












今天早上看到同事的一个优化需求,优化的时间其实不多,但是对于这条SQL的优化思考了很多,希望有一些参考。
业务同学提供的SQL如下:
- SELECT
- b.order_id
- FROM
- (
- SELECT
- a.order_id,
- a.order_time AS create_time
- FROM
- trade_order a
- WHERE
- a.user_id = 12345678
- 。。。。。。
- AND a.deleted = 0
- UNION
- SELECT
- v.order_id,
- v.create_time
- FROM
- virtual_order v
- WHERE
- v.user_id = 12345678
- 。。。。
- ORDER BY
- order_id DESC
- ) AS b
- LIMIT 0,
- 10;
根据反馈,这条SQL的执行时长在200毫秒,在压测情况下会到500毫秒左右,从业务层面来看,目前是不满足需求的,想看看我们有没有优化的建议。
第一印象这条SQL执行时长200~500毫秒,要优化好像可打的牌不多啊,如果要想得到一个可接受的基准值,当然反馈会是越快越好。所以从这个角度来看,我们不妨按照毫秒级优化的标准来看,这条SQL需要做哪些补充的工作。
首先通过SQL看下逻辑情况,整体的逻辑是按照用户id去查询两个数据源(trade_order和virtual_order),从两个数据源查询出10条单号数据返回。这个用户在两个数据源中可能有单号,也可能没有,只要有匹配的就返回,累计返回10条,看起来是为了去重才选择了union的组合方式。
先不看表结构信息,我大体有了如下的建议:
- union的模式更建议采用union all,两个数据源存在数据重合应该是不合理的。
- 查询语句里面使用了order_time但是数据返回压根没有用到,建议去掉
- SQL层面承载了太多的数据处理压力,比如多数据源,去重和过滤,分页,是不是可以做下精简。
当然到了这里,和业务的需求就产生了脱节,这就属于那种看啥都不顺眼的状态,总想找出点问题来,而且对于业务同学来说,哪怕十个八个需求,你得有一个需求的收益更高,他们采用其他需求的可能性才越大,否则就是不作为了。
所以到了这里,我们开始做下分析,要优化SQL不看看执行计划是不过关的,在执行前,我的大体感觉表数据量很大,应该是生成了派生表,然后在数据去重过滤层面的消耗比较大,而两个子查询来说,返回的结果集应该很少。 预测的执行情况是:
1)子查询trade_order应该很快,毫米级响应
2)子查询virtual_order应该也很快,但是最后有一个order by操作,可能代价略高
3)union的去重过滤代价相对较大,涉及到两个结果集的合并,如果返回结果较多,可能是瓶颈
从执行结果来看,让我有些意外,其中virtual_order的返回结果竟然有40多万行,相当于直接走了全表扫描。

而其他的部分也会收到相关影响,所以后续的处理都会受到影响。
为了快速定位问题,我把两个子查询拆开单独执行,查看执行计划,这是分析瓶颈最快的一种处理思路。
- >>explain SELECT
- -> v.order_id,
- -> v.create_time
- -> FROM
- -> virtual_order v
- -> WHERE
- -> v.user_id = 12345678
- 。。。;
执行计划如下:

可以看到是直接走了全表扫描,这是一个基础需求,不会业务同学漏了索引吧,然后查看表结构:
- CREATE TABLE `virtual_order` (
- `order_id` varchar(255) NOT NULL COMMENT '订单ID',
- 。。。
- `user_id` varchar(255) DEFAULT NULL COMMENT '用户ID',
- 。。。
- `refund` tinyint(3) DEFAULT NULL COMMENT ' 是否退款(1:无,2:是)',
- `atc_pay_status` int(3) NOT NULL DEFAULT '0' COMMENT '支付状态',
- 。。。
- PRIMARY KEY (`order_id`),
- KEY `order_status` (`order_status`),
- KEY `user_id` (`user_id`),
- KEY `prepaid_account` (`prepaid_account`)
- ) ENGINE=InnoDB DEFAULT CHARSET=utf8;
发现user_id是走了索引的,那么问题来了,user_id既然是索引,但是为什么SQL语句中依然走了全表扫描呢?
此处思考10秒钟,继续往下看。
其实这个时候问题的边界都很清晰了,SQL语句很简单,索引也存在,走了全表扫描,在MySQL中可以暂时排除直方图的影响,目前在5.7版本中还不存在直方图的特性,那么结果只有一个:字段的类型产生了隐式类型转换。
这个部分可以参考这篇的一篇文章
MySQL中需要重视的隐式转换
比如初始化语句如下:
- create table test(id int primary key,name varchar(20) ,key idx_name(name));
- insert into test values(1,'10'),(2,'20');
然后我们使用如下的两条语句进行执行计划的对比测试。
- explain select * from test where name=20;
- explain select * from test where name=’20’;
在name列为字符类型时,得到的执行计划列表如下:
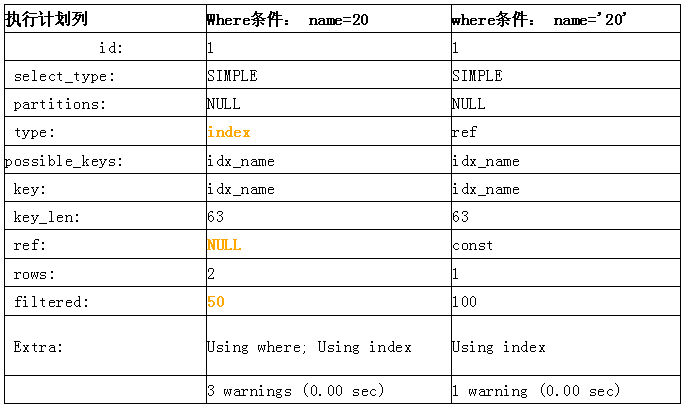
可以很明显的看到,在name为字符串类型时,如果where条件为name=20,则执行全索引扫描,查看warning信息会明确提示:
Message: Cannot use range access on index 'idx_name' due to type or collation conversion on field 'name'
所以此处的问题也显而易见了。
修改了子查询的条件为字符后,整个SQL的执行效率就立马好多了。
使用sql_no_cache的方式测试。
SQL修改前性能:
- +-----------------------+
- 2 rows in set (0.27 sec)
- 修改后性能:
- +-----------------------+
- 2 rows in set (0.00 sec)
然后再次查看执行计划,就都规规矩矩了,这样我们就解决了瓶颈问题,而那些规范,更好的改进就可以逐步展开了,而从建议的角度来看,采用的概率也会高一些。

当然在这个基础上确实有一些补充的建议,在定位瓶颈之后也可以摊开来说了。
优化不是一锤子买卖,在这个基础上,也发现了一些其他的问题,可以看下这个表的表结构信息,其实能够发现一些设计上的小问题。
1) 表字段的字符型基本都是varchar(255),需要尽可能避免这种使用习惯,对于存储性能的开销会有显著影响
2)使用的int类型 int(3),这种使用对于int还是存储4个字节,但是有限范围大大减少,可以考虑更小的数值类型
3)表的索引比较松散,可以根据业务模型创建复合索引,比如user_id和status的结合场景更多,应该创建的是(user_id,status)的复合索引















