tech.instacart.com/space-time-and-groceries-a315925acf3a
8. Uber 的大数据平台:具有分钟级延迟的 100+Petabytes。
链接:https://eng.uber.com/uber-big-data-platform/
9. 利用计算机视觉和深度学习来创建现代化的 OCR 管道。
链接:https://blogs.dropbox.com/tech/2017/04/creating-a-modern-ocr-pipeline-using-computer-vision-and-deep-learning/
10. 利用 Uber 推出的 Michelangelo 机器学习平台来扩展机器学习。
链接:https://eng.uber.com/scaling-michelangelo/
27 个练习题
最后,还有 27 个练习题可供上手尝试。习题的答案将在《Machine Learning Interviews》一书中给出。
想贡献答案的同学可以戳:https://github.com/chiphuyen/machine-learning-systems-design/tree/master/answers



此外,作者提醒大家注意,这里的问题有些是模棱两可的。如果在面试中遇到这些问题,你需要引导面试官把问题描述清楚、缩小范围。





















