













年薪百万数据科学家
上班时间在线摸鱼!?
怎么回事!
请听小编为您分解
▼
近几年
AI行业发展得如火如荼
数据科学家也跟着吃上了“香饽饽”
江湖传言
刚毕业的AI博士起薪50W
2年经验的薪水100W+
貌似一当上数据科学家
分分钟就能实现财富自由
数据科学家是否
真的像传言那般光鲜亮丽呢?
今天我们有幸采访到了李博士
来看下数据科学家的工作状态吧
离开熟悉的科研机构后,李博士被一家AI初创企业以七位数年薪收入麾下,担任机器视觉部门的数据科学家。
上班第一周,熟悉了新环境和同事后,李博士连上公司分配的GPU服务器,开始一个图像分割模型训练。
启动任务后,李博士没有像人们想象地那样开始在各种机器前忙碌,而是起身接了一杯咖啡,随即悠悠然坐进软椅,转向论文研究工作。
咦?什么情况?数据科学家在线摸鱼?
当然不是!
其实这也是李博士的无奈之举,他痛心疾首地说道:“算力是AI发展的一大阻碍啊!”按照以往经验,在当前CNN模型的复杂度和训练数据量条件下,要3-4天才看得到训练结果,结果出来之前除了等待别无他法。
这不禁让我们联想起90年代之前的大学,同学们先到计算中心排队,然后将自己的应用程序输到机房计算机中,此后要用相当长的时间来等待计算结果。

半个多世纪以来,摩尔定律让计算性能取得了飞跃,现在一台智能手机的计算能力,已经可以赶上80年代的超级计算机了。而今天,对计算力的渴望,我们和半个世纪以前的人们依然没有什么区别。
AI领域的计算力渴望
2018年,OpenAI发布了一份关于AI计算能力增长趋势的分析报告,报告显示:自2012年以来,AI训练中所使用的计算力每3.43个月增长一倍,过去6年时间里,这个指标已经增长了30万倍以上——这便是OpenAI针对AI计算领域提出的新摩尔定律。
每当有数据科学家质疑AI计算平台的性能时,从事计算工作的朋友们就会很委屈:没有计算力上做出的成绩,怎么会有这波AI应用的热潮?如果没有吴恩达2011年将GPU应用于谷歌大脑所取得的成功,人工智能的第三次热潮恐怕还要晚几年才能到来。
但是,AI就像是一个正在长身体的小宝宝,天天哭着找妈妈要奶吃。相较传统的机器学习算法,深度学习对计算力的要求更高。
比如,2012年摘得ImageNet图像分类大赛冠军的AlexNet网络,包含8层神经网络,6000万个参数;2015年夺冠的ResNet网络,深度已经达到了152层;另外,一个图像分类模型VGG-16,参数量也达到了1.38亿;而现在有些语言识别模型,参数量已经超过10亿!
为应对AI算力要求,当前国内AI基础架构普遍采用的是Scale-up GPU架构,即在单台服务器上部署4张、8张甚至更多张GPU卡,每个任务使用设备中的全部或者部分资源。这种架构的优点就是实施简单,操作容易。
但是,随着模型复杂度加深、计算力要求提高,单机多卡模式越来越力不从心。另外,一味增加单机GPU密度,也会加大数据中心的供电和散热压力,此时一旦出现服务器问题障,就很可能造成业务故障。
面对种种问题,难道AI算力再上一步发展的空间就没有了吗?
