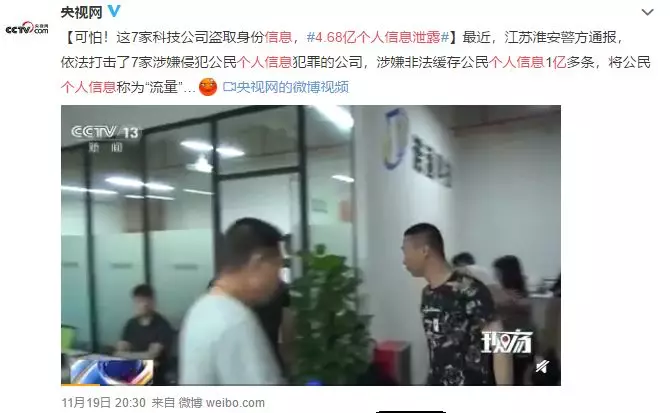
近日江苏淮安警方依法打击了 7 家涉嫌侵犯公民个人信息犯罪的公司,涉嫌非法缓存公民个人信息 1 亿多条。
其中,拉卡拉支付旗下的考拉征信涉嫌非法提供身份证返照查询 9800 多万次,获利 3800 万元。
警方已将考拉征信服务有限公司及北京黑格公司的法定代表人、董事长、销售、技术等 20 余名涉案人员抓获。
01.“爬虫”软件“爬出”的犯罪链条
警方发现,涉案的广州诺涵公司虽然披着科技公司的外衣,其实从事的是网络放贷、软暴力催收、贩卖公民个人信息等违法犯罪行为。
在他们贩卖的公民个人信息里,甚至还出现了公民身份证照片信息,这样极度隐私的个人信息他们从哪儿获取的呢?

警方发现,在广州诺涵科技公司,公民个人信息被称为“流量”,公司自己开发有“乐花管家”等多个小贷平台,在自身购买公民个人信息用于推销贷款、软暴力催收的同时,也和其他公司相互交换公民个人信息,还开发有爬虫云等软件,通过技术手段爬取其他小贷公司的公民个人信息,用于公司放贷和非法出售牟利。

锁定相关犯罪证据后,淮安警方在长沙、深圳分别将湖南九象公司的法定代表人和技术主管抓获。
审讯得知,九象公司黑爬虫网站的“身份核验返照”业务端口来自北京黑格科技有限公司,而黑格公司是从北京考拉征信服务有限公司等四家公司购买的查询接口。
随即,警方将北京黑格公司和考拉征信服务有限公司的法定代表人、董事长、销售、技术等 20 余名涉案人员抓获,并于今年 4 月在北京将他们上游公司的 5 名涉案人员抓获。
经查,北京考拉征信服务有限公司从上游公司获取接口后又违规将查询接口出卖,并非法缓存公民个人身份信息,供下游公司查询牟利,从而造成公民身份信息包括身份证照片的大量泄露。
违规缓存相当于把公民个人信息复制了一份,存在那边,下游公司再向它通过数据接口调取数据的时候,它就不需要再向上游调取,也是节省了开支,这个是违法的。

经查,2015 年 3 月以来,北京考拉公司非法提供查询返照 9800 余万次,获利 3800 余万元,在公司服务器中查获并收缴被非法获取、存储的公民姓名、身份证号、相片近 1 亿条。
02.我只是个写爬虫的,跟我有什么关系?
许多程序员都有这样的想法,技术是无罪的,我只是个打工的程序员,公司干违法的业务,跟我没关系。。。只能说,程序猿们真是图羊图森破了。
我们先来看几个真实的法院判决案例:
案例一:数据拥有者有证据能够举证你的数据是抓取来的。如下,今日头条对起诉上海晟品法院宣判结果。

(图片文字来自中国判决文书网)
从文书描述来看,修改UA、修改device id、绕开网站访问频率控制这是写爬虫的基本,这些技术手法反而成了获罪的依据。
案例二:抓取用户社交数据,尤其是用户隐私相关。

(图片文字来自新浪网)
案例三:用爬虫技术扰乱对方网站经营规则,且牟利。比如这个:

(图片文字来自中国永嘉公号)
图上描述做搜索引擎排名的技术,其实就是利用爬虫技术规模化的访问网页。
在我们通常的认知里,因为互联网推崇分享精神,所以认为只要是网络公开数据就可以抓取,但是通过上面的案例来看,有几个禁忌,抓取的数据最好不要直接商用,涉及社交信息/用户信息要谨慎。
老板交代你抓取敏感任务时,让老板先看下刑法第285条。公司从事违法业务,不代表个人行为就没事,只是还没入有关部门的法眼。
03.程序员如何避免,面向监狱编程?
爬哪些数据会触犯法律?
第一、著作权法保护的所有作品数据
比如一些网站发表的内容,如文章、评论等都是有著作权的,如果只是单纯的通过浏览器查看是不会触犯法律的。
但是,对于有著作权的作品,如果未经著作权人许可,以盈利为目的,对其作品用任何手段进行复制是犯法的。
如果是使用了爬虫技术手段爬取数据之后将其保存下来或者传播,并且进行盈利,这种都是属于犯罪的。
第二、网站用户的个人信息或者隐私信息
网站上的个人用户的个人信息,即使是用户自己放到一些网站上进行公开或者部分公开,如微博、微信等,不代表这些数据就可以被其他人随便获取,这个要特别注意。
所以,如果爬取的数据涉及到个人信息或隐私信息,都是违法的!
还有些爬虫企图绕过权限校验等,爬取用户未公开的信息,如个人私密相册照片等,都是属于侵犯用户的个人隐私的,不要觉得自己技术玩得溜,这些可都是违法行为。
第三、反不正当竞争法中明确保护的数据
许多网站中的数据系由用户生成,且该等数据和内容系原告网站的主要竞争力来源。如“XX点评”、“X团”上面的店铺评价、评论等信息,“X程网”上面的关于酒店的评价评论等信息等。
那么,未经允许,爬取其他网站的核心数据,很明显并没有遵守《反不正当竞争法》中规定的自愿、平等、公平、诚实信用的原则。
在“XX点评”诉“X度”不正当竞争案件、以及“X浪微博”诉“X脉脉”不正当竞争等案件中,法院都认定被告未经许可抓取、使用原告网站中的数据的行为,违反了诚实信用原则及公认的道德,损害了互联网的市场竞争秩序,损害了原告的竞争优势,从而构成不正当竞争。
因此,如果抓取XX点评、X博、X瓣电影、X乎等UGC模式的网站上用户发布的信息,并在自己的产品或者服务中发布、使用该等信息,则有较大的风险构成不正当竞争。
怎么爬数据算犯法?
如果是爬取公开的数据,通常不会被认为是侵权。Google、百度等搜索引擎都是这么爬取的。
那么,到底怎么爬数据是有可能触犯法律的呢,主要考虑是否涉及以下两种行为:
没有遵守网站Robots协议
Robots协议是技术界为了解决爬取方和被爬取方之间通过计算机程序完成关于爬取的意愿沟通而产生的一种机制。
通过技术手段,绕过防护措施,抓取数据
由于爬虫的批量访问会给网站带来巨大的压力和负担,因此许多网站经营者会采取技术手段,以阻止爬虫批量获取自己网站信息。
所以,很多爬虫工具为了爬取数据,会想办法通过各种手段绕过防护措施,但是,这种行为也是会触犯法律的。
抓回来的数据怎么用会犯法?
很多公司开发的爬虫遵守了Robots协议,也没有爬取不该爬取的数据,难道这样获取到的数据就可以随便使用了吗?其实也不是,如果使用不当,也会触犯法律的。
比如通过爬虫抓取到的数据进行盈利、损害他人利益、造假、诽谤等都是可能触犯法律的。
此外,未经被收集者同意,即使是将合法收集的公民个人信息向他人提供的,也属于刑法第二百五十三条之一规定的“提供公民个人信息”,可能构成犯罪。
04.我们如何防止个人信息被泄露?
在科技飞速发展的今天,人们开始追求各种方便快捷的方式生活,但是,在方便快捷的背后,个人信息安全也不能忽视。浏览器、社交平台等等都有可能出现隐私泄露。
个人隐私泄露有着很严重的安全隐患!如何防止个人信息泄露?快来看防范小妙招:
- 尽量不使用公共场所的 WiFi。
- 尽量访问具备安全协议的网址。建议尽量登录网址前缀中带有“https:”字样的网站,具备这种安全协议的网址的安全性较高。
- 不同软件尽量不要使用同一组账号密码。
- 妥善处置快递单等包含个人信息的单据。对于含有姓名、电话、住址等信息的单据凭证要及时销毁,不经意扔掉也可能导致个人信息泄露。
- 身份证、户口本等有个人信息的证件,一定要保存好。
- 手机、电脑等都需要安装安全软件,每天至少进行一次对木马程序的扫描,尤其在使用重要账号密码前。每周定期进行一次病毒查杀,并及时更新安全软件。
- 不少人热衷于晒地点、晒自拍照,还有家长喜欢晒孩子照片等。这种手机签到可能被别有用心的人盯上。可参考《21岁日本女星惨遭猥亵,只因自拍瞳孔倒影暴露住址?| 一张照片是怎么出卖你的!》
- 一方面暴露了个人隐私,比如姓名、工作单位、家庭住址等,另一方面可能招致犯罪,在网上使用手机签到时,需要谨慎。