前边我们分享了网络分层协议、TCP 三次握手、TCP 四次分手。今天我们继续深入分享一下 TCP 中的拥塞控制。
对于 TCP 的拥塞控制,里边设计到很多细节,小鹿希望通过这一节能够将这部分内容串通起来,能够让你更深刻的记忆这部分内容。
思维导图
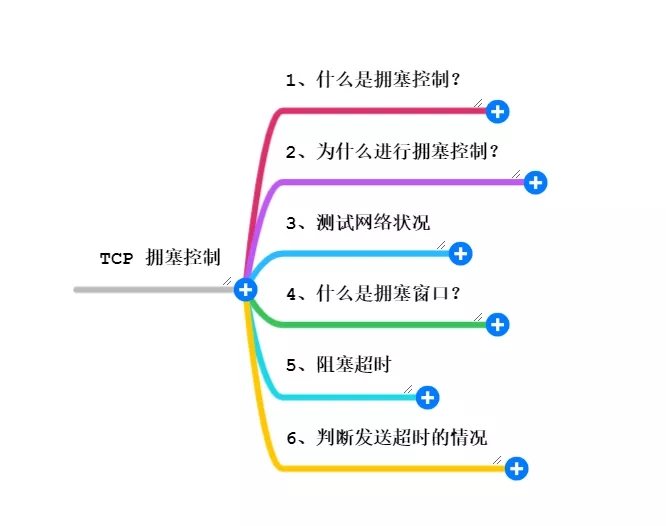
1. 什么是拥塞控制?
拥塞控制是一种用来调整传输控制协议(TCP)连接单次发送的分组数量的算法。它通过增减单次发送量逐步调整,使之逼近当前网络的承载量。
简单易懂的话来说,所谓的拥塞控制,从字面的意思来讲,网络通信就像是一个水管里的水,如果水突然因为水管的赃物阻塞了,那么我们就应该采取一定的策略,让其在阻塞的时候如何处理。
2. 为什么进行拥塞控制?
