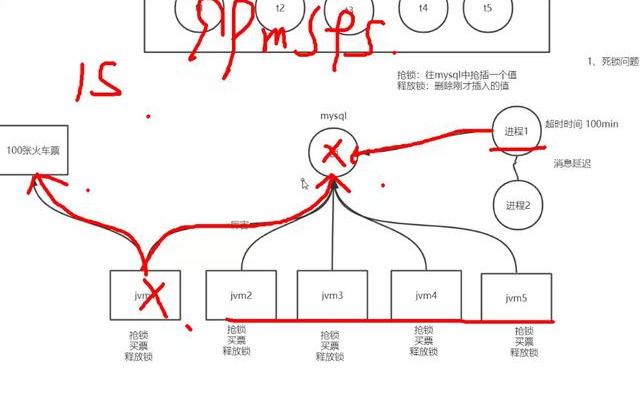
在分布式系统中,分布式锁是为了解决多实例之间的同步问题。例如master选举,能够获取分布式锁的就是master,获取失败的就是slave。又或者能够获取锁的实例能够完成特定的操作。
目前比较常用的分布式锁实现有两种,基于zookeeper实现和基于redis实现。zookeeper和redis也是生产环境中经常用到的第三方组件。下面我会分析它们的实现原理。
分布式锁实现要求
实现一个分布式锁至少要满足下面三点要求:
- 互斥,在任何时候同一个锁只能由一个客户端持有。
- 不会死锁,就算持有的客户端异常崩溃也不会影响后续客户端加锁。
- 谁加锁谁解锁,加锁和解锁都必须是同一个客户端。
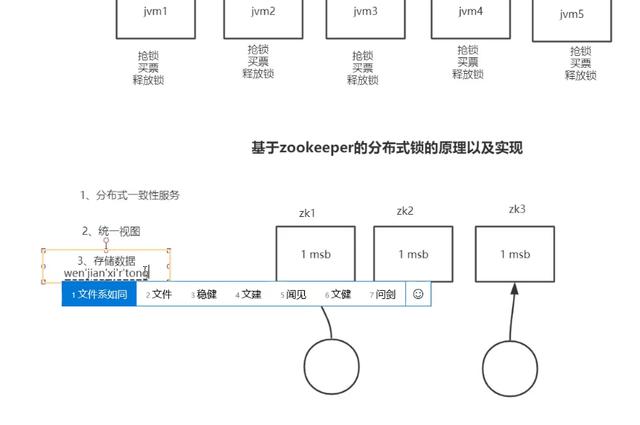
zookeeper分布式锁
在讲解zookeeper的分布式锁之前有两个概念需要明确:
- 临时节点:生命周期和链接周期一致。例如客户端链接A创建了临时节点NodeA,如果链接A关闭或者网络异常断开,那么NodeA也会跟着消失。
- 顺序节点:节点名称按照顺序从小到大创建,例如先创建了000000001,那么接着创建的节点就会分配000000002。
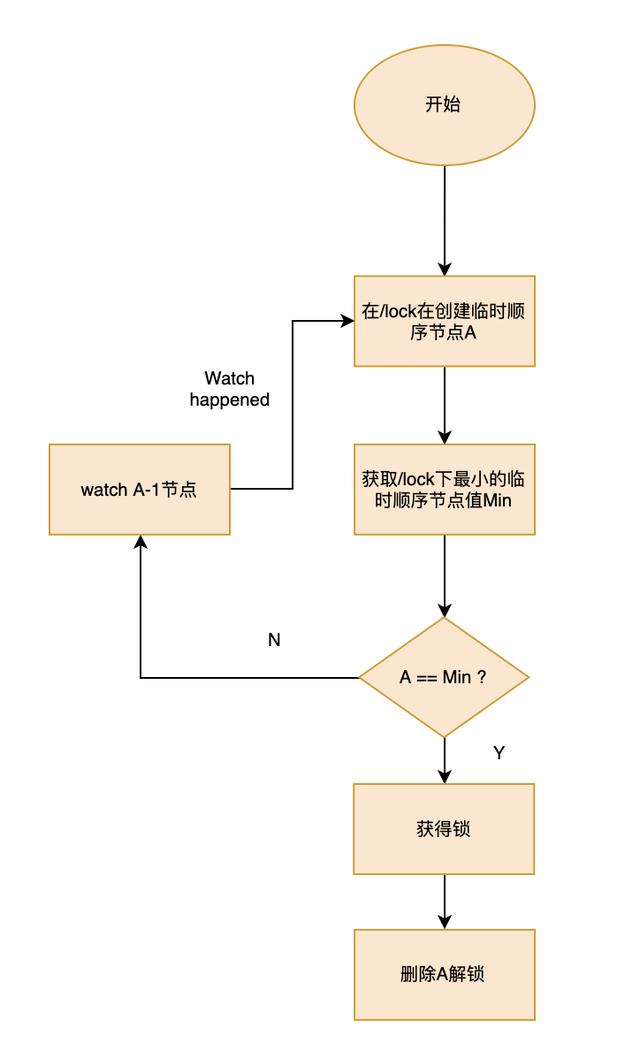
zookeeper的分布式锁实现原理就是利用临时顺序节点,大概流程为:
- 每个客户端对某个功能加锁时,在zookeeper指定目录下生成一个唯一的临时顺序节点。
- 所有临时节点中序号最小的节点即为当前锁的持有者。
- 释放锁时将自己持有的临时节点删除即可。
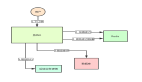
例如,对于加锁过程,所有的客户端都在/lock目录下面创建临时节点,如果发现自己创建的临时节点是/lock目录中最小的节点,那么就获取锁成功,否则就watch比自己小的节点中的最大节点。
监控比自己小的节点中的最大节点是为了避免“惊群”效应,避免一个锁释放把所有等待的客户端唤醒,但是只有一个客户端能获取锁。
对于释放锁,只需要把自己创建的临时顺序节点删除即可。整个过程流程图如下:
优点:锁安全性高,zookeeper数据不易丢失。用户使用简单。
缺点:性能消耗比较高。因为需要动态产生和删除临时节点,当集群负载比较高时临时节点消失会有时间差(一般在一分钟范围内)。
redis分布式锁
