












一、运维在广告体系中的价值
运维的工作来源已久,但直到近些年,随着互联网的发展,产品的维护工作越来越复杂,以及服务可用性的提升,都让运维的工作越来越重要。我们可以回顾下运维发展至今都经历了哪些阶段。
① 人工阶段
这个阶段的运维主要通过人肉操作我们的服务,由于这个阶段的服务大都是单实例,流量服务器都比较少,所以我们通过命令行就能够解决绝大多数的问题。
② 工具阶段
随着互联网影响逐渐变大,我们的流量也开始变大,我们的产品功能也开始变得丰富,曾经我们单实例的服务也开始朝着多实例、分布式发展,为了应对逐渐增加的服务器、服务数,我们开始使用一些如Puppet的运维工具,通过Shell、Python写一些脚本来提升运维的工作效率,减少重复的劳动。
③ DevOps
前几年,运维领域开始提出DevOps的理念,开始着手解决运维与开发的合作问题,开始让运维的工作走向规范化、平台化。让一个产品从功能开发到测试交付、再到后期运维能够更加的快捷、频繁、可靠,更快的响应互联网快速的发展和产品迭代。
④ AiOps
这两年,人工智能和大数据的异常火热,而运维领域的许多工作都为AI和大数据的实施落地提供了良好的土壤。我们也希望通过Ai和大数据等技术的引入,能够将运维的技术层次带入一个更高的台阶。
通过以上描述,我们可以看到运维的工作在互联网的产品技术链中是不可或缺的一环,那么下面我们再来看下在微博广告团队,我们都是通过哪些方案举措来服务微博广告的产品。
对于我们微博广告团队来说,服务的可用性是至关重要的,也是我们的核心KPI,所以保障广告服务的稳定性也是我们运维工作的重中之重。我们主要会通过优化系统和提升效率两个方面来保障和提升我们服务的可用性。