如果发送端要给接收端发送数据,只有当接收端接收到数据时,才会给发送端返回应答信息。如果接收端没有发送应答信息,发送端则认为该数据已经丢失,则进行重新发送。
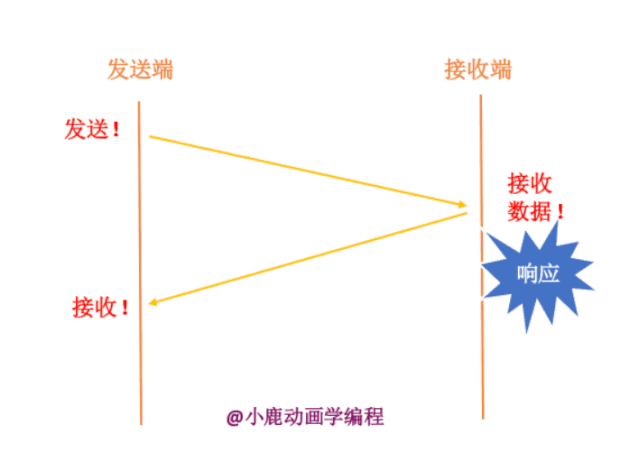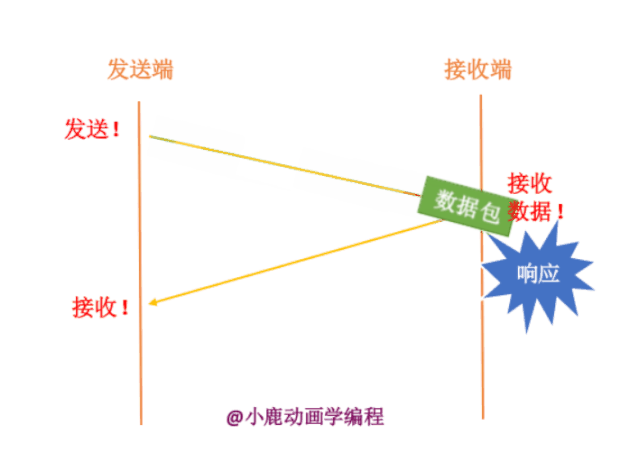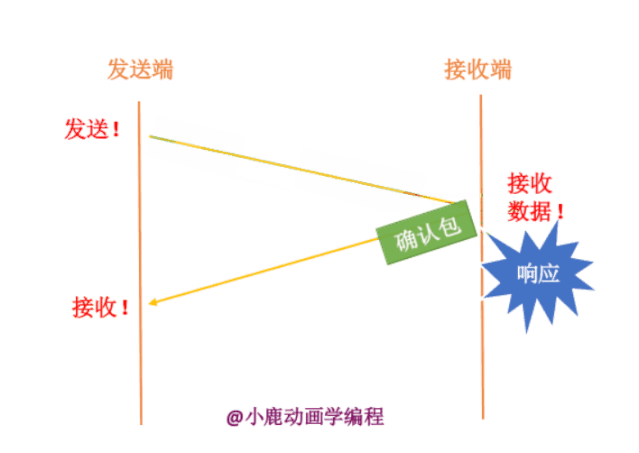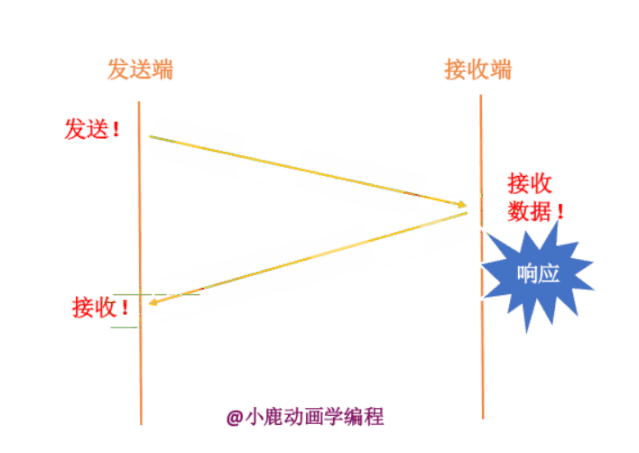
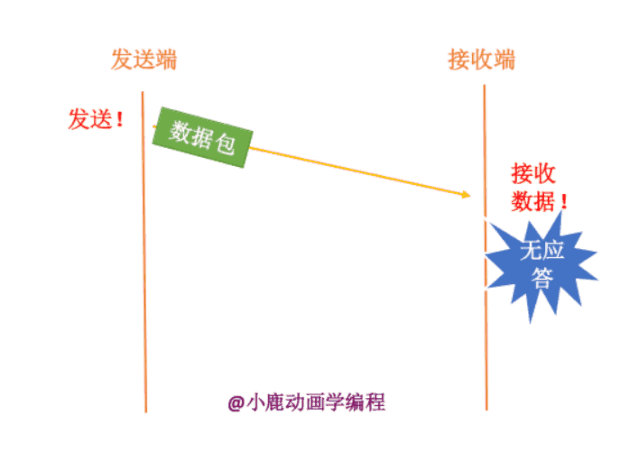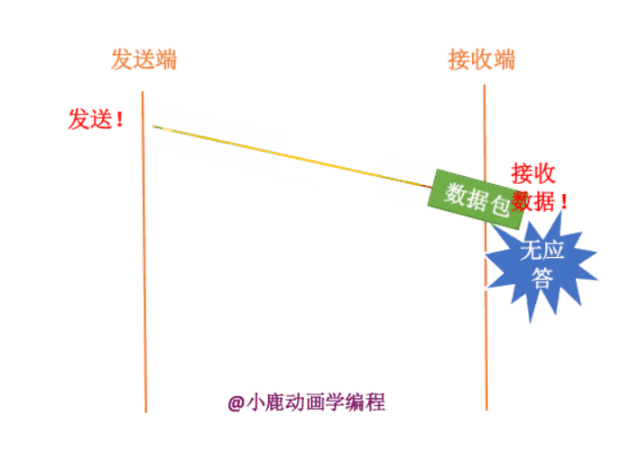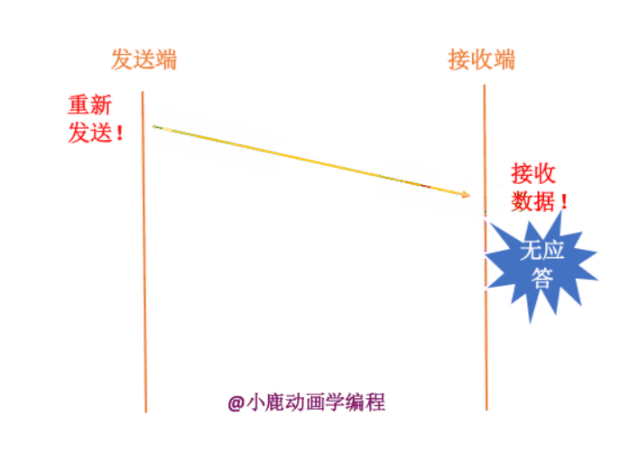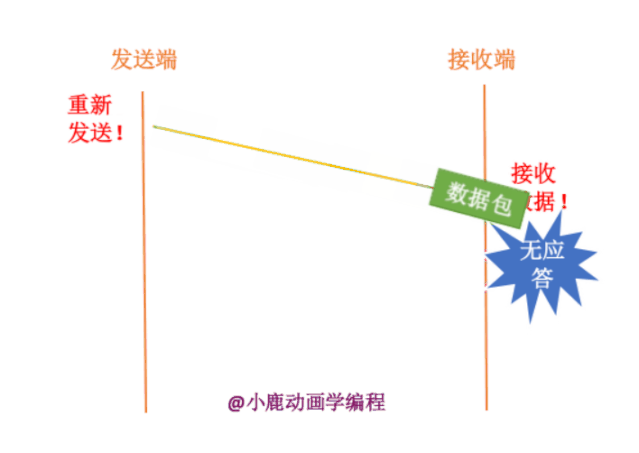
