作为Linux运维,多多少少会碰见这样那样的问题或故障,从中总结经验,查找问题,汇总并分析故障的原因,这是一个Linux运维工程师良好的习惯。每一次技术的突破,都经历着苦闷,伴随着快乐,可我们还是执着的继续努力,从中也积累了更多的经验,这就是实践给予我们的丰厚回报。
下面汇总了我做项目过程可能出现的故障及解决方法,看看是否与你有共鸣,并对你有帮助?
第一:常见问题解决集锦
1.shell脚本不执行
问题:
某天研发某同事找我说帮他看看他写的shell脚本,死活不执行,报错。我看了下,脚本很简单,也没有常规性的错误,报“:badinterpreter:Nosuchfileordirectory”错。
看这错,我就问他是不是在windows下编写的脚本,然后在上传到linux服务器的……果然。
原因:
在DOS/windows里,文本文件的换行符为rn,而在nix系统里则为n,所以DOS/Windows里编辑过的文本文件到了nix里,每一行都多了个^M。
解决:
1)重新在linux下编写脚本;
2)vi:%s/r//g:%s/^M//g(^M输入用Ctrl+v,Ctrl+m)
附:sh-x脚本文件名,可以单步执行并回显结果,有助于排查复杂脚本问题。
2.crontab输出结果控制
问题:
/var/spool/clientmqueue目录占用空间超过100G
原因:
cron中执行的程序有输出内容,输出内容会以邮件形式发给cron的用户,而sendmail没有启动所以就产生了/var/spool/clientmqueue目录下的那些文件,日积月累可能撑破磁盘。
解决:
1)直接手动删除:ls|xargsrm-f;
2)彻底解决:在cron的自动执行语句后加上>/dev/2>&1
3.telnet很慢/ssh很慢
问题:
某天研发某同事说10.50访问10.52memcached服务异常,让我们检查下看网络/服务/系统是否有异常。检查发现系统正常,服务正常,10.50ping10.52也正常,但10.50telnet10.52很慢。同时发现该机器的namesever是不起作用的。
原因:
becauseyourPCdoesn’tdoareverseDNSlookuponyourIPthen…whenyoutelnet/ftpintoyourlinuxbox,it’lldoadnslookuponyou。
解决:
1)修改/etc/hosts使hostname和ip对应;
2)在/etc/resolv.conf注释掉nameserver或者找一个“活的”nameserver。
4.Read-onlyfilesystem
问题:
同事在mysql里建表建不成功,提示如下:
mysql>createtablewosontest(colddname1char(1));
ERROR1005(HY000):Can’t create table‘wosontest’(errno:30)
经检查mysql用户权限以及相关目录权限没问题;用perror30提示信息为:OSerrorcode30:Read-onlyfilesystem
可能原因:
1)文件系统损坏;
2)磁盘又坏道;
3)fstab文件配置错误,如分区格式错误错误(将ntfs写成了fat)、配置指令拼写错误等。
解决:
1)由于是测试机,重启机器后恢复;
2)网上说用mount可解决。
5.文件删了磁盘空间没释放
问题:
某天发现某台机器df-h已用磁盘空间为90G,而du-sh/*显示所有使用空间加起来才30G,囧。
原因:
可能某人直接用rm删除某个正在写的文件,导致文件删了但磁盘空间没释放的问题
解决:
1)最简单重启系统或者重启相关服务。
2)干掉进程
/usr/sbin/lsof|grepdeleted ora25575data33uREG65,654294983680/oradata/DATAPRE/UNDOTBS009.dbf(deleted)
从lsof的输出中,我们可以发现pid为25575的进程持有着以文件描述号(fd)为33打开的文件/oradata/DATAPRE/UNDOTBS009.dbf。
在我们找到了这个文件之后可以通过结束进程的方式来释放被占用的空间:echo>/proc/25575/fd/33
3)删除正在写的文件一般用cat/dev/null>file
6.find文件提升性能
问题:
在tmp目录下有大量包含picture_*的临时文件,每天晚上2:30对一天前的文件进行清理。之前在crontab下跑如下脚本,但是发现脚本效率很低,每次执行时负载猛涨,影响到其他服务。
#!/bin/sh find/tmp-name“picture_*”-mtime+1-execrm-f{};
原因:
目录下有大量文件,用find很耗资源。
解决:
#!/bin/sh cd/tmp time=`date-d“2dayago”“+%b%d”` ls-l|grep“picture”|grep“$time”|awk‘{print$NF}’|xargsrm-rf
7.获取不了网关mac地址
问题:
从2.14到3.65(映射地址2.141)网络不通,但是从3端的其他机器到3.65网络OK。
原因:
#arp AddressHWtypeHWaddressFlagsMaskIface 192.168.3.254etherincompletCMbond0 表面现象是机器自动获取不了网关MAC地址,网络工程师说是网络设备的问题,具体不清。
解决:
arp绑定,arp-ibond0-s192.168.3.25400:00:5e:00:01:64
8.http服务无法启动一例
问题:
某天研发某同事说网站前端环境http无法启动,我上去看了下。报如下错:
/etc/init.d/httpdstart Startinghttpd:[SatJan2917:49:002011][warn]moduleantibot_moduleisalreadyloaded,skipping Useproxyforwardasremoteip:true. Antibotexcludepattern:.*.[(js|css|jpg|gif|png)] Antibotseedcheckpattern:login (98)Addressalreadyinuse:make_sock:couldnotbindtoaddress[::]:7080 (98)Addressalreadyinuse:make_sock:couldnotbindtoaddress0.0.0.0:7080 nolisteningsocketsavailable,shuttingdown Unabletoopenlog[FAILED]
原因:
1)端口被占用:表面看是7080端口被占用,于是netstat-npl|grep7080看了下发现7080没有占用;
2)在配置文件中重复写了端口,如果在以下两个文件同时写了Listen7080
/etc/httpd/conf/http.conf /etc/httpd/conf.d/t.10086.cn.conf
解决:
注释掉/etc/httpd/conf.d/t.10086.cn.conf的Listen7080,重启,OK。
9.toomanyopenfile
问题:
报toomanyopenfile错误
解决:
终极解决方案
echo“”>>/etc/security/limits.conf echo“*softnproc65535″>>/etc/security/limits.conf echo“*hardnproc65535″>>/etc/security/limits.conf echo“*softnofile65535″>>/etc/security/limits.conf echo“*hardnofile65535″>>/etc/security/limits.conf echo“”>>/root/.bash_profile echo“ulimit-n65535″>>/root/.bash_profile echo“ulimit-u65535″>>/root/.bash_profile
最后重启机器或者执行:
ulimit-u655345&&ulimit-n65535
10.ibdata1和mysql-bin致磁盘空间问题
问题:
2.51磁盘空间报警,经查发现ibdata1和mysql-bin日志占用空间太多(其中ibdata1超过120G,mysql-bin超过80G)
原因:
bdata1是存储格式,在INNODB类型数据状态下,ibdata1用来存储文件的数据和索引,而库名的文件夹里的那些表文件只是结构而已。
innodb存储引擎有两种表空间的管理方式,分别是:
1)共享表空间(可拆分为多个小的表空间文件),这个是我们目前多数数据库使用的方法;
2)独立表空间,每一个表有一个独立的表空间(磁盘文件)
对于两种管理方式,各有优劣,具体如下:
①共享表空间:
优点:
可以将表空间分成多个文件存放到不同的磁盘上(表空间文件大小不受表大小的限制,一个表可以分布在不同步的文件上)
缺点:
所有数据和索引存放在一个文件中,则随着数据的增加,将会有一个很大的文件,虽然可以把一个大文件分成多个小文件,但是多个表及索引在表空间中混合存储,这样如果对于一个表做了大量删除操作后表空间中将有大量空隙。
对于共享表空间管理的方式下,一旦表空间被分配,就不能再回缩了。当出现临时建索引或是创建一个临时表的操作表空间扩大后,就是删除相关的表也没办法回缩那部分空间了。
②独立表空间:
在配置文件(my.cnf)中设置:innodb_file_per_table
特点:
每个表都有自已独立的表空间;每个表的数据和索引都会存在自已的表空间中。
优点:
表空间对应的磁盘空间可以被收回(Droptable操作自动回收表空间,如果对于删除大量数据后的表可以通过:altertabletbl_nameengine=innodb;回缩不用的空间。
缺点:
如果单表增加过大,如超过100G,性能也会受到影响。在这种情况下,如果使用共享表空间可以把文件分开,但有同样有一个问题,如果访问的范围过大同样会访问多个文件,一样会比较慢。
如果使用独立表空间,可以考虑使用分区表的方法,在一定程度上缓解问题。此外,当启用独立表空间模式时,需要合理调整innodb_open_files参数的设置。
解决:
1)ibdata1数据太大:只能通过dump,导出建库的sql语句,再重建的方法。
2)mysql-binLog太大:
①手动删除:
删除某个日志:mysql>PURGEMASTERLOGSTO‘mysql-bin.010′;
删除某天前的日志:mysql>PURGEMASTERLOGSBEFORE’2010-12-2213:00:00′;
②在/etc/my.cnf里设置只保存N天的bin-log日志
expire_logs_days=30//BinaryLog自动删除的天数
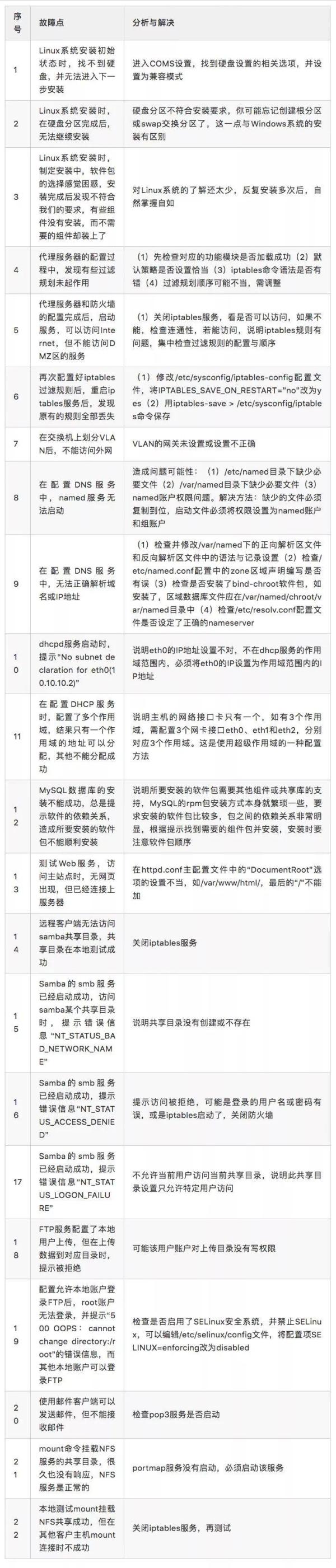
二、故障排查汇总表