具体涉及的内容包括系统性能评估、故障迅速定位、应急事件处理、请求链路跟踪、代码快速迭代、指标走势预测等等。
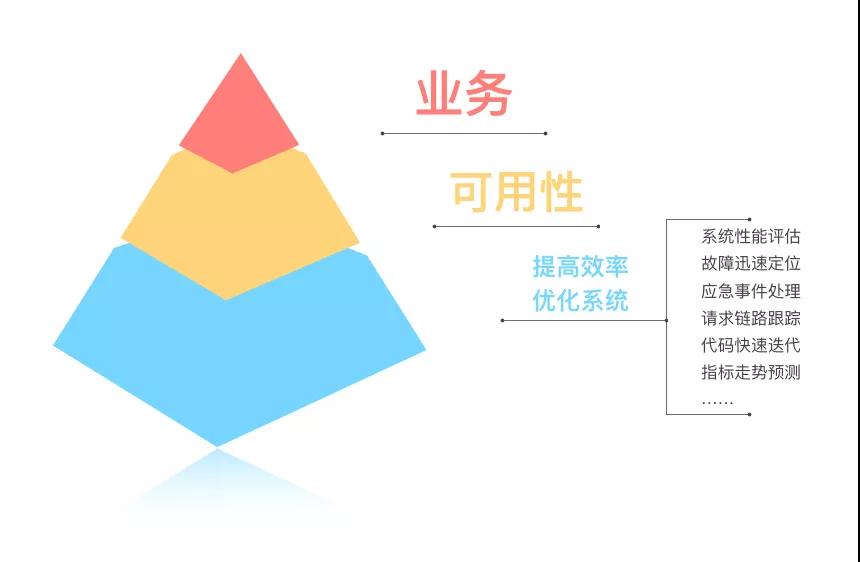
▲ 图1-1 运维在微博广告的价值
二、复杂业务场景下的运维建设之路
1、服务治理
图2-1是去年IG夺冠时,王思聪发了一条博文,而这条博文对微博广告的影响就如图2-2所示。这种突发的流量波动是微博典型的特征之一,它不同于双十一等活动,可以提前预估流量,做好前期准备工作。在传统的运维场景下,也许在你也还没准备好的情况下,流量的高峰就已经过去了。所以如果应对这样突发的流量高峰是我们需要重点解决的问题之一。
▲ 图2-1
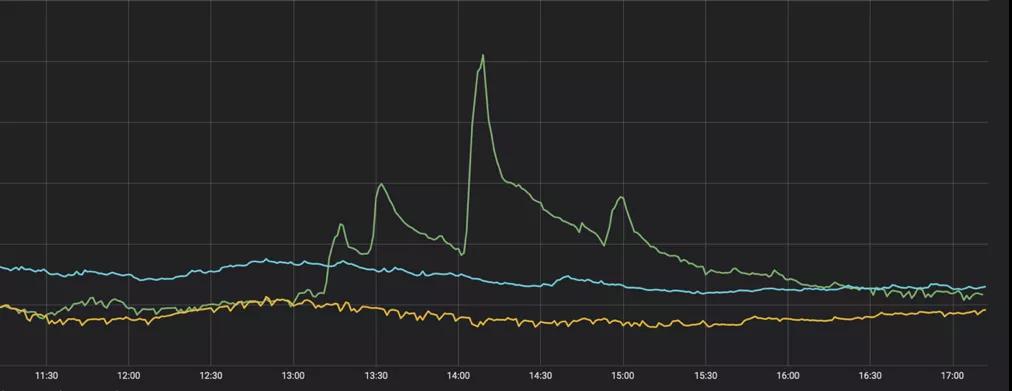
▲ 图2-2
从去年开始,我们运维团队开始进行基于机房的服务治理工作。在以前,广告的很多服务部署都是单点单机房、很多多机房的部署也面临部署不均衡,流量不均匀等现象。跨机房的请求更是无形的增加了整个广告链路的请求耗时。所以再出现机房级故障时,我们的服务就可能像图2-4所示的那样,那么服务的高可用性也就无从谈起了。
▲ 图2-3
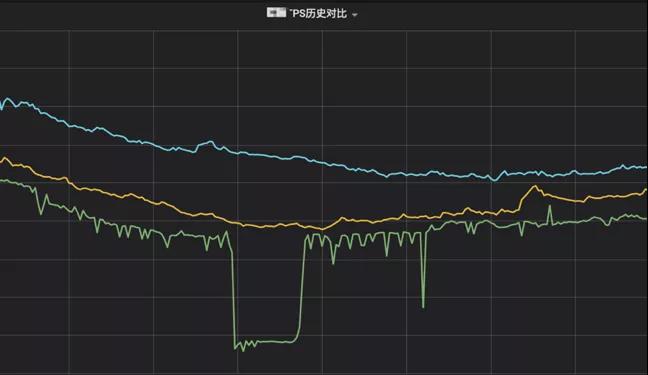
▲ 图2-4
在19年的上半年,经过大半年的时间,我们完成了微博广告基于机房级别的服务优化改造。共治理服务一百多个,所有的服务都分布在两个及以上的运营商和机房中,从而避免了单机房出现故障时,造成广告服务的不可用。而我们治理过程中坚持的准备主要有以下几点:
- 服务多机房均衡部署
- 分布在不同运营商
- 机房承载能力冗余
- 流量请求均匀分布
- 上下游同机房请求
