照片由 Franck V 发布在 Unsplash 上
本文转自雷锋网,如需转载请至雷锋网官网申请授权。
阅读本文后,你将能够部署机器学习模型,并用你想要的编程语言进行预测。没错,你可以坚持使用 Python,也可以通过 Java 或 Kotlin 直接在你的 Android 应用程序中进行预测。另外,你可以直接在你的 web 应用程序中使用该模型——你有很多很多选择。为了简单起见,我会用 Postman。
不过,我不会解释如何将这个模型放到一个实时服务器上,因为选择太多了。该模型将在你的本地主机上运行,因此,你将无法从不同的网络访问它(但请随意使用 google 查询如何将模型部署到 AWS 或类似的东西上)。
我已经做了以下目录结构:
ML 部署:
-
model / Train.py
-
app.py
如果你已经通过 Anaconda 安装了 Python,那么你可能已经预先安装了所有库,除了 Flask。因此,启动终端并执行以下语句:
- pip install Flask
- pip install Flask-RESTful
进展是不是很顺利?很好,现在让我们来看看好东西。
制作基本预测脚本
如果您正在遵循目录结构,那么现在应该打开 model/Train.py 文件。你先要加载虹膜数据集,并使用一个简单的决策树分类器来训练模型。训练完成后,我将使用 joblib 库保存模型,并将精度分数报告给用户。
这里并不复杂,因为机器学习不是本文的重点,这里只是模型部署。下面是整个脚本:
- from sklearn import datasets
- from sklearn.tree import DecisionTreeClassifier
- from sklearn.model_selection import train_test_split
- from sklearn.metrics import accuracy_score
- from sklearn.externals import joblib
- def train_model():
- iris_df = datasets.load_iris()
- x = iris_df.data
- y = iris_df.target
- X_train, X_test, y_train, y_test = train_test_split(x, y, test_size=0.25)
- dt = DecisionTreeClassifier().fit(X_train, y_train)
- preds = dt.predict(X_test)
- accuracy = accuracy_score(y_test, preds)
- joblib.dump(dt, 'iris-model.model')
- print('Model Training Finished.\n\tAccuracy obtained: {}'.format(accuracy))
部署
现在你可以打开 app.py 文件并执行一些导入操作。你需要操作系统模块:Flask 和 Flask RESTful 中的一些东西,它们是 10 秒前创建的模型训练脚本,你还要将它们和 joblib 加载到训练模型中:
- import os
- from flask import Flask, jsonify, request
- from flask_restful import Api, Resource
- from model.Train import train_model
- from sklearn.externals import joblib
现在你应该从 Flask RESTful 中创建 Flask 和 Api 的实例。没什么复杂的:
- app = Flask(__name__)
- api = Api(app)
接下来要做的是检查模型是否已经训练好了。在 Train.py 中,你已经声明该模型将保存在文件 iris-model.model 文件中,并且如果该文件不存在,则应该首先对模型进行训练。训练完成后,可以通过 joblib 加载:
- if not os.path.isfile('iris-model.model'):
- train_model()
- model = joblib.load('iris-model.model')
现在你需要声明一个用于进行预测的类。Flask RESTful 使用此编码约定,因此你的类将需要从 Flask RESTful 资源模块继承。在类中,可以声明 get()、post()或任何其他处理数据的方法。
我们将使用 post(),因此数据不会直接通过 URL 传递。你需要从用户输入中获取属性(根据用户输入的属性值进行预测)。然后,可以调用加载模型的 .predict()函数。仅仅因为这个数据集的目标变量的格式是(0,1,2)而不是('Iris-setosa','Iris versicolor','Iris virginica'),你还需要解决这个问题。最后,你可以返回预测的 JSON 表示:
- class MakePrediction(Resource):
- @staticmethod
