












刚刚结束的双十一,天猫交易额达到 2684 亿元,较去年同比增长 25.7%。这一结果背后,云计算、人工智能等技术以及阿里巴巴工程师们的努力功不可没。在正在召开的 AICon 全球人工智能与机器学习技术大会 现场,阿里云智能计算平台事业部研究员林伟介绍了阿里基于飞天 AI 平台的人工智能技术及能力,揭开双 11 大规模交易场景下,阿里人工智能技术的神秘面纱。

人工智能生态发展趋势
大家好,我是林伟,我今天演讲的主题是《AI 突破无限可能—5 亿消费者的云上双 11》。我本人是做系统出身的,但在最近的一些会议上发现,越来越多做系统出身的人开始研究 AI。在 90 年代末的那波热潮里,我有幸在学校的人工智能实验室呆过,那时还在纠结模型效果,最后发现是自己想多了,那时做出来的东西还远远达不到可用的状态。在后来的一段时间内,AI 进入沉寂,最近几年又突然火爆,我在一些学校做交流的时候发现很多同学都在研究 AI 算法,但其实神经网络、遗传算法和模拟算法很多年前就已经出现,最近几年才爆发的最主要原因是数据和算力的提升。
在这之中,云计算也起到了很大作用,只有算力更加充足,才可以拟合出更加有效的模型,这也是阿里巴巴 2009 年坚定投入云计算的重要原因。说到阿里云,其实阿里云有个非常大的客户就是阿里巴巴自己的电商业务,而阿里电商全年最重要的一个活动就是双 11。