同时,我们还会定期做流量压测,来发现我们系统链路中的服务瓶颈。我们将生产环境的流量重新拷贝到生产环境中去,来增加线上流量,发现服务性能瓶颈。
图2-5是我们对某广告产品的整体性能压测所展示的效果,我们可以清楚的发现图中有两个模块的在流量高峰下,出现了耗时波动较大的问题。由此我们可以针对性的进行优化。
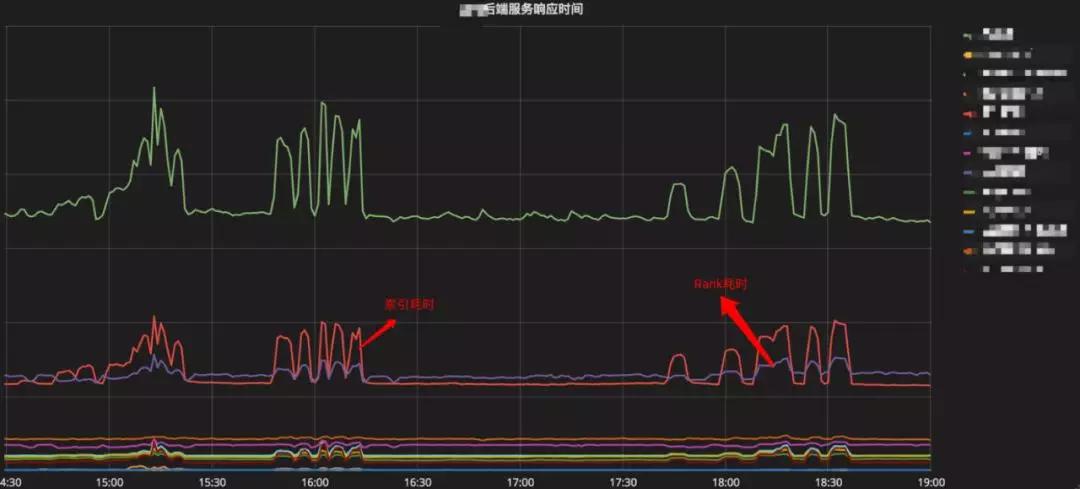
▲ 图2-5
2、自动化运维平台
随着互联网的发展,我们的广告产品也是日新月异,迭代频繁。我们运维团队每天需要面对来自三百多个业务方提过来的上线需求,在三千多台机器上进行服务的变更等操作,如何提升服务上线的效率和质量,如何让变更变得安全可靠也是我们重要的目标之一。

▲ 图2-6
从17年开始,我们运维团队自研了一套自动化运维平台Kunkka,该平台主要基于SaltStack、Jenkins等技术,可以实现服务的快速上线、快速回滚等操作。整体架构如图2-7所示。
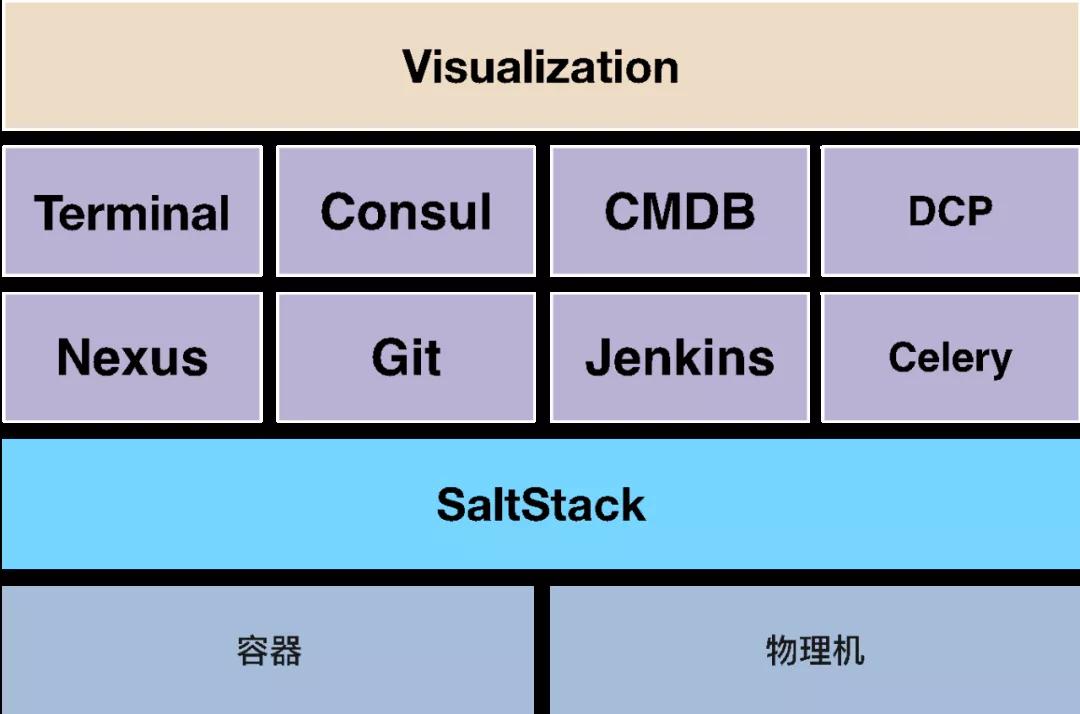
▲ 图2-7 Kunkka整体架构图
开发同学在提交代码到Gitlab后,自动触发Jenkins的编译操作,并将编译后的包上传至Nexus中,这时开发同学只需要选择他们想要部署的目标主机就可以了。
同时,为了应对平常突发的流量高峰和节假日的流量高峰,我们还对接了公司的DCP平台,可以在我们的Kunkka平台上自动生成Docker镜像文件,并上传公司的镜像仓库中,这样就可以在快速的将服务部署到云主机上,实现服务动态扩缩容。
整个服务部署过程中,我们还加入了多级审核机制,保障服务上线的安全性。具体流程如图2-8所示。
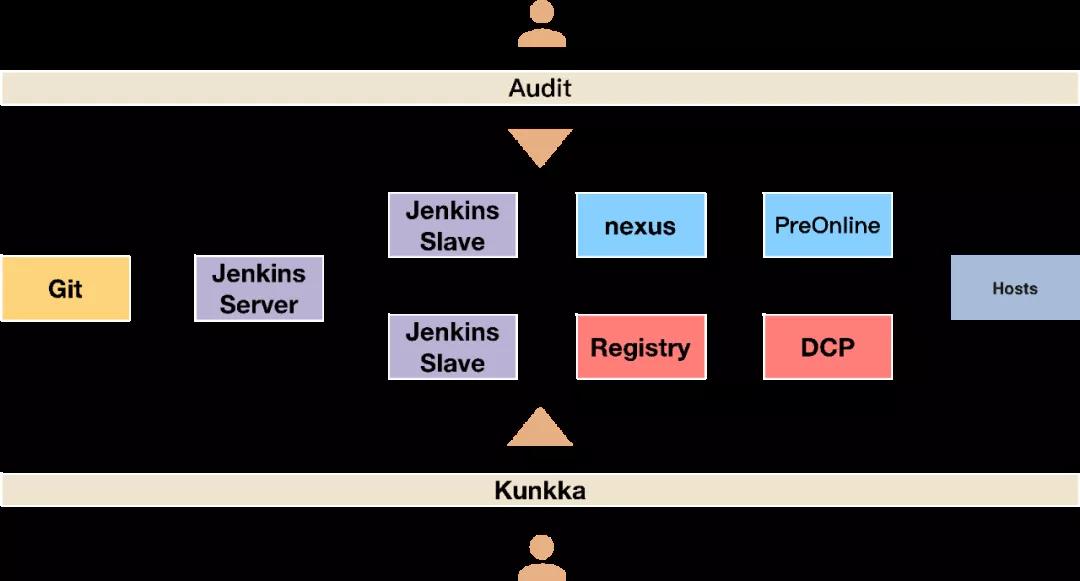