redis的分布式锁实现比zookeeper分布式锁实现复杂,也分为redis单实例和多实例(master-master)实现方式。
需要特别指出的是redis如果是master-slave这种结构部署时,获取和释放锁都只能向master请求,和单实例的实现原理基本一样,否则主从切换时会出现多人拿到同一把锁的情况。
例如:
客户端A在master拿到了锁。
master节点在把A创建的key写入slave之前宕机了。(主从同步是异步操作)
slave变成了master节点。
B也得到了和A还持有的相同的锁,因为slave还没有A持有锁的信息。
redis单实例实现方案
通过下面命令获得锁:
SET resource_name my_random_value NX PX 30000
这个命令的作用是只有这个key不存在时才会设置这个key的值(NX的作用,即not exist),超时时间设置为30000毫秒(PX的作用),这个key的值设置为my_random_value。这个值必须在所有获取锁请求的客户端里面保持唯一。
key值的超时时间,也叫做“锁有效时间”。这是锁的自动释放时间。
这套实现方案在非分布式的、单点的、保证永不宕机的环境是适用的。
redis集群实现方案(Redlock算法)
在分布式版本的算法里我们假设有N个redis master节点,这些节点完全独立,不用任何的复制或者分布式协调算法来同步数据。
这里假设N=5,一个客户端获取锁的过程如下:
- 获取当前以毫秒为单位的时间。
- 轮询用相同的key在N个节点上面请求锁。(每个请求的超时时间设置的短一些,为了一个master节点不用时,快速请求下一个master)。
- 如果在超过一半master节点上面成功获取锁(这里是3个),客户端计算第二步请求锁花费的时间,如果小于锁释放时间,则认为获取锁成功。
- 如果锁获取成功了,那么现在 锁自动释放时间=最初锁释放时间-请求锁花费的时间
- 如果获取锁失败了(成功的锁不超过master数量的一般 或者 请求耗时>锁释放时间),那么客户端都会在每个master节点上面释放锁。
获取锁成功的节点数需要超过master节点数量的一半才认为是获取锁成功的思路应该是借鉴了zookeeper的paxos算法。
还有一个需要指出的点是,当一个客户端获取失败时应该随时延时后再进行重试,避免多个客户端同时重试又同时失败。
优点:性能高
缺点:单实例会有单点问题,多实例主从切换会导致数据丢失,master-master集群模式实现复杂。
看大佬给你讲解基于Zookeeper、Redis的分布式锁