一、文娱产业趋势及技术挑战

文娱内容不像商品有完整的量化指标体系,它是一个复杂的实体,它跟意识形态以及用户体验强相关,对内容进行量化评估和衡量是非常困难的。
比如,选角儿。我们不能通过单一指标去衡量一个演员,我们需要综合考量演员的演技、气质、颜值、潜力等与否与某一个角色匹配,并且能生成数据指标,以实现纵横向的对比。另外,导演、主演组盘是否为最优组合,能否成为爆款?这是更加复杂的选择模式问题。今天面临的技术挑战是如何进行知识的抽取、挖掘以及推理,确定什么样的组合是最优解。
除上述两个问题,影片的拍摄过程更是一个庞大的系统工程和艺术创作过程。以《长安十二时辰》为例,该片非群演有约1000人,群演有300到1500人,历时7个月拍摄217天。我们参考软件工程行业,软件工程发展了70年,主要研究三个层面:方法论、过程以及工具,然后是如何将三者组合。软件行业的敏捷开发对于软件工程的质量和效率都有非常大的提升,如何将这些理论应用到内容制作产业,让内容制作敏捷起来?
内容敏捷即知晓过程对结果造成的影响是什么,并快速地调整内容创作过程,让它更敏捷。但内容行业面临的独有特点“延迟满足”,让用户在内容的某一分钟特别嗨,可能来自于前面的30分钟铺垫在那一分钟爆发了,针对内容的这个特点,我们除了要做基本的知识图谱语义的理解之外,还要考虑如何去做有效的对应分析,如何去做对应的知识抽取等问题。
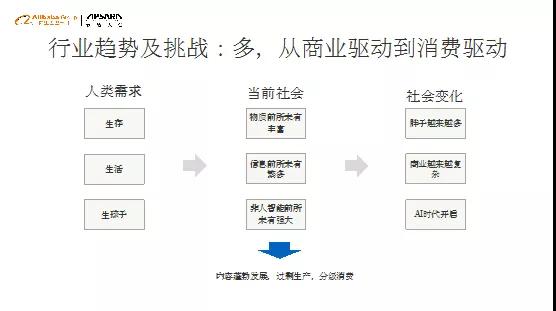

今天这个问题加剧了,比过去还要复杂。在过去的5到10年里,UPGC加上整个内容的生产量极大的发展,用户的消费分层化、多样化。全民爆款越来越少,用户对内容的需求更加个性化。相应于内容生产端,就需要考虑不同用户群的个性化需求。
二、文娱大脑基本框架:内容认知新动力
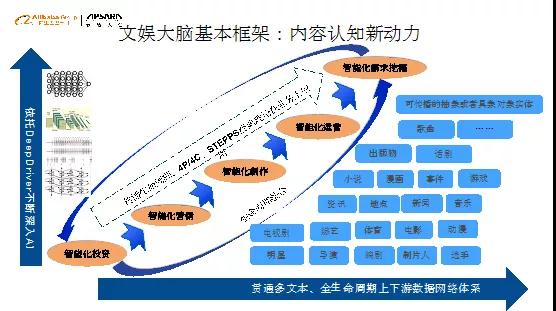
针对上面几大困难,我们今天在做文娱大脑——优酷北斗星智库来解决。我们将所有的内容形式和用户消费的数据都采集下来,将人工智能的技术手段、业务领域的细分理论做整合融合,构建内容认知框架。