其实我们也不知道接收端有没有接收,数据包到底在哪一步出现了问题呢?分为两种情况,如下:
1. 数据包真的在半路丢失了
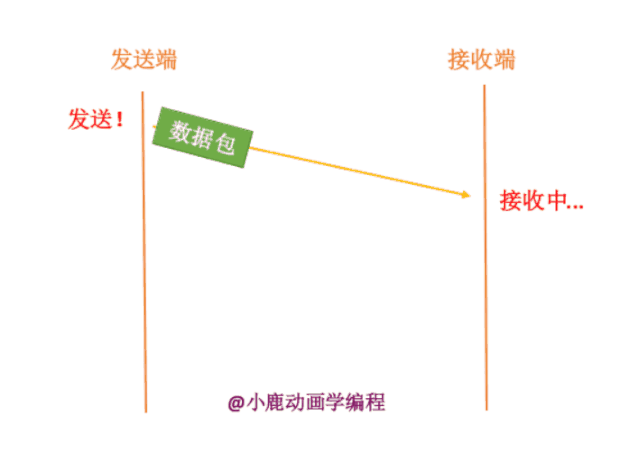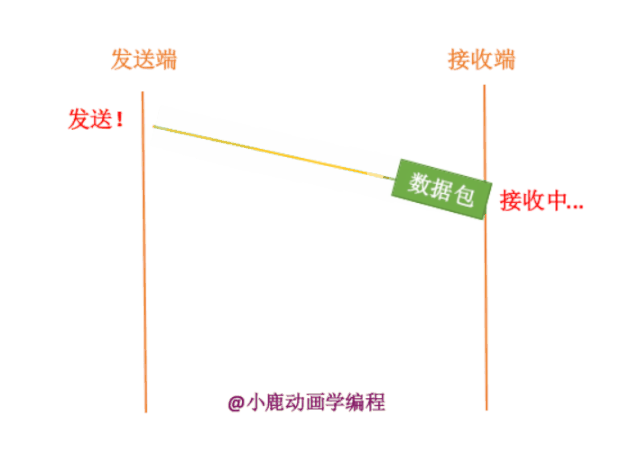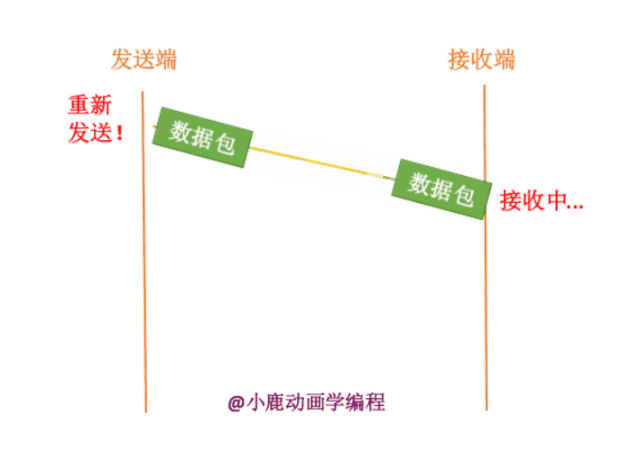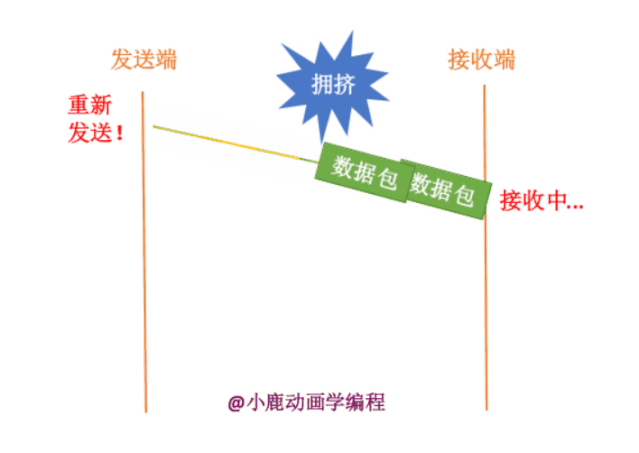
2. 网络通信处于拥挤状态,数据包还没有到达接收方。