▲ 图2-8 Kunkka上线流程图
3、有效的报警
在服务上线后,我们要做的一个很重要的工作就是给我们的服务添加监控报警机制,否则我们就像瞎子一样,对我们系统服务运行情况一无所知。
关于报警系统业界优秀的报警系统有很多,使用的方案也基本大同小异。我们目前主要用的是开源的Prometheus报警系统,这里就不详细介绍了。
这里主要想说下我们在做报警的一些想法。比如我们经常遇到的一个问题就是报警邮件狂轰滥炸,每天能收到成百上千的报警邮件,这样很容易让系统中一些重要的报警信息石沉大海。对此,我们主要以下三个方面来考虑:
- 质疑需求的合理性
- 报警聚合
- 追踪溯源
首先,在业务方提出报警需求的时候,我们就需要学会质疑他们的需求,因为并不是每个需求都是合理的,其实很多开发他们并不懂报警,也不知道如果去监控自己的服务。这时候就是发挥我们运维人员的价值了。我们可以在充分了解服务架构属性的前提下提出我们的意见,和开发人员共同确定每个服务需要报警的关键指标。
其次,我们可以对报警做预聚合。现在我们的服务大都都是多机部署的,一个服务有可能部署到成百上千台机器上。有时候因为人为失误或者上线策略等原因,可能导致该服务集体下线,这时就会有成百上千来自不同主机的相同报警信息发送过来。
对于这种场景,我们可以通过报警聚合的方式,将一段时间内相同的报警合并成一条信息,放在一封邮件里面发送给开发人员,从而避免邮件轰炸的情况发生。关于报警聚合,像Prometheus这样的报警系统自身已经支持,所以也不会有太多的开发量。
最后,再高层次,我们就可以通过一些策略、算法去关联我们的报警。很多时候,一条服务链路上的某个环节出现问题可能导致整条链路上的多个服务都触发了报警,这个时候,我们就可以通过服务与服务之间的相关性,上下游关系,通过一些依赖、算法等措施去屏蔽关联的报警点,只对问题的根因进行报警,从而减少报警触发的数量。