过去几年,阿里双 11 的营业额逐渐升高,这背后更深层次的原因其实是我们实现了核心系统的 100% 上云。上云之后,我们发现 AI 离不开计算,只有具备强大的计算力才可以利用 AI 技术提高效率,双 11 就是一个很好的练兵场。在这样的规模下,如何构造系统、处理数据以及迅速挖掘数据背后的价值是我们在思考的问题。
在整个大趋势下面,我们可以看到三个因素:
一是实时化。 双 11 就一天,我们必须理解数据并及时反馈给商家,实时性非常重要,双 11 大屏背后的支撑系统就是通过 Flink 实现实时计算。单纯的销售额可能没有特别大的意义,我们需要进行实时分析以得到更细致的指标,比如用户的购买兴趣、商品类别、供销比、渠道、仓储位置和货源等,我们需要通过实时分析及时反馈给商家、快递公司等,让各方都可以明确如何调整双 11 当天的策略。今年双 11,我们每秒可以处理 25.5 亿条消息,包括买卖消息、快递请求等。

二是规模性。 我们不仅需要实时反馈,双 11 结束还需要精细对账给银行和商家。今年,我们仅花费一天时间(也就是 11 月 12 日)就完成了所有报表汇报,这就是通过云平台的弹性来实现的。在这么大的规模下,商家服务效率也是一个问题,原来就是靠人,用电话和小二来服务商家,现在这样的规模体系下就需要用 AI 技术来服务商家,并通过 AI 辅助快递配送,比如机器人可能会询问用户:在不在家?包裹放在哪里等问题。在大家以往的印象中,AI 离生活很远,但辅助快递配送就是一个很具体的场景,可以为用户带来更好的体验,包括淘宝首页的个性化推荐等。