这里,我们还是要相信IT基础架构建设者的智慧。在过去的2019年春天,可以看到国内AI计算领域有了很多不一样的改变:精细化、集群化、多元化——三把“利剑”齐发力,AI计算正朝着人们所期望的高性能、可扩展模式迈进。
第一把利剑:精细化
精细化是指不改变现有计算架构,“深挖洞,广积粮”,提高单个芯片计算性能,以达到更高的整体性能。
目前,仅仅依靠提高GPU的浮点计算和显存带宽指标来实现算力提升已经有些困难,大家开始尝试降低AI训练和推理过程中的精度要求。
例如,在Nvidia V100和T4上提供TensorCore混合精度特性,TensorCore让最耗费计算性能的矩阵乘法在FP16半精度工作,矩阵加法和最终输出结果仍可以在FP32工作。与经典的FP32单精度训练相比,混合精度降低了对带宽与显存容量的需求,使训练性能实现倍增。
同样,在推理领域,Int8或其他低精度推理方式正在被更多数据科学家尝试。深度学习端到端pipeline优化,可以平衡计算、存储IO、网络传输性能,使数据以更快速度流动和计算。
相关机制主要包含框架的多线程、预读机制,NVME SSD小文件IO优化、PCI-Eswitch或NVLink提升参数同步网络性能,以及使用GPU进行图像数据预处理的新技术(DALI)等。
在这方面,戴尔易安信针对AI GPU计算专门设计的服务器C4140(1U机箱支持4块全宽GPU)和DSS 8440(4U机箱支持10块全宽GPU),集成了很多针对深度学习参数快速同步和小文件IO的硬件优化技术,可以为AI研究提供良好的算力支持。
戴尔易安信DSS 8440
虽然精细化可以让芯片发挥最佳计算性能,不过单节点挖潜毕竟是有上限的,既然云计算、HPC、大数据等Scale-out模式如火如荼,是不是可以让AI计算也插上集群计算的翅膀呢?
答案是肯定的。
第二把利剑:集群化
所谓集群化,就是让更多处理器参与到计算加速中,以满足深度学习对算力的需求。
当前主流的深度学习框架,像TensorFlow、PyTorch、MXNet、Caffe2等,均已提供对GPU集群分布式训练的支持。当然,GPU分布式训练比单机训练要复杂,需要端到端设计来保证多机多卡训练的性能。
如果把AI计算集群比作一辆汽车,加速芯片就相当于汽车的发动机,网络如同传统系统,存储好比是汽车的油箱,而调度软件就起着方向盘的作用。
每一个Batch训练中,GPU都需要在极短的时间内完成亿级别参数同步,对网络带宽和延迟要求极高。实践证明,相比传统的TCP/IP网络传输,采用基于RDMA或者RoCE的GPU Direct computing技术,可以大幅有效地提升参数同步的网络传输性能。
IO侧,NLP、机器视觉和语音识别中,需要大量使用KB级小文件进行训练,GPU处理速度又很快,集群环境将数据放到共享文件存储系统中,因而对存储系统小文件IO处理性能有着非常高的要求。
而Lots of small files的文件读写方式,恰恰是众多存储系统性能的“命门”。
依托多年非结构化数据存储的经验积累,戴尔易安信针对深度学习小文件性能优化,提供Isilon Scale-out NAS、Lustre并行文件系统、基于AI/HPC环境优化的NFS存储系统(NSS)三个存储利器,可满足不同环境规模、容量和性能要求。

