今年10月30日
DeepMind在《自然》杂志上
发表的一篇论文
仿佛又一次把人们的视线
拉回了两年前的那场
“世纪大战”之中
不过,这回的主角不是
“阿尔法狗”(AlphaGo)
而是AlphaStar
这位《星际争霸2》玩家
在欧洲服务器击败了
99.8%人类选手
有同学听后不以为然
“也没有扫遍天下无敌手嘛。”
然而事实是
一局典型《星际争霸》游戏的
搜索空间大约是一盘典型
围棋棋局的101799640倍
而要击败剩下的0.02%人类选手
也只是个时间问题
从深蓝到AlphaGo
再到AlphaStar
过去10年,人工智能在机器视觉、
深度学习、自然语言处理
等领域取得了重大突破
而在这条道路上
计算力是重要的推动力
OpenAI在2018年一份研究报告显示:2012年起,AI消耗的计算力平均每3.43个月增长一倍,过去6年时间内已经增长30万倍。GPU计算是当下AI深度学习训练和推理计算的首选架构,FPGA与ASIC亦在积蓄力量。
戴尔科技集团持续投入到AI计算解决方案研究,并将我们的研究成果、效能测试、技术白皮书,分享给用户及TensorFlow、Caffe、MXNet等主流开源框架社区。戴尔易安信在DSS8440、C4140、R740、R740xd、R940xa、R840、R7425、T640、XR2等多款服务器上,提供超过50种AI GPU加速配置方案支持,总有一款可以满足您的需求。
全方位的AI GPU加速配置方案
总有一款可以满足您
DSS8440
DSS8440是戴尔易安信设计的一款动态机器学习加速平台,4U机箱可以支持最多10张Nvidia当前性能最高的V100加速卡或者8张戴尔投资AI芯片企业GraphcoreIPU ASIC加速卡,适合于各种AI计算环境下深度学习模型训练。DSS8440提供更强的环境适应能力,支持在35℃环境下205W CPU以及GPU加速器。

C4140是戴尔易安信为AI计算精心打造的另外一款智能计算神器。C4140机箱只有1U,却可以在有限的空间内支持4张最高性能的双宽GPU加速卡、本地NVMe SSD硬盘以及100Gb低延迟网卡,为用户提供极佳的数据中心空间GPU计算密度。

R940xa
当前很多复杂的AI应用场景,往往使用多种算法的集成学习,以达到更好的模型精度,解决小数据样本下的机器学习,比如工业产品外观缺陷检测。而不同算法可能会选择不同的计算介质,比如深度学习选择GPU,经典机器学习使用CPU。此时,戴尔易安信R940xa四路计算加速服务器,可以提供CPU与GPU 1:1的计算配比,帮助用户应对复杂集成学习环境下模型训练加速。

R740
同时,随着AI产业化不断深入,推理计算需求增速明显。戴尔易安信R740服务器也在AI推理计算场景中广泛采用,2U机箱可以支持8张T4或P4 GPU。R740提供多矢量散热技术,可针对不同GPU卡运行工作负载智能调节风扇转速。

此外,随着AI计算朝向边缘端进展,很多场景下如工业生产线、移动通信基站、变电站等,对散热、防尘等环境参数要求更加苛刻。而戴尔易安信XR2服务器搭载NvidiaT4,采用工业加固型服务器设计,提供脏乱、多尘环境下的过滤挡板,机箱深度仅为20英寸,复合严格的海事和军用标准,可以适应复杂严苛环境下AI边缘计算需求。