如今,淘宝推荐也会有一些动态封面,这背后是我们一天分析了 2.5 亿个视频的结果,现在的淘宝上也有很多用短视频卖货宣传的,我们分析了 2.5 亿视频,最后日均商品分析达到 15000 万。我们统计了当天通过视频购买商品的人,发现平均有效时长是 120 秒。通过这种新技术可以促进新的场景。
三是 AI。 这一切的背后是数据的力量,整个双 11 都是 AI 和数据在驱动。实时性、规模性和 AI 三者相辅相成让双 11 的效率得到了大幅提高,计算处理能力也有了很大提高,这就是 2684 亿销售额背后的技术力量。
云上双 11 的 AI 能力
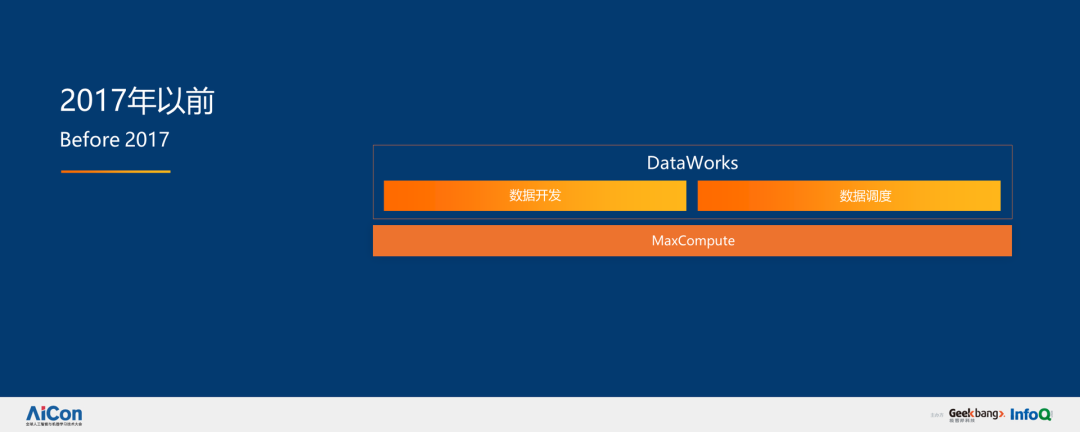
回归技术本身。2017 年以前,我们的系统是比较简单的,更多的任务是处理数据和生成报表。一年半以前,我们开始加入更多实时性,用实时数据反馈商业决策,这就有了 MaxCompute 的出现。

如今,整个技术后台非常复杂,我们有非常好的一些计算引擎,可以进行全域数据集成,具备统一的源数据管理、任务管理,智能数据开发和数据合成治理等能力。
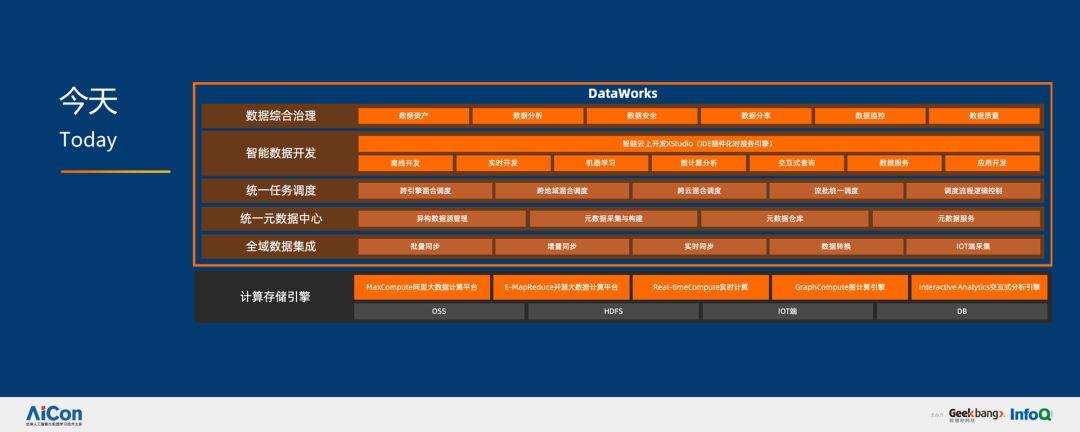
说到底,AI 和计算其实是共生体,AI 的繁荣依赖于计算力的积累,所以我们需要很好的数据处理平台进行分析和提取,服务好算法工程师进行创新,比如尝试各种各样的模型、各种各样构造机器学习的方式,看看能否提高人工智能的效率和准确度。
企业如何构建云上 AI 能力