图2-9是我们运维团队17年优化报警期间,报警数量的走势。
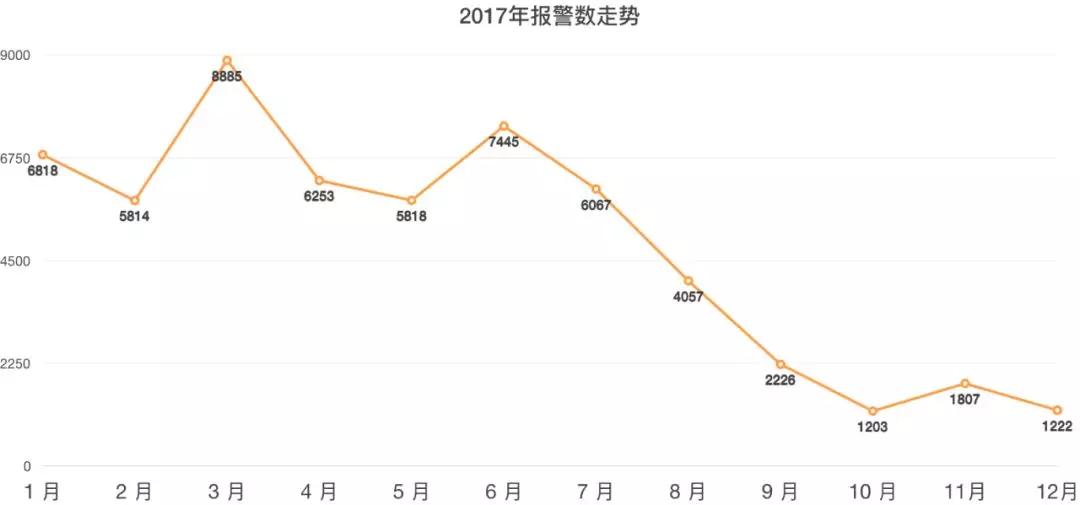
▲ 图2-9 有效的报警
4、全链路Trace系统
除了添加报警以外,在服务上线后,我们还会经常需要跟踪我们整个服务链路处理请求的性能指标需求。这时就需要有一套全链路的Trace系统来方便我们实时监控我们系统链路,及时排查问题,定位问题。
在全链路Trace系统中,最重要的就是Traceid,它需要贯穿整个链路,我们再通过Traceid来关联所有的日志,从而跟踪一条请求在整个系统链路上的指标行为。图2-10是我们约定的用于全链路Trace的日志格式信息。
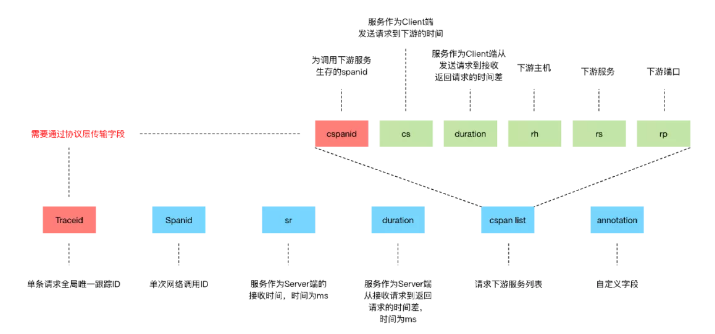
▲ 图2-10 日志格式与解析
有了日志后,我们就可以基于这些日志进行分析关联,就像上面说的,Traceid是我们整个系统的核心,我们通过Traceid来关联所有的日志。如图2-11所示,所有的日志会写入Kafka中,并通过Flink进行实时的日志解析处理,写入ClickHouse中。有了这些关键指标数据后,我们就可以在此基础上去做我们想做的事,比如形成服务拓扑进行请求跟踪、日志的检索以及指标的统计分析等。
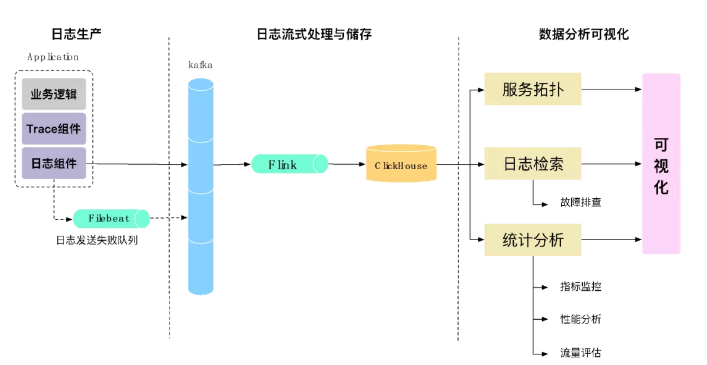
▲ 图2-11 数据收集与处理
在所有的数据收集解析完成后,业务方就可以根据一些维度,比如UID,来跟踪用户的在整个广告系统中请求处理情况,如图2-12所示。随后再将查询的数据以Traceid维度进行关联展示给用户。