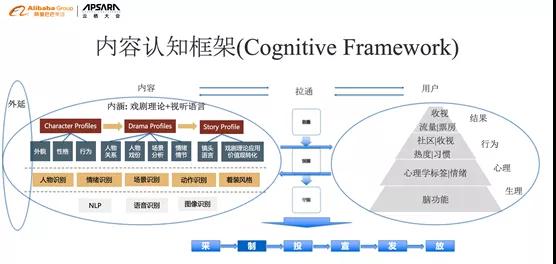
内容认知框架分为两部分,内容和用户。其思路就是心理学发展的基本的思路。
1)内容侧:对内容进行理解,包括外延和内涵。外延就是内容的各种基本属性,比如主创阵容、题材类型等;内涵主要研究内容的戏剧理论和视听语言,围绕制作内容的支撑要素,我们用传统的机器学习方式对内容进行理解,再基于戏剧理论和视听语言构造内容的衡量要素。
2)用户侧:分析用户的观看行为。用户行为来自于用户的心理偏好、心理情绪。用户心理偏好、心理情绪来自于生理构造,基于心理学的五大人格理论和用户的观看行为,构建模型建立左边和右边的连接,从而知道创造什么样的内容,用户会有什么样的感受。
三、贯穿全生命周期的文娱大脑生产力

基于内容认知框架,我们在内容生命周期的每个阶段都做了具体工作:开播前提供内容评估、艺人挖掘和内容情绪挖掘等能力;在早期为内容评估提供有效的数据支撑;在制作阶段提供现场解决方案,比之前更敏捷的反馈机制;同样在播出后也提供数据支持,实现更好的宣发。
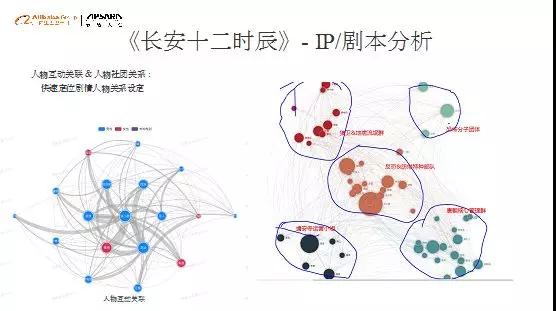
1、IP/剧本分析
上图是《长安十二时辰》的分析示例,我们把已有的剧本作为样本,让机器去学习,识别出剧本的所有角色,把角色直接交互的对白、行为识别出来,再进行社团的划分。《长安》剧本最终划分出来几个群体:反恐防暴小分队以张小敬为中心,唐朝核心管理团队以皇上为中心。通过这种方式快速定位整个剧本的人物和人物关系的展开。
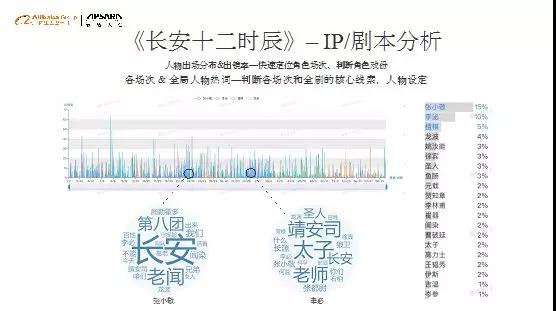
2、用户情绪识别与成片情绪挖掘
围绕角色关系,将整个剧本的角色情绪也识别出来,构造成如上的曲线。基于对海量剧本的分析曲线,抽取出各个指标(出镜率、戏份、情绪值等)并形成benchmark,对于之后的每一个剧本进行衡量,相当于对剧本进行一个“体检”。