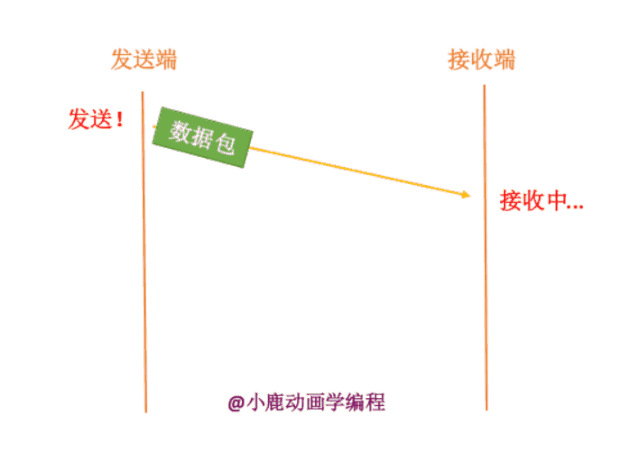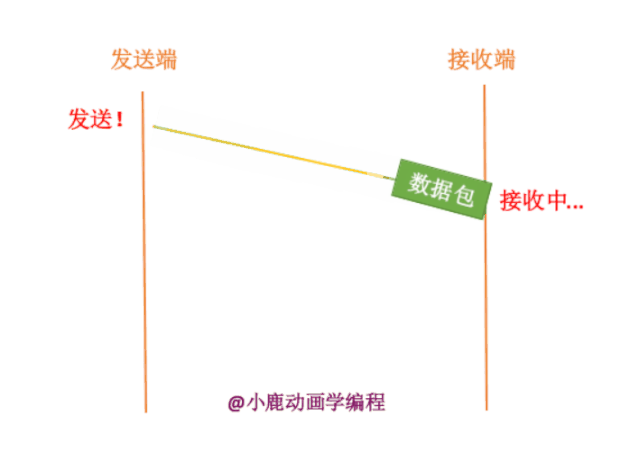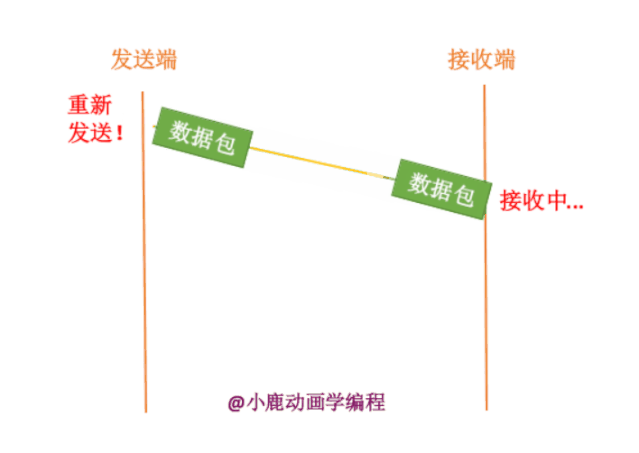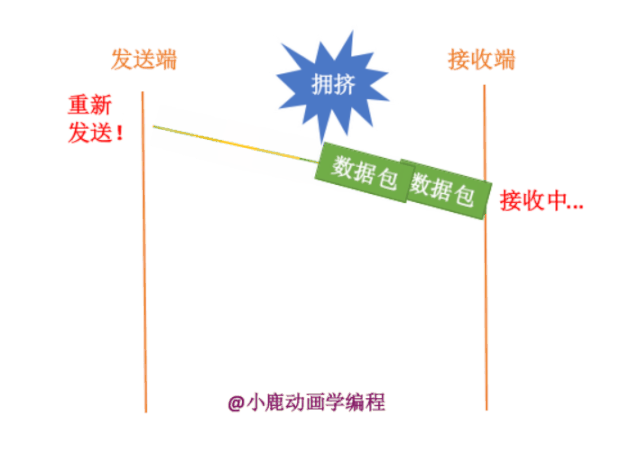
我们的拥塞控制是主要针对于第二种情况的。如果网络信道中一直处于拥挤状态,那么发送端一直进行发送,就会变得更加的阻塞,而且同时白白浪费掉了网络的资源。
3. 测试网络状况
我们进行拥塞控制之前,首先要判断网络信道是否阻塞了,当判断出网络阻塞时,我们才能进行拥塞控制。我们一般通过向网络中连续发送多个数据包来进行测试,测试过程中,如果发送数据包到达了一定的程度,网络通信就会阻塞。
有以下两种探测网络的情况,第一种就是逐渐递增发送数据包,一次只发送一个数据包,第二次发送两个,第三次发送三个,以此类推,总会在一个点发送网络拥堵情况
