弱人工智能的时代已经到来,人们每天的生活都离不开算法所提供的服务。比如:资讯类APP是根据用户偏好做的个性化推荐;出行类APP背后是算法在做最优化调度;购物类APP是根据历史购买行为和商品间相似度进行推荐。这样的例子还有很多很多,就不一一列举了。
可见算法对于一家互联网公司有多么的重要,而市场上优秀的算法工程师却非常稀少,因此各大互联网公司不惜开出高薪来吸引人才,同时算法工程师的职业生命周期还很长,对绝大多数的开发者来说是一个非常理想的职业。
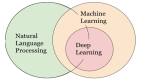
NLP的全称是Natuarl Language Processing,中文意思是自然语言处理,是人工智能领域的一个重要方向。随着机器学习不断的发展,在图像识别、语音识别等方向都取得了巨大的进步。相比较而言NLP却落后了一些,这与NLP所要解决问题的复杂度有关。
人类语言是抽象的信息符号,其中蕴含着丰富的语义信息,人类可以很轻松地理解其中的含义。而计算机只能处理数值化的信息,无法直接理解人类语言,所以需要将人类语言进行数值化转换。不仅如此,人类间的沟通交流是有上下文信息的,这对于计算机也是巨大的挑战。
NLP就是解决上述问题的技术集合,不是某个单一的技术点,而是一整套技术体系,其复杂度可见一斑。因此,NLP算法工程师的薪资待遇要远高于行业的平均水平。
本文希望通过言简意赅的方式,帮助大家建立一个关于NLP的整体知识体系,方便大家快速入门NLP,争取早日成为大牛,走上人生巅峰,:-P。
我们首先来看看NLP的任务类型,如下图所示:
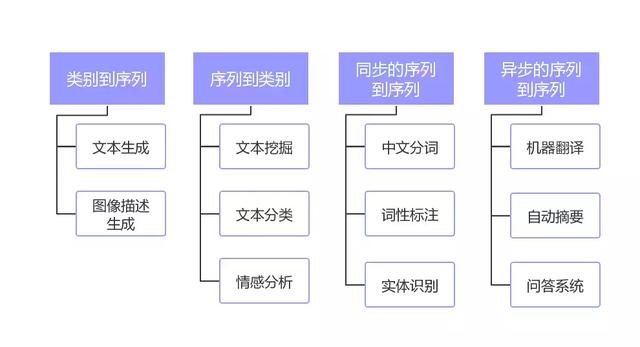
主要划分为了四大类:
- 类别到序列
- 序列到类别
- 同步的序列到序列
- 异步的序列到序列
其中“类别”可以理解为是标签或者分类,而“序列”可以理解为是一段文本或者一个数组。简单概况NLP的任务就是从一种数据类型转换成另一种数据类型的过程,这与绝大多数的机器学习模型相同或者类似,所以掌握了NLP的技术栈就等于掌握了机器学习的技术栈。
NLP的预处理
为了能够完成上述的NLP任务,我们需要一些预处理,是NLP任务的基本流程。预处理包括:收集语料库、文本清洗、分词、去掉停用词(可选)、标准化和特征提取等。
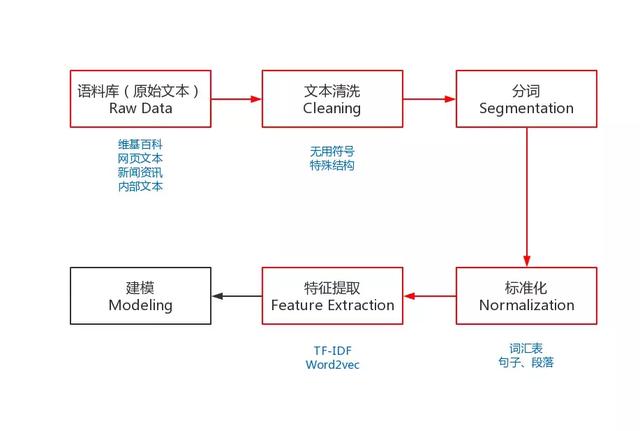
图中红色的部分就是NLP任务的预处理流程,有别于其它机器学习任务的流程,下面我就来分布介绍一下:
语料库
对于NLP任务来说,没有大量高质量的语料,就是巧妇难为无米之炊,是无法工作的。
而获取语料的途径有很多种,最常见的方式就是直接下载开源的语料库,如:维基百科的语料库。
但这样开源的语料库一般都无法满足业务的个性化需要,所以就需要自己动手开发爬虫去抓取特定的内容,这也是一种获取语料库的途径。
当然,每家互联网公司根据自身的业务,也都会有大量的语料数据,如:用户评论、电子书、商品描述等等,都是很好的语料库。
现在,数据对于互联网公司来说就是石油,其中蕴含着巨大的商业价值。所以,小伙伴们在日常工作中一定要养成收集数据的习惯,遇到好的语料库一定要记得备份(当然是在合理合法的条件下),它将会对你解决问题提供巨大的帮助。
文本清洗
我们通过不同的途径获取到了想要的语料库之后,接下来就需要对其进行清洗。因为很多的语料数据是无法直接使用的,其中包含了大量的无用符号、特殊的文本结构。
数据类型分为:
结构化数据:关系型数据、json等 半结构化数据:XML、HTML等 非结构化数据:Word、PDF、文本、日志等
需要将原始的语料数据转化成易于处理的格式,一般在处理HTML、XML时,会使用Python的lxml库,功能非常丰富且易于使用。对一些日志或者纯文本的数据,我们可以使用正则表达式进行处理。