在2018年完成的一项测试中,以戴尔易安信Isilon F800全闪存存储作为72块Nvidia V100 32GB GPU集群的后端存储,进行主流图像分类模型训练,这个测试中,GPU使用率可以达到97%,训练数据放置于GPU服务器,本地SSD硬盘与共享存储对训练性能的影响只有2%,基本做到存储性能无瓶颈。
此外,GPU分布式集群训练中,除了更高性能的计算、存储与网络架构,如果能在软件层面上做一些优化,比如优化GPU参数同步效率,那么软硬结合将事半功倍。戴尔易安信将最新软件优化机制与高性能基础架构硬件结合,可以实现最好的分布式训练性能。

例如,传统TensorFlow分布式训练,采用参数服务器机制,各个GPU通过数据同步训练得到的参数,需要通过参数服务器进行参数同步,再分发到集群中各GPU。而网络传输参数量大的时候,参数服务器会成为性能瓶颈。
Horovod则对TensorFlow参数同步机制进行了优化,取消参数服务器,改为Ring Allreduce方式,这种方式下,所有参与计算的N个GPU排成一个“握手环路”,将训练参数分成N份,每一次GPU只与环中上一个和下一个GPU交换1/N的参数,通过N-1个时间周期完成全部交换。
实践证明,RingAllreduce对传输带宽的利用率最高。
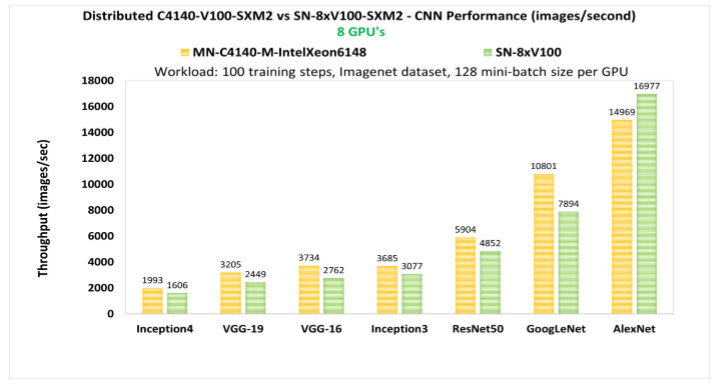
而更大规模的分布式训练集群,32张V100构成的GPU集群,在MXNet框架下进行ResNet50图像分类训练,性能表现为单GPU卡性能的29.4倍;采用Caffe2框架,加速比为26.5倍。
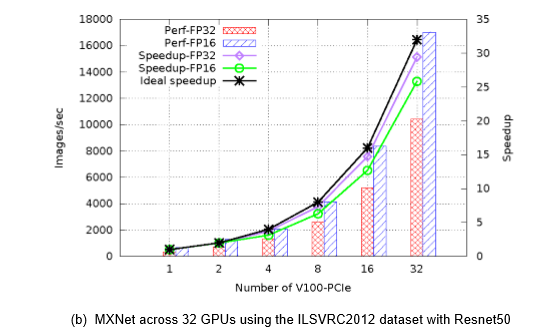
由此可见,在提高算力方面,集群化的功效非同一般。
第三把利剑:多元化
在同等算力要求下,芯片功耗也是AI研究中比较关注的地方。很多企业异构计算小组正在寻找更高性能或功耗更低的解决方案,目前,FPGA和ASIC是替代GPU的两大热门方向,AI异构加速也是戴尔易安信一直在研究的技术领域。
FPGA
FPGA采用硬件可编程逻辑门电路设计,具有丰富的可重配置的片上资源,运行时无需加载并解释指令,具有高并发、低延迟、低功耗的优良特性。在嵌入式推理、云端高并发低延迟推理和视频图像预处理等AI领域,FPGA值得期待。
目前,戴尔易安信的计算解决方案可以支持Intel和Xilinx两大主流FPGA加速方案。

不过,FPGA应用面临的最大问题是开发难度,这需要工程师能够比较熟练地掌握硬件描述语言HDL。这方面,戴尔易安信与Intel携手,希望将2018年12月在重庆揭牌的FPGA中国创新中心,打造为加速FPGA人才培养与应用落地的基地。

ASIC
基于ASIC的AI专用芯片(如谷歌的TPU)也同样备受关注。戴尔科技集团投资了一家AI芯片初创企业——Graphcore,Graphcore总部位于英国的,目前估值17亿美金,其AI加速芯片IPU计划于19年下半年上市。
Graphcore IPU加速卡,单张峰值性能250Tops,是Nvidia V100GPU的2倍。IPU采用同构多核架构,单片上提供2432个独立的处理器;它大量采用片上SRAM而非传统DRAM,参数权重存储在处理器的高速缓存。

单台戴尔易安信DSS 8440服务器,最多可以支持8张IPU加速卡。在早先进行的一些深度学习训练和推理测试中,Graphcore IPU表现出了非常出色的性能:
如RNN领域最常使用的LSTM模型,IPU的训练性能是Nvidia V100 GPU卡的10倍;LSTM推理,IPU吞吐量可以达到V100的100倍,延迟为1/10;CNN ResNet-50推理方面,IPU单卡性能可达到V100的25倍。

我们有理由相信,随着AI计算精细化让芯片发挥最佳计算性能,集群化让更多处理器参与到计算加速,以及新一代更强大的AI芯片的商用,未来就绪的AI基础架构有能力迎接AI计算新摩尔定律的挑战。
未来,估计李博士喝咖啡品茶等待运算结果的时间将越来越短,这对李博士们而言是好事还是坏事?
大概率是好事吧!


