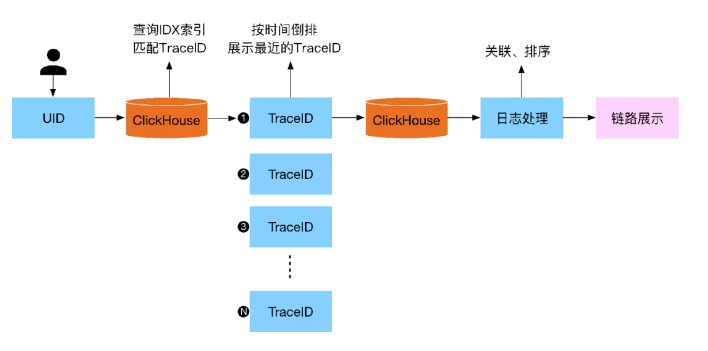
▲ 图2-12 业务查询
三、海量指标监控平台Oops实践
最后我们看下我们如何应对微博广告海量指标数据下多维的监控需求。前文也说了,监控报警就像我们的眼睛,能够让我们实时的看到我们系统内部的运行情况,因此,每一个服务都应该有一些关键指标通过我们的监控报警系统展示出来,实时反馈系统的健康状态。
如图3-1所示,做一个监控平台很容易,我们将指标、日志等数据进行ETL清洗后写入一个时序数据库中,再通过可视化工具展示出来,对于有问题的指标通过邮件或者微信的方式报警出来。但是在这个过程中,随着我们数据量的增长、我们指标的增长以及查询复杂度的增加,我们可能会遇到监控指标延迟、数据偏差以及系统不稳定等问题。
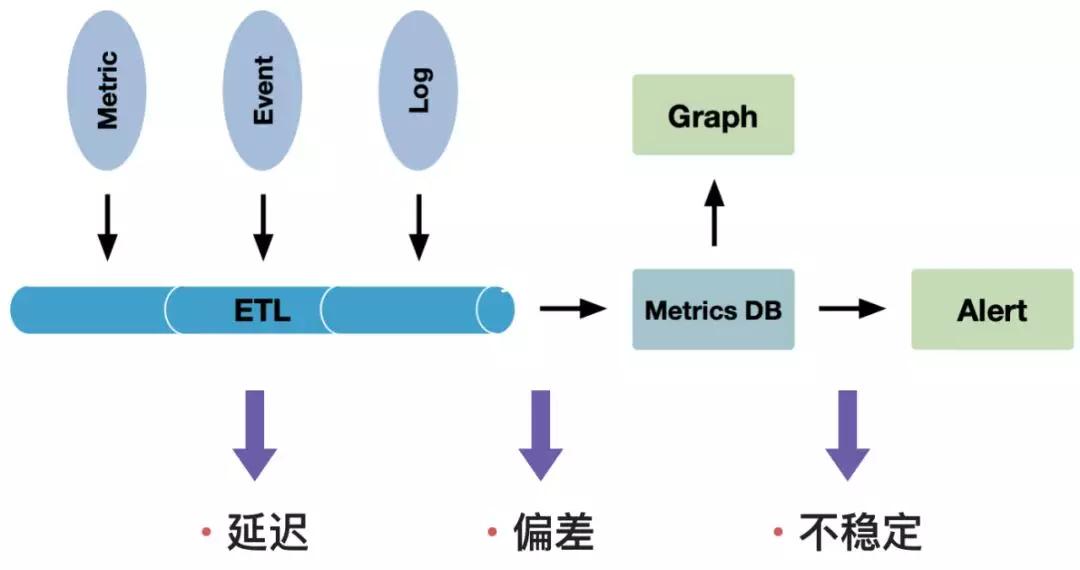
▲ 图3-1 监控平台的挑战
因此,在设计我们的监控系统时,就不能仅仅基于实现考虑,还需要考虑它的稳定性、实施性、准确性,同时还应尽量把系统做的简单易用。
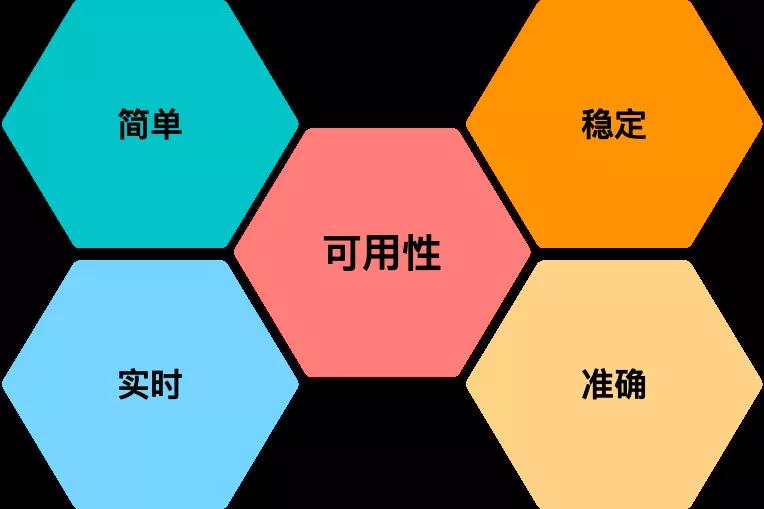
▲ 图3-2 监控平台的目标
而我们目前的监控平台Oops,也是基于上述原则,经历了多年的迭代和考验。图3-3是我们Oops监控平台当前的整体架构。
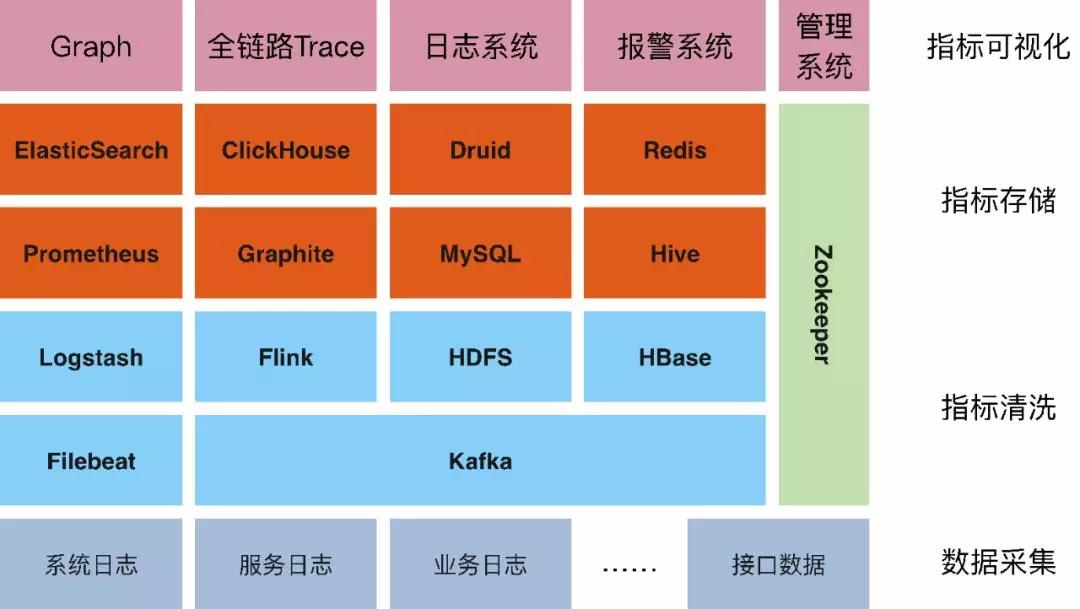
▲ 图3-3 Oops监控平台架构
① 数据采集
整个平台分为四个层次,首先是我们的数据采集。我们当前主要通过Filebeat这样一款优秀的开源采集客户端来采集我们的日志。对我们使用而言,Filebeat足够的高效、轻量,使用起来也很灵活易用。