正则表达式是使用单个字符串来描述、匹配一系列符合某个句法规则的字符串。Python的示例代码如下:
- import re
- # 定义中文字符的正则表达式
- re_han_default = re.compile("([\\u4E00-\\u9FD5]+)", re.U)
- sentence = "我/爱/自/然/语/言/处/理"
- # 根据正则表达式进行切分
- blocks= re_han_default.split(sentence)
- for blk in blocks:
- # 校验单个字符是否符合正则表达式
- if blk and re_han_default.match(blk):
- print(blk)
输出:
我爱自然语言处理复制代码
除了上述的内容之外,我们还需要注意中文的编码问题,在windows平台下中文的默认编码是GBK(gb2312),而在linux平台下中文的默认编码是UTF-8。在执行NLP任务之前,我们需要统一不同来源语料的编码,避免各种莫名其妙的问题。
如果大家事前无法判断语料的编码,那么我推荐大家可以使用Python的chardet库来检测编码,简单易用。既支持命令行:chardetect somefile,也支持代码开发。
分词
中文分词和英文分词有很大的不同,英文是使用空格作为分隔符,所以英文分词基本没有什么难度。而中文是字与字直接连接,中间没有任何的分隔符,但中文是以“词”作为基本的语义单位,很多NLP任务的输入和输出都是“词”,所以中文分词的难度要远大于英文分词。
中文分词是一个比较大的课题,相关的知识点和技术栈非常丰富,可以说搞懂了中文分词就等于搞懂了大半个NLP。中文分词经历了20多年的发展,克服了重重困难,取得了巨大的进步,大体可以划分成两个阶段,如下图所示:
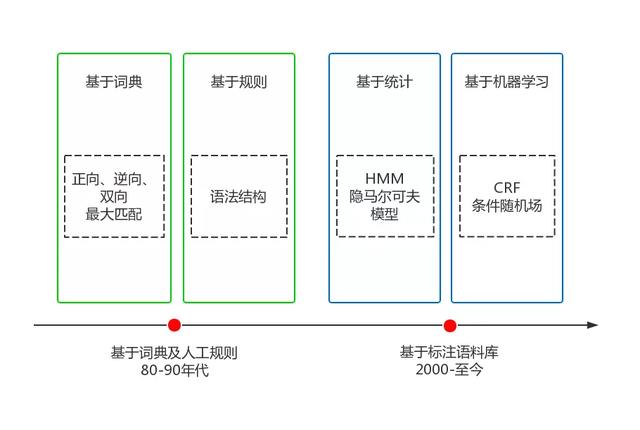
目前,主流的中文分词技术采用的都是基于词典最大概率路径+未登录词识别(HMM)的方案,其中典型的代表就是jieba分词,一个热门的多语言中文分词包。
如果对中文分词感兴趣的朋友,想进一步详细了解,我推荐你看一看我写的一本掘金小册《深入理解NLP的中文分词:从原理到实践》,里面详细地讲解了中文分词的各种实现方法,并深度分析了jiebe的Python源码,让你可以从零开始彻底掌握中文分词的技术,同时也讲解了多种NLP的实际案例,相信你一定会收获很多。
标准化
标准化是为了给后续的处理提供一些必要的基础数据,包括:去掉停用词、词汇表、训练数据等等。
当我们完成了分词之后,可以去掉停用词,如:“其中”、“况且”、“什么”等等,但这一步不是必须的,要根据实际业务进行选择,像关键词挖掘就需要去掉停用词,而像训练词向量就不需要。
词汇表是为语料库建立一个所有不重复词的列表,每个词对应一个索引值,并索引值不可以改变。词汇表的最大作用就是可以将词转化成一个向量,即One-Hot编码。
假设我们有这样一个词汇表:
我爱自然语言处理复制代码
那么,我们就可以得到如下的One-Hot编码:
- 我: [1, 0, 0, 0, 0]
- 爱: [0, 1, 0, 0, 0]
- 自然:[0, 0, 1, 0, 0]
- 语言:[0, 0, 0, 1, 0]
- 处理:[0, 0, 0, 0, 1]
这样我们就可以简单的将词转化成了计算机可以直接处理的数值化数据了。虽然One-Hot编码可以较好的完成部分NLP任务,但它的问题还是不少的。