第二种情况就是指数型的增长,顾名思义,就是发送数据包以指数的形式进行增长,第一次发生一个,第二次发送两个,第三次发送四个...也会在某一时刻网络进行拥堵。
但是第一种方法有一个问题就是增长的太慢,当到达到拥塞时,需要经历很长的时间,这种探测的方式效率太低。
当我们使用第二种方法时,指数增长就会出现增长的太快,会错过增长的点。
既然两种方式各有所长,我们就结合两种方式,首先我们进行指数增长,我们设定一定的阀值,然后到达阀值之后,然后进行逐次递增,直到出现网络拥塞为止。
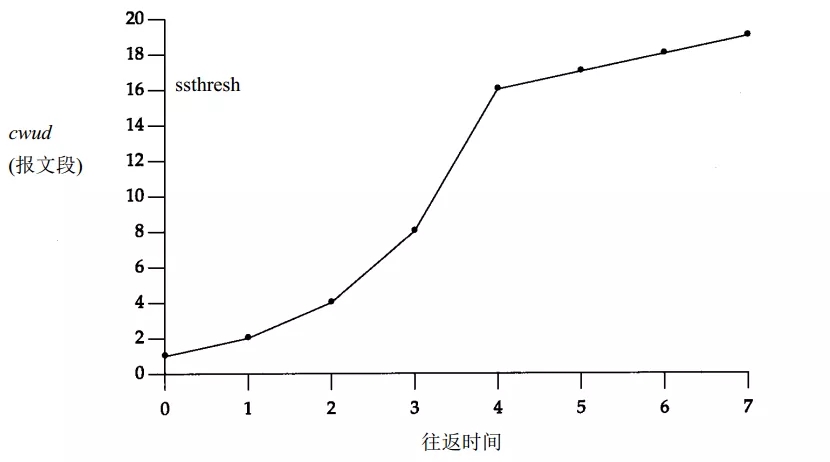
- 指数增长阶段称为慢启动
- 逐次增长称之为拥塞避免
4. 什么是拥塞窗口?