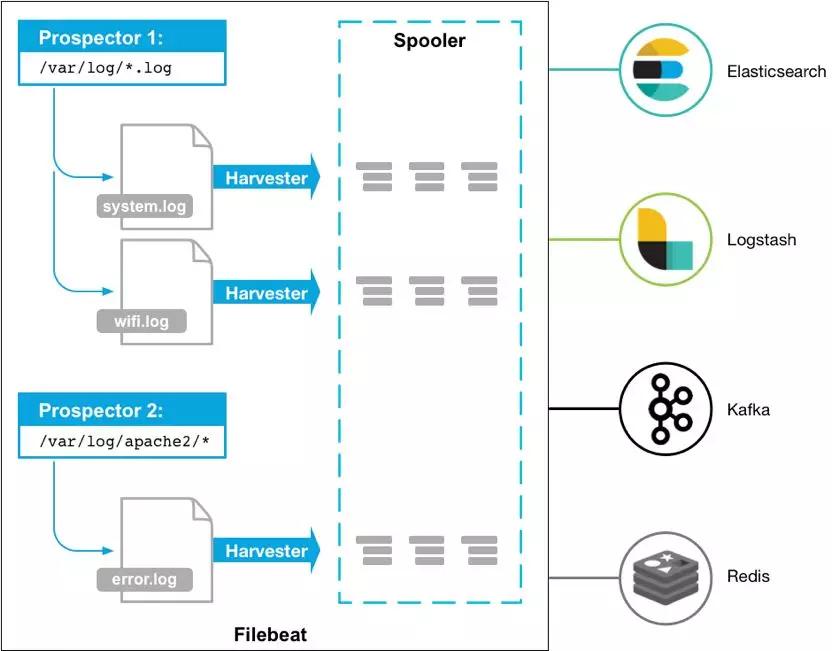
▲ 图3-4 Filebeat架构图
② 指标清洗
数据采集到Kafka后,我们再根据具体的业务需求将指标提取出来。如图3-5所示,当前我们主要通过Flink来解析日志,并写入ClickHouse中。
同时,针对一些业务需求,我们需要将一些指标维度做关联处理,这里主要通过HBase实现指标的关联,比如,有曝光和互动两个日记,我们将曝光日志中的mark_id字段作为rowkey写入HBase中,并储存一个小时,当在时间窗口内互动日志匹配到相同的mark_id时,就将曝光日志的内容从HBase中取出,并与互动日志组合成一条新的日志,写入到一个新的Kafka Topic中。
此外,我们还将Kafka中数据消费写入ElasticSearch和HDFS中,用于日志检索和离线计算。
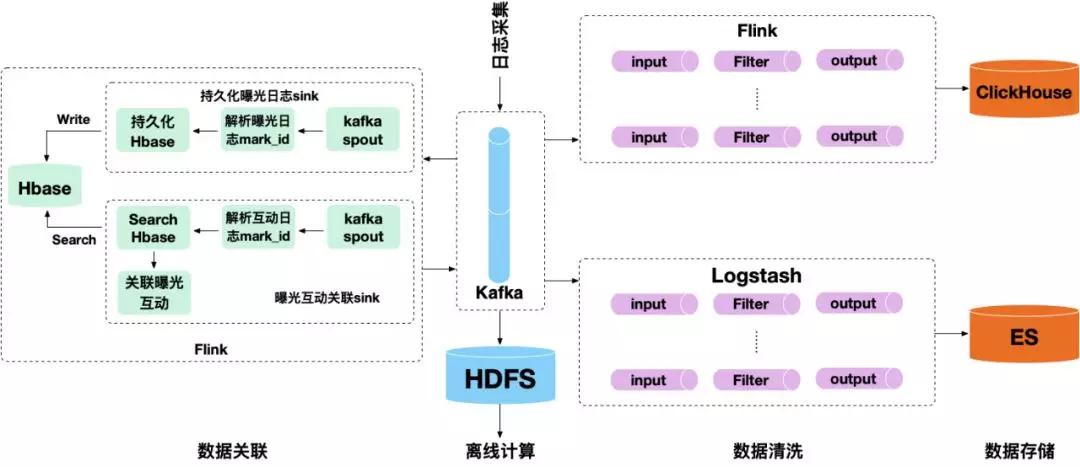
▲ 图3-5 指标清洗
③ 指标储存
当前,我们通过ClickHouse来储存查询我们的监控指标。最初也是选择了流行的时序数据库Graphite。但是在长期的使用中,我们发现在复杂的多维分析上,Graphite并没有很好的体验。在去年,我们将我们的监控指标引擎替换成了现在的ClickHouse,ClickHouse是一款优秀的开源OLAP引擎,它在多维分析等功能上相比传统的时序数据库具有很大的优势。
同时,我们基于ClickHouse强大的函数功能和物化视图表引擎构建了一个实时的指标仓库。如图3-6所示,我们会将清洗后的指标写入到一张原始表中,比如这里的ods_A,我们再根据具体的监控需求在ods_A表上进行维度的聚合。再比如,我们将请求维度按秒聚合成agg_A_1s,或者按照psid维度按分钟聚合成agg_A_1m_psid,又或者我们按照用户id维度来统计每个用户的访问次数。