- def post():
- posted_data = request.get_json()
- sepal_length = posted_data['sepal_length']
- sepal_width = posted_data['sepal_width']
- petal_length = posted_data['petal_length']
- petal_width = posted_data['petal_width']
- prediction = model.predict([[sepal_length, sepal_width, petal_length, petal_width]])[0]
- if prediction == 0:
- predicted_class = 'Iris-setosa'
- elif prediction == 1:
- predicted_class = 'Iris-versicolor'
- else:
- predicted_class = 'Iris-virginica'
- return jsonify({
- 'Prediction': predicted_class
- })
我们就快完成了,加油!你还需要声明一个路由,URL 的一部分将用于处理请求:
- api.add_resource(MakePrediction, '/predict')
最后一件事是告诉 Python 去调试模式运行应用程序:
- if __name__ == '__main__':
- app.run(debug=True)
这样做就对了。你可以通过 Postman 或其他工具启动模型并进行预测。
为了防止你漏掉什么,这里是整个 app.py 文件,你可以参考:
- import os
- from flask import Flask, jsonify, request
- from flask_restful import Api, Resource
- from model.Train import train_model
- from sklearn.externals import joblib
- app = Flask(__name__)
- api = Api(app)
- if not os.path.isfile('iris-model.model'):
- train_model()
- model = joblib.load('iris-model.model')
- class MakePrediction(Resource):
- @staticmethod
- def post():
- posted_data = request.get_json()
- sepal_length = posted_data['sepal_length']
- sepal_width = posted_data['sepal_width']
- petal_length = posted_data['petal_length']
- petal_width = posted_data['petal_width']
- prediction = model.predict([[sepal_length, sepal_width, petal_length, petal_width]])[0]
- if prediction == 0:
- predicted_class = 'Iris-setosa'
- elif prediction == 1:
- predicted_class = 'Iris-versicolor'
- else:
- predicted_class = 'Iris-virginica'
- return jsonify({
- 'Prediction': predicted_class
- })
- api.add_resource(MakePrediction, '/predict')
- if __name__ == '__main__':
- app.run(debug=True)
好的,你准备好了吗?
不错!导航到根目录(app.py 就在根目录中),启动终端并执行以下操作:
- python app.py
大约一秒钟后,你将得到一个输出,显示应用程序正在本地主机上运行。
现在我将打开 Postman 并执行以下操作:
-
将方法更改为 POST
-
输入 localhost:5000/predict 作为 URL
-
在 Body 选项卡中选择 JSON
-
输入一些 JSON 进行预测
然后你可以点击发送:
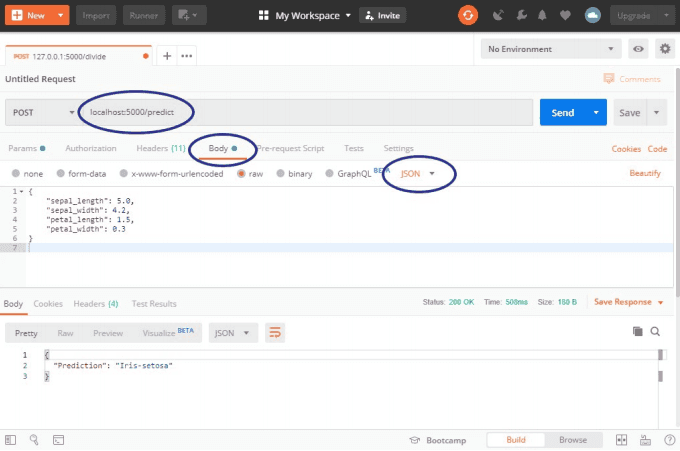
瞧!几乎马上你就能从你的模型中得到预测。
写在最后
我希望你能看完这篇文章。如果你只是复制粘贴的所有内容,只要你安装了所有必需的库,那么应该就可以继续。
我强烈建议你在自己的数据集和业务问题上利用这些新获得的知识。如果你用 Python 以外的语言编写应用程序,并且使用 Python 只是为了数据和机器学习相关的东西,那么它就很有用了。
via:http://t.cn/AirsMxVF