当词汇表的维度特别大的时候,就会导致经过One-Hot编码后的词向量非常稀疏,同时One-Hot编码也缺少词的语义信息。由于这些问题,才有了后面大名鼎鼎的Word2vec,以及Word2vec的升级版BERT。
除了词汇表之外,我们在训练模型时,还需要提供训练数据。模型的学习可以大体分为两类:
- 监督学习,在已知答案的标注数据集上,模型给出的预测结果尽可能接近真实答案,适合预测任务
- 非监督学习,学习没有标注的数据,是要揭示关于数据隐藏结构的一些规律,适合描述任务
根据不同的学习任务,我们需要提供不同的标准化数据。一般情况下,标注数据的获取成本非常昂贵,非监督学习虽然不需要花费这样的成本,但在实际问题的解决上,主流的方式还选择监督学习,因为效果更好。
带标注的训练数据大概如下所示(情感分析的训练数据):
- 距离 川沙 公路 较近 公交 指示 蔡陆线 麻烦 建议 路线 房间 较为简单 __label__1
- 商务 大床 房 房间 很大 床有 2M 宽 整体 感觉 经济 实惠 不错 ! __label__1
- 半夜 没 暖气 住 ! __label__0
其中每一行就是一条训练样本,__label__0和__label__1是分类信息,其余的部分就是分词后的文本数据。
特征提取
为了能够更好的训练模型,我们需要将文本的原始特征转化成具体特征,转化的方式主要有两种:统计和Embedding。
原始特征:需要人类或者机器进行转化,如:文本、图像。
具体特征:已经被人类进行整理和分析,可以直接使用,如:物体的重要、大小。
统计
统计的方式主要是计算词的词频(TF)和逆向文件频率(IDF):
- 词频,是指某一个给定的词在该文件中出现的频率,需要进行归一化,避免偏向长文本
- 逆向文件频率,是一个词普遍重要性的度量,由总文件数目除以包含该词的文件那么,每个词都会得到一个TF-IDF值,用来衡量它的重要程度,计算公式如下:
- Embedding
Embedding是将词嵌入到一个由神经网络的隐藏层权重构成的空间中,让语义相近的词在这个空间中距离也是相近的。Word2vec就是这个领域具有表达性的方法,大体的网络结构如下:
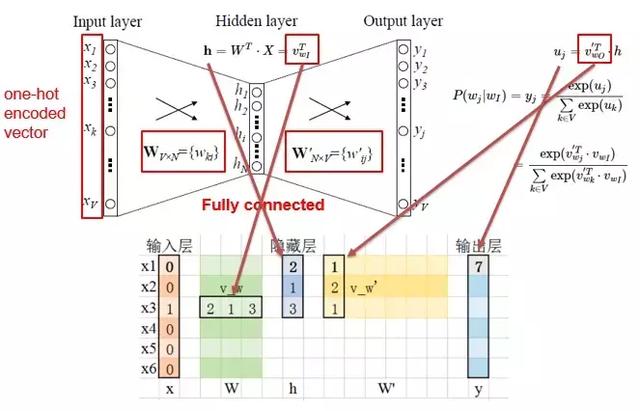
输入层是经过One-Hot编码的词,隐藏层是我们想要得到的Embedding维度,而输出层是我们基于语料的预测结果。不断迭代这个网络,使得预测结果与真实结果越来越接近,直到收敛,我们就得到了词的Embedding编码,一个稠密的且包含语义信息的词向量,可以作为后续模型的输入。
综上所述,我们就将NLP预处理的部分讲解清楚了,已经涵盖了大部分的NLP内容,接下来我们来聊聊NLP的一些具体业务场景。
- NLP的业务场景
NLP的业务场景非常丰富,我简单的梳理了一下:
- 文本纠错:识别文本中的错别字,给出提示以及正确的建议
- 情感倾向分析:对包含主观信息的文本进行情感倾向性判断
- 评论观点抽取:分析评论关注点和观点,输出标签
- 对话情绪识别:识别会话者所表现出的情绪类别及置信度
- 文本标签:输出能够反映文章关键信息的多维度标签
- 文章分类:输出文章的主题分类及对应的置信度
- 新闻摘要:抽取关键信息并生成指定长度的新闻摘要
大家不要被这些眼花缭乱的业务场景给搞晕了,其实上面的这些业务都是基于我们之前讲的NLP预处理的输出,只是应用了不同的机器学习模型,比如:SVM、LSTM、LDA等等。
这些机器学习模型大部分是分类模型(序列标注也是一种分类模型),只有少部分是聚类模型。这些模型就是泛化的了,并不只是针对于NLP任务的。要想讲清楚这部分内容,就需要另开一个关于“机器学习入门”的主题,这里就不过多的展开了。
小结:只要大家掌握了NLP的预处理,就算入门NLP了,因为后续的处理都是一些常见的机器学习模型和方法。