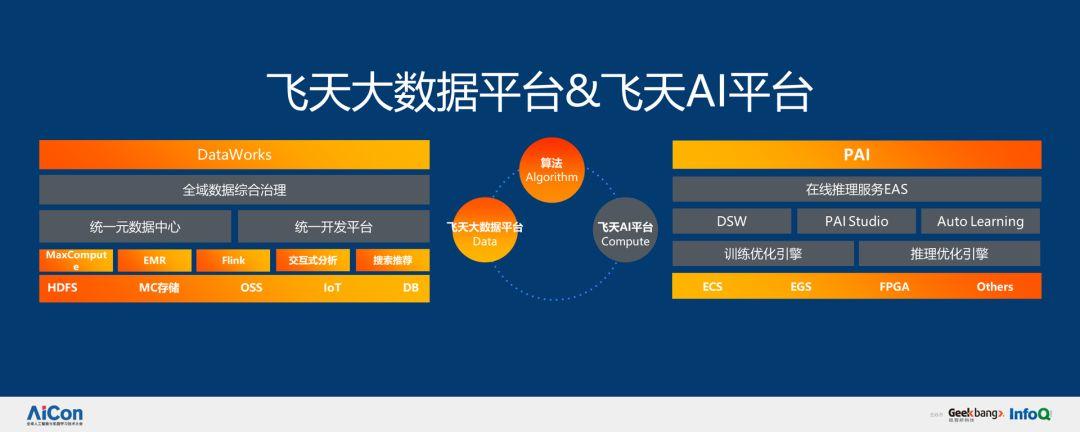
上述这些主要是 AI 的场景,接下来,我会着重介绍这些场景背后的 AI 技术,主要围绕飞天 AI 平台,上层是 PAI 和在线推理服务 EAS,然后分为 DSW 开发平台,PAI Studio 和 Auto Learning 三部分,基于训练优化引擎和推理优化引擎,解决大规模分布式数据处理问题。
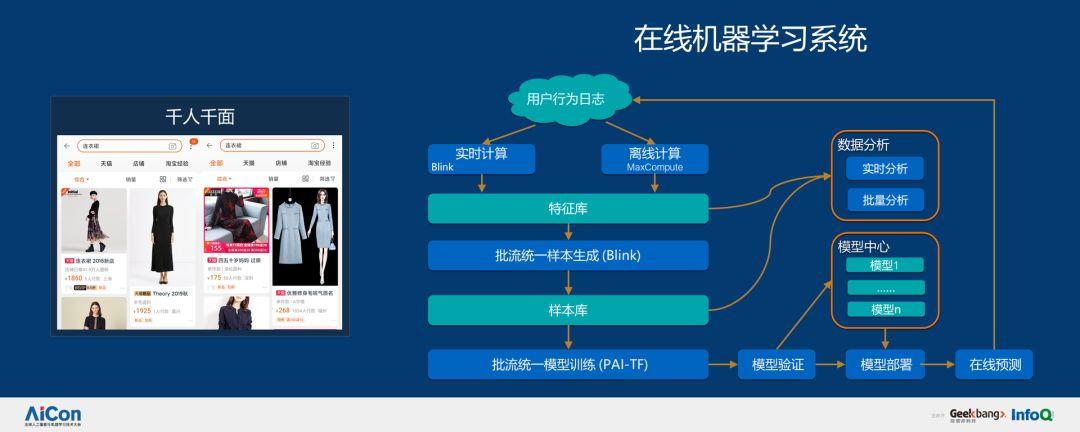
此外,我们还有在线机器学习系统,可以对用户行为日志进行实时和离线计算,然后抽取特征库,生成批流统一样本,进入样本库,最终进行批流统一模型训练。为什么我们要做这个?一是因为实时性,传统的搜索是非常不敏感的,而我们是在遵循用户兴趣的变化,如果两周更新一次模型可能已经错过了几轮热销商品,我们需要通过在线机器学习的方式进行实时判断,这非常接近于深度学习。在非实时的状态下,工程师可以非常精细的做特征工程,花更多的时间理解数据,利用深度学习本身的特性捕获数据之间的关系,而不是靠专家提取,这是深度学习的好处,但这需要海量的计算才可以完成,而在线机器学习系统会把双 11 当天的日志及时传递到实时计算平台做集合,然后通过分析按照 ID 对数据进行聚合形成样本,最后根据样本做增量学习、验证、部署,只有这样才能快速更新模型,使其遵循用户或者商业的变化。