我们把一次性能够发送的数据包多少的窗口称之为拥塞窗口。
我们通过控制发送窗口的大小,也就是发送数据包的多少来进行拥塞控制。
5. 阻塞超时
当数据包增长到一定程度就会出现超时事件(阻塞),出现超时事件就认为网络拥塞了,不能再继续增长了,此时标记为一个最大值 M。
如果超时了之后,我们开始进行拥塞控制,怎么做呢?我们将增长的阀值进行降低,降低到 M 的一半大小,也就是 M/2。如下图所示,最大值为 24,此时发生拥塞,所以将阀值降为 12。
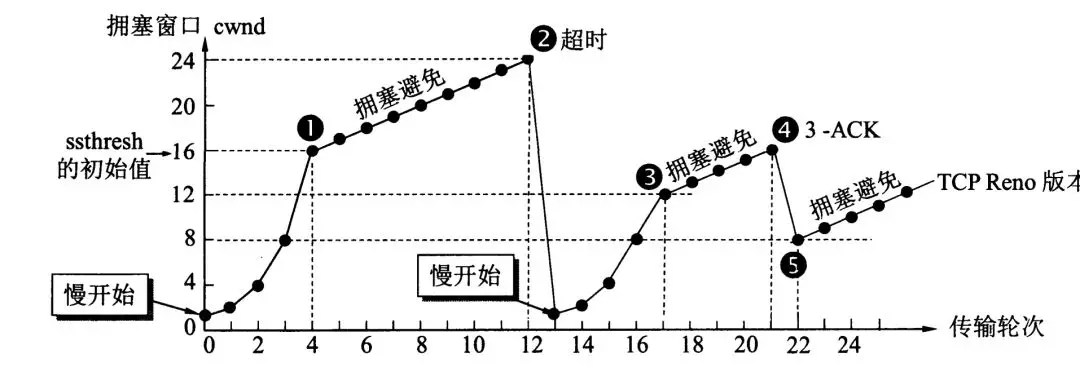
有的小伙伴就说了,你那超时不一定发生阻塞了,上边你也提到了,可能出现了数据包的丢失,那怎么判断这种情况呢?
6. 判断发送超时的情况
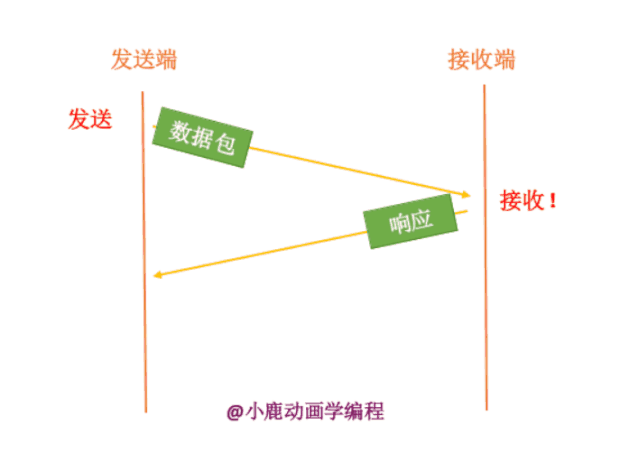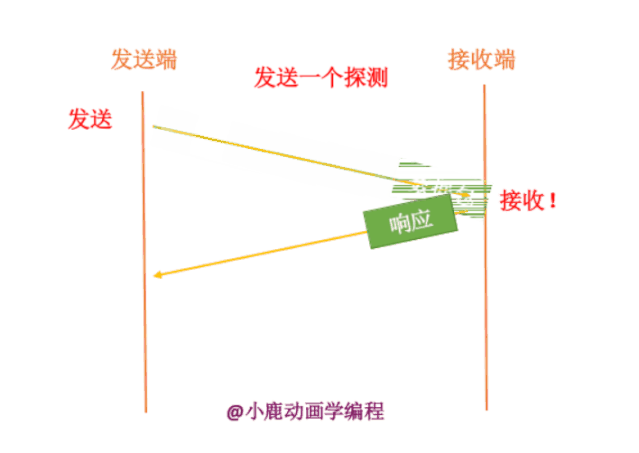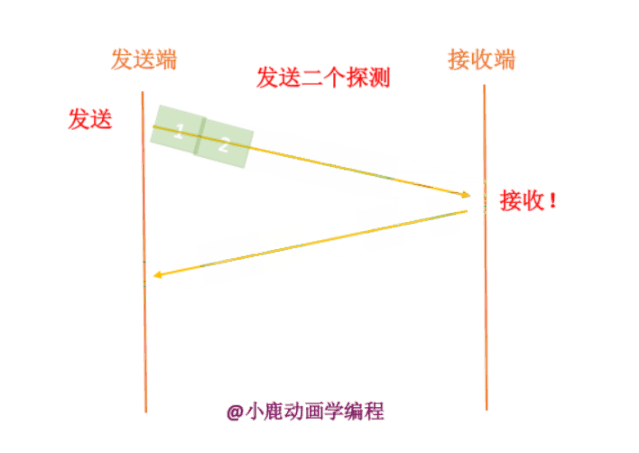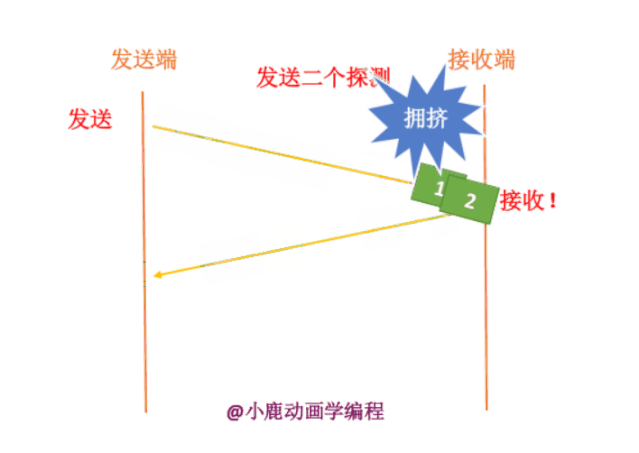