由此我们可以实现不同时间维度和不同业务维度的组合分析查询,同时提升了查询响应速度,以及数据的重复利用率。而原始表的存在也让我们可以根据不同的需求定制不同的复杂的聚合表数据。
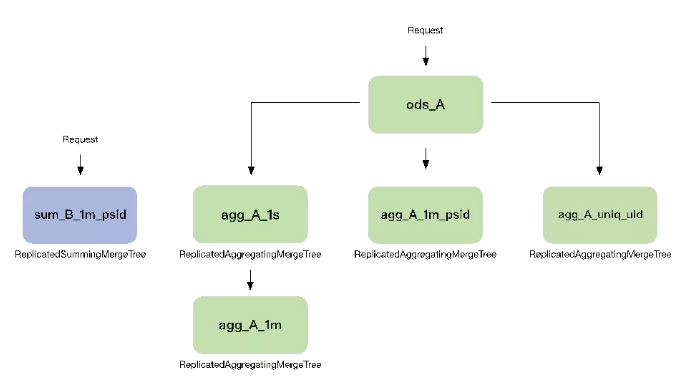
▲ 图3-6 实时指标仓库
④ 指标可视化
最后,我们通过Grafana实现我们的指标可视化,Grafana应该是当前全球最受欢迎的监控可视化开源软件,它支持很多的数据源,而ClickHouse也是其中之一,我们只需要写一条SQL就可以按照我们的想法在Grafana上以图表的形式呈现出来。如图3-7呈现的监控图就是图3-8这样一条简单的SQL实现的。
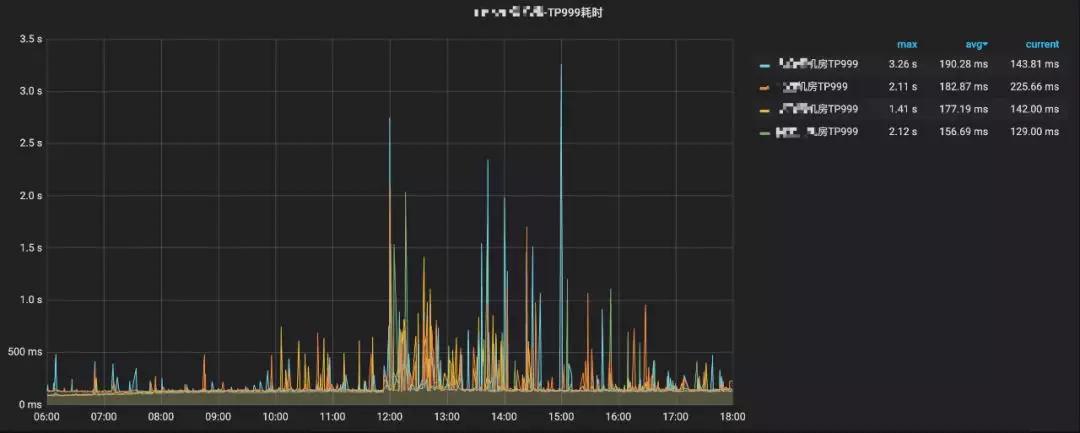
▲ 图3-7 折线图监控指标

▲ 图3-8 折线图监控指标SQL语句
对于表格的指标监控展示,也很简单,也是一条SQL就能完成的,如图3-9所示。
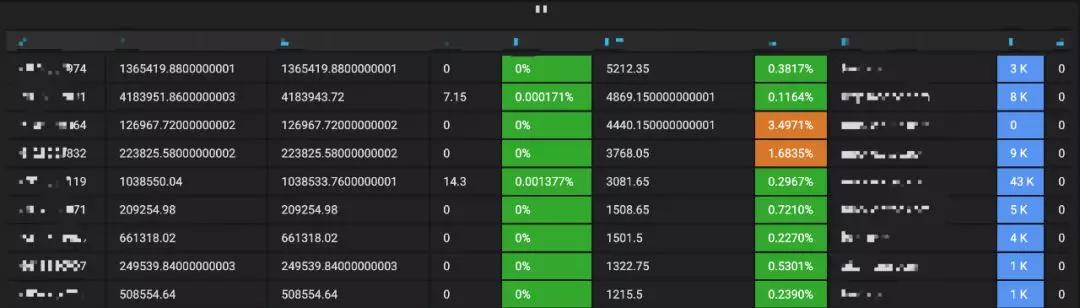
▲ 图3-9 表格监控指标
当前我们的实时指标仓库存储120T的数据量,峰值处理QPS在125万左右,秒级查询、多维分析,为微博广告的指标监控、数据分析以及链路跟踪等场景提供了底层数据支撑。
讲师介绍
朱伟,微博广告SRE团队负责人,书籍《智能运维:从0搭建大规模分布式AIOps系统》作者之一。目前负责微博广告业务可用性的保障与优化、资源利用率的提升、监控报警系统的建设以及自动化体系的推进。
