在这个过程中,我们面临的第二个挑战是模型非常大,因为要“千人千面”,因此需要一个非常大且针对稀疏场景的分布式训练。目前的开源机器学习框架还远远达不到我们的规模要求,我们需要进行大量的优化,以便在稀疏场景下训练大规模数据。如果对深度学习有了解,就应该知道深度学习可以描述非常大的细粒度图,在图上如何进行切割让图的计算和通讯可以更好地平衡是需要考虑的问题。
通过通信算子融合和基于通信代价的算子下推,我们实现了分布式图优化技术。通过高效内存分配库,比如 thread 库、Share Nothing 执行框架;利用 Spares 特性的通讯;异步训练,通讯和计算充分 overlap;容错、partial checkpoint、autoscale、动态 embedding;支持大规模梯度 optimizer 的方法实现运行框架的优化,如下图所示:
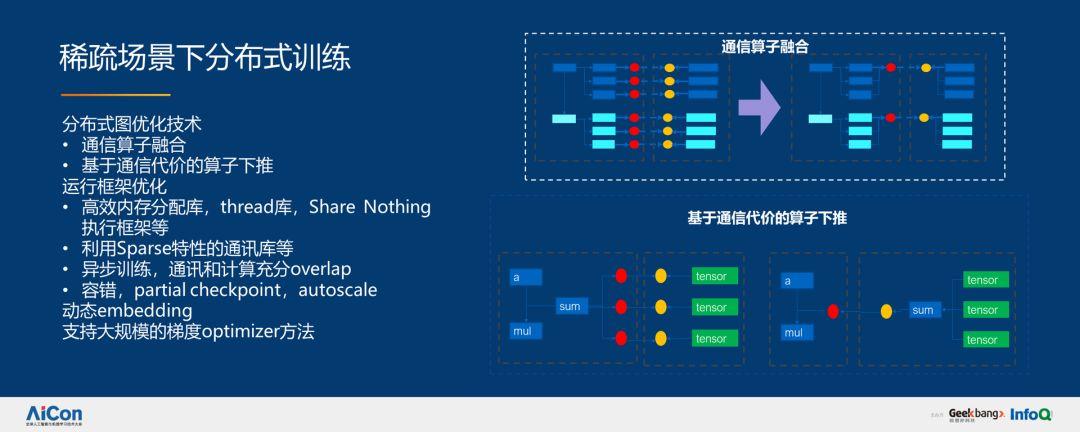
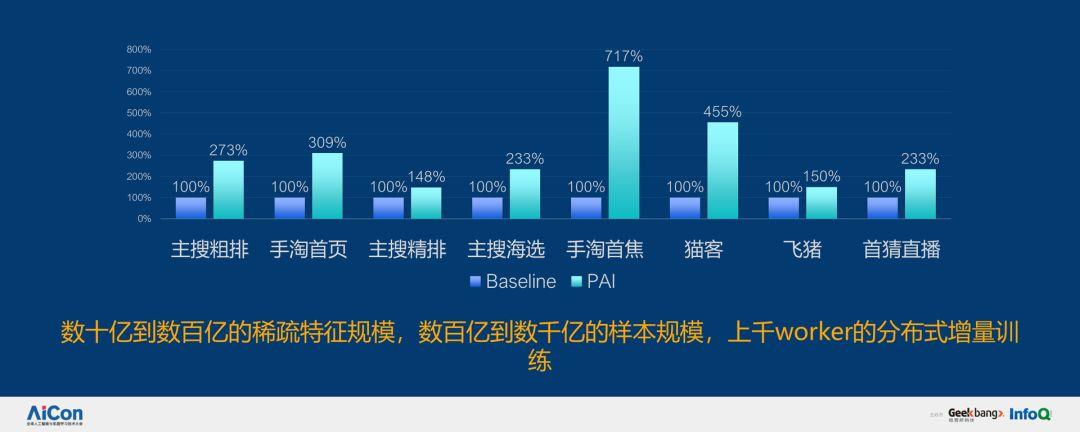
优化之后,性能上达到了七倍提升。稀疏特征规模从数十亿到数百亿,样本从数百亿到上千亿,同时还有上千亿 worker 的分布式增量训练。
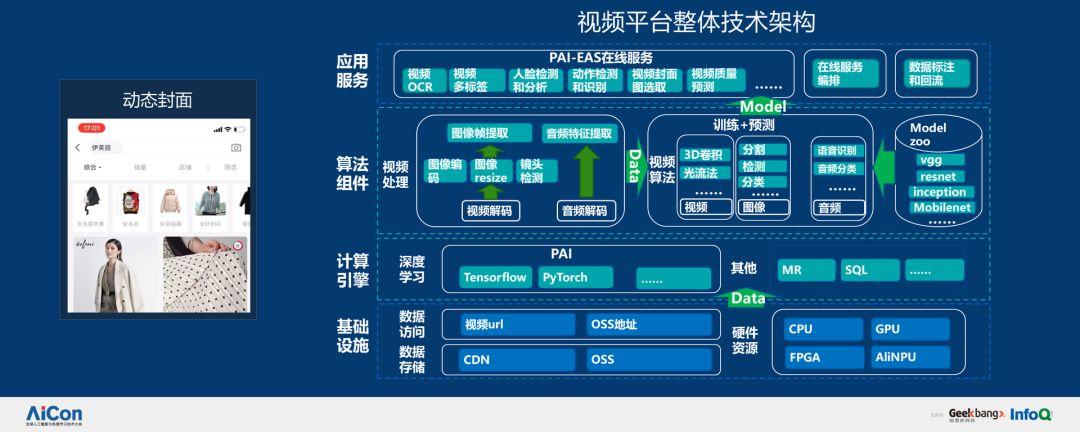
在动态封面层面,我们分析了大量视频文件,视频比图片更复杂,因为视频牵涉的环节非常多,需要做视频的预处理,提取视频帧,但不可能每一帧都进行提取,这样做的代价实在是太大了,需要提取视频的关键帧,通过图片识别和目标检测提取,这是很复杂的工作。因此,我们研发了视频平台,帮助视频分析和算法工程师解决问题,具体架构如下图所示:
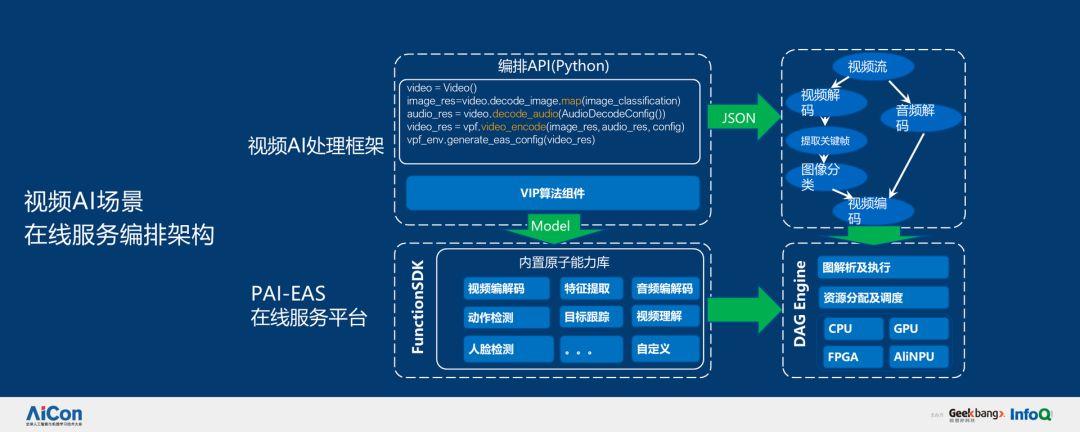
在视频里面,在线服务其实也很复杂,有分解,也有合成。首先对视频进行分解,然后加以理解并提取,最后进行合成。通过视频 PAI-EAS 在线服务平台,算法工程师只需要编写简单的 Python 代码就可以通过接口调用相应服务,让他们有更多的时间进行创新。
除了上述场景,整个平台最重要的就是支持算法工程师的海量创新。五年以前,阿里的算法模型非常宝贵,写算法的人不是特别多。随着深度学习的演进,现在越来越多的算法工程师在构造模型。为了支撑这些需求,我们进行了 AI 自动化,让算法建模同学专注业务建模本身,由系统将基础设施(PAI)完成业务模型的高效、高性能运行执行。
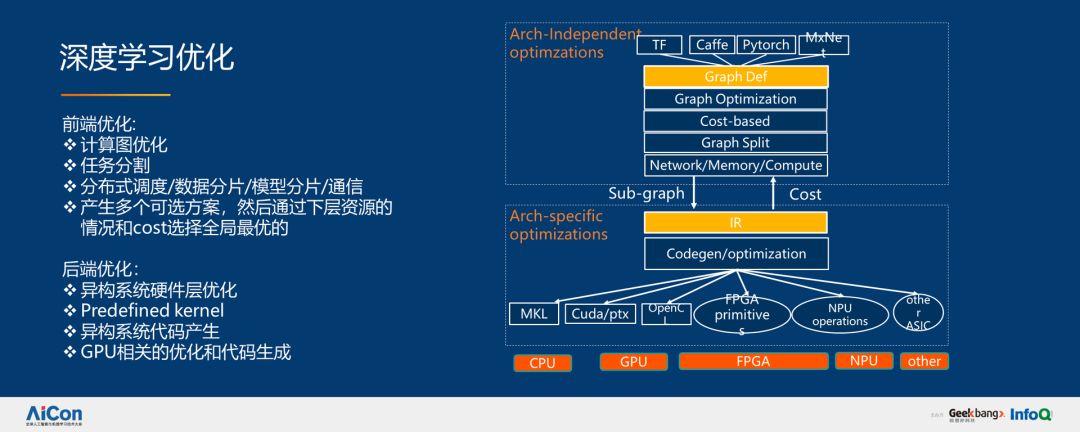
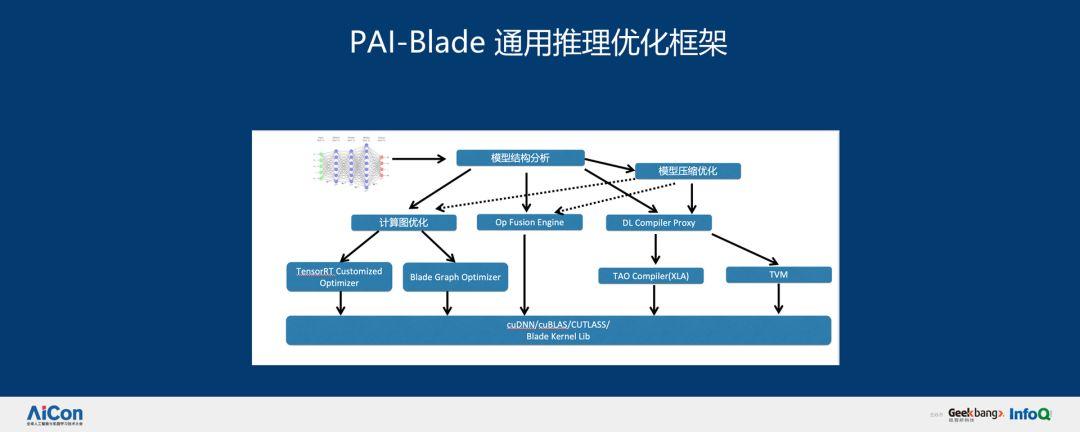
在深度学习方面,我们分别进行了前端和后端优化。我们希望通过编译技术,系统技术服务实现图优化、任务分割、分布式调度、数据分片、模型分片,通过系统模型选择我们认为最好的方案执行,这是我们整个平台做 PAI 的理念。整个 PAI-Blade 通用推理优化框架分为如下几部分:
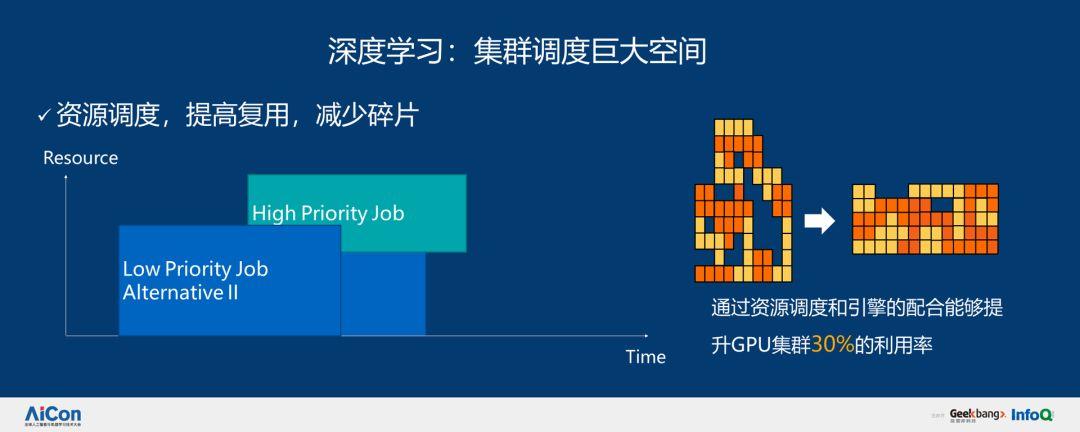
通过系列改进,我们也取得了一些优化成果。我们有一个非常大的集群,在集群足够大的时候,我们就可以很好地实现复用。通过资源调度和引擎的配合能够提升 GPU 集群 30% 的利用率。