我们上边也说了,超时存在两种情况,我们就采用连续发送 ACK 的方式来进行判断到底是网络阻塞了还是网络数据包丢失了。
如下图所示,如果发送一个数据包,接收端成功接收之后,就会返回一个响应数据包,然后发送端再次发送下一个数据包。
一旦发送端在发送数据包的时候中途丢失了,接收端会返回上一次接收的数据包的确认响应数据包,当发送端连续接收到三个相同的响应数据包时,就说明该数据包丢失了,然后快速重传该数据包。
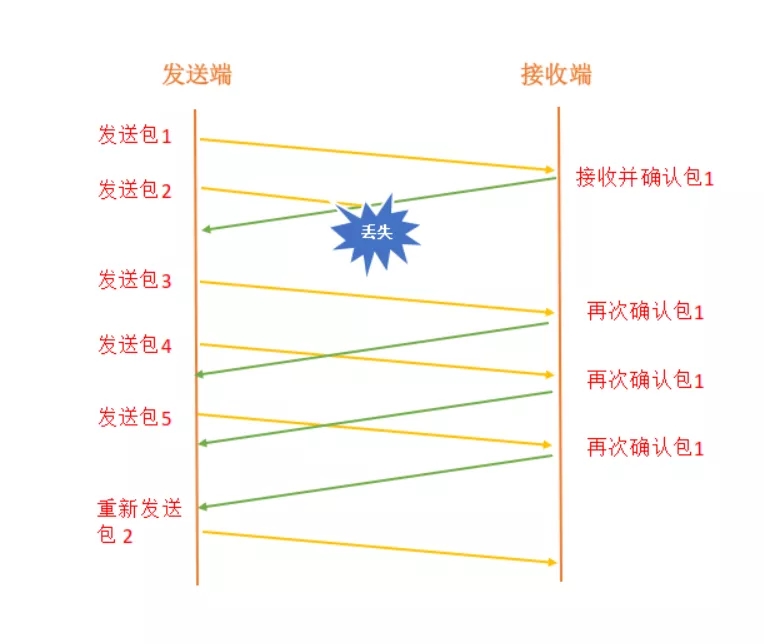
然后会把我们的阀值设置为拥塞最大值 M 的一半,这时候的拥塞窗口的大小为 1,当拥塞窗口的大小等于阀值时,再进行线性增长。我们也把上边这种情况称之为快速恢复。
小结
今天主要分享了 TCP 的拥塞控制,为什么会有拥塞控制?如何进行拥塞控制以及如何判断网络中的情况。
通过拥塞控制,我们能够更好地进行数据高效的传输,除此之外,我们后边的文章还会更新 TCP 的流量控制,为了能够使得网络中的流量得到充分的利用。