戴尔易安信联合驱动科技
为用户构建数据中心级AI资源池
IT软件及硬件,一文一武,相得益彰。好的硬件设施,也需要好的资源管理与调度软件,以实现AI计算资源的按需分配和随需扩展。戴尔易安信联合AI计算平台合作伙伴趋动科技,基于猎户座AI软件实现GPU虚拟化,为用户构建数据中心级AI资源池,应用无需修改即可透明共享和使用数据中心内任何服务器上的AI加速器。
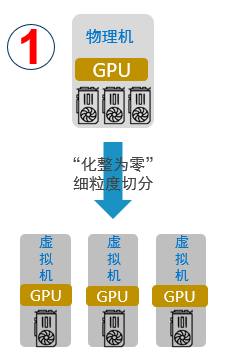
“化整为零”
支持将一块物理GPU细粒度分割为多块虚拟GPU,分配给多个虚拟机或容器同时使用,实现GPU资源的高效共享,提高AI计算资源利用率。有别于传统GPU虚拟化只切割显存,CUDA核心只能时分复用方式,猎户座AI计算平台可以实现虚拟GPU显存和算力的独立配置和限制。显存和算力,既支持显存和CUDA计算核心的等比例分配,也支持非等比例分配,从而提高资源利用率,降低成本。
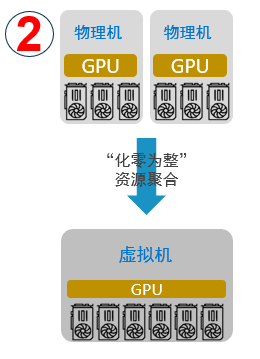
“化零为整”
支持将单台以及多台服务器的GPU资源提供给一个虚拟机或容器使用,AI应用无需修改代码。用户可以将多台物理服务器计算资源聚合后提供给单一应用使用,为用户的AI应用提供数据中心级超级算力,同时对应用透明。
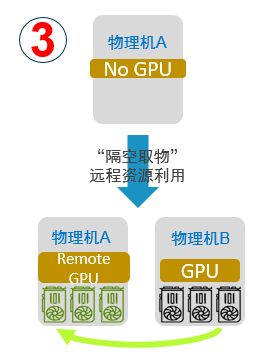
“隔空取物”
支持将虚拟机或容器运行在一台没有物理GPU的服务器上,透明地使用另外一台服务器上的GPU资源,而无需修改AI应用代码。借助这项功能,用户可以构建数据中心级GPU资源池,应用可以无障碍地部署到数据中心内的任意服务器,并能够透明地使用任意服务器之上的GPU资源。
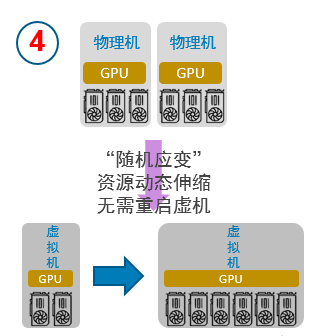
“随需应变”
支持用户在虚拟机或者容器的生命周期内,动态分配和释放GPU计算资源,实现真正的GPU资源动态伸缩,极大提升了GPU资源调度的灵活度。
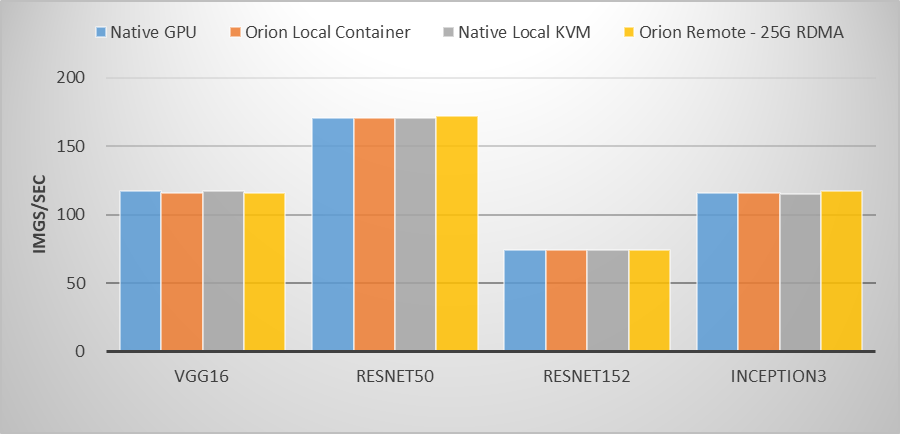
猎户座AI计算平台,可以在极少性能损耗下,实现GPU计算资源虚拟化,按需分配,灵活扩展和应用透明。
在之前进行的一项基于Nvidia Tesla P40的测试中,用例运行在物理GPU、虚拟GPU容器环境、虚拟GPUKVM虚拟机环境,以及通过25Gb ROCE网卡使用远程虚拟GPU资源,运行VGG16、ResNet50、ResNet152、Inception3主流图像分类模型训练,虚拟GPU与物理GPU性能差距几乎可以忽略不计。
通过适用于不同场景、不同AI应用负载的AI加速服务器硬件,以及提供创新AI虚拟化技术的猎户座软件平台,我们为数据科学家提供一套高效经济的AI计算平台。未来的AI计算平台,将如同我们儿时手中的魔方,随着数据科学家的需要,快速变换出应用所需的AI计算资源,为拓展人工智能边界提供有利的计算利器。