此外,我们很多 AI 服务都加载在线服务框架,我们叫做 PAI EAS,这个框架是云原生的,可以更好地利用云平台本身的规模性和可扩展性,撑住双 11 当天的海量 AI 请求。因为双 11 不仅是商业数据、购买数据在暴涨,AI 请求也在暴涨,比如智能客服、菜鸟语音当天的服务量都非常大,通过利用云平台的能力,我们可以提供更好的体验。

综上,这些技术支撑了阿里巴巴的所有 BU,支持单任务 5000+ 的分布式训练,有数万台的机器,数千 AI 的服务,日均调用量可以达到上十万的规模。最后,阿里双 11 的成长和 AI 技术的成长以及数据的爆发密不可分。
嘉宾介绍:
林伟,阿里云智能计算平台事业部研究员,十五年大数据超大规模分布式系统经验,负责阿里巴巴大数据 MaxCompute 和机器学习 PAI 平台整体设计和构架,推动 MaxCompute2.0,以及 PAI2.0、PAI3.0 的演进。加入阿里之前是微软大数据 Cosmos/Scope 的核心成员,在微软研究院做分布式系统方面的研究,分别致力于分布式 NoSQL 存储系统 PacificA、分布式大规模批处理 Scope、调度系统 Apollo、流计算 StreamScope 以及 ScopeML 分布式机器学习的工作。在 ODSI、NSDI、SOSP、SIGMOD 等系统领域顶级会议发表十余篇论文。