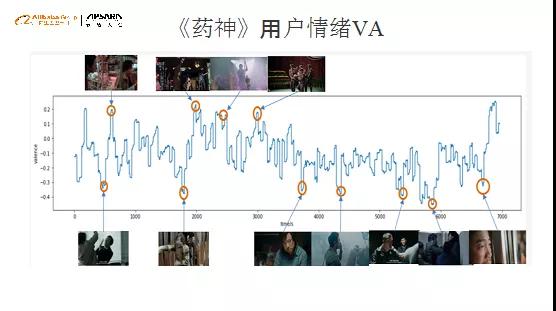
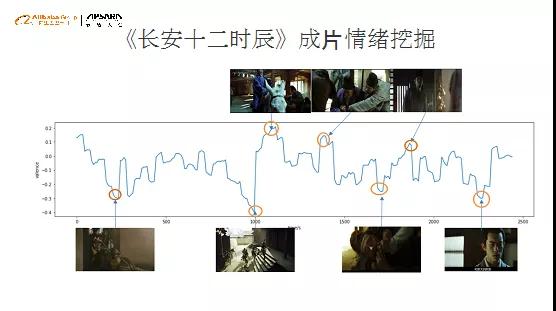
同样是“体检”的方法,对于《药神》和《长安十二时辰》,我们做了用户情绪的识别、体检的扫描,参考零线的位置。我们发现《药神》几乎都是正向和负向级的,直到最后出现一个正向区间,基本上后期都是以眼泪为主。而《长安十二时辰》的情绪状态比较稳定。对照情绪高低点的具体情节,我们发现,曲线表达的情绪和具体的故事情节是非常相符的。
3、情绪强度预测与网络收视率
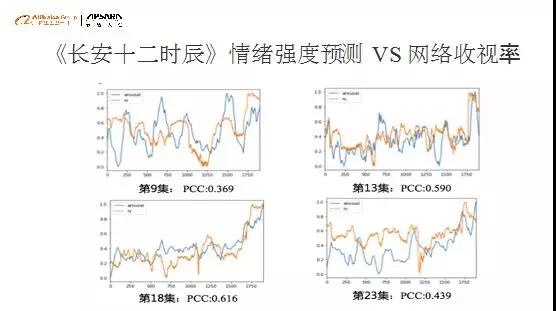
然后我们拿更多的方式去验证它的合理性,上图抽取《长安十二时辰》的剧集,每集有两条曲线,蓝线是刚才预测的情绪曲线,黄线是播放指数(表示每一秒钟有多少用户在看),通过两条曲线对比,我们可以发现,两条曲线的相关性比较高的将近60%,情绪的高峰、低谷和用户的观看行为状态是吻合的,由此我们就提供了一种能力,基于这种能力对剧本或影片做情绪扫描,实现对影片热度的未播先知,再对比benchmark,帮助制作者更高效的完成制作。
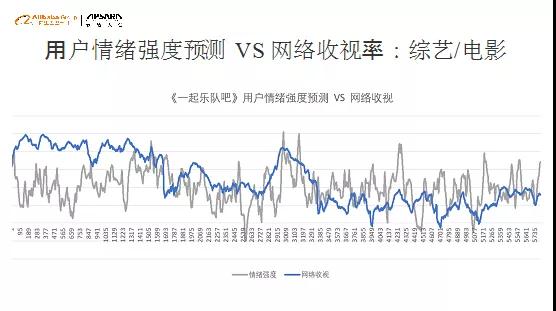
4、用户情感曲线在技术上是如何实现的?
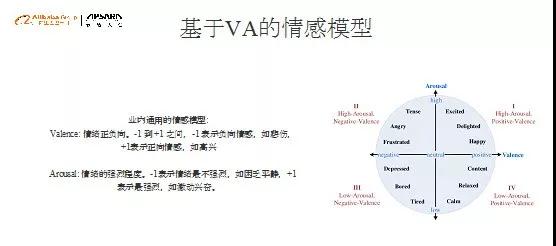
首先,我们把用户观影情绪的表述,映射到认知计算中常用的二维空间表示,也就是Valence 和Arousal。Valence表示情绪正负极性,Arousal表示情感激烈程度;
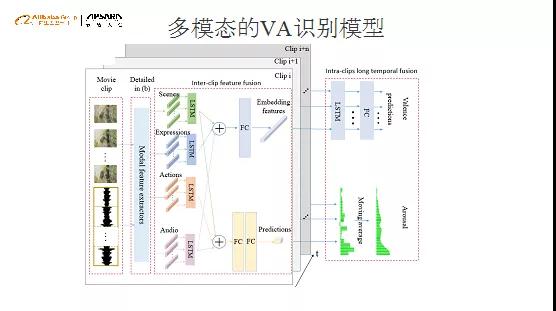
其次,基于情绪极性跟强度提供一个预测,这个是我们今年产出的论文。近两年,心理学研究的核心观点是为什么用户会感同身受?这来自于前两年的一个理论——静向神经元,所以我们选择场景、表情、动作以及声音作为基本的模型的输入,对模型参数进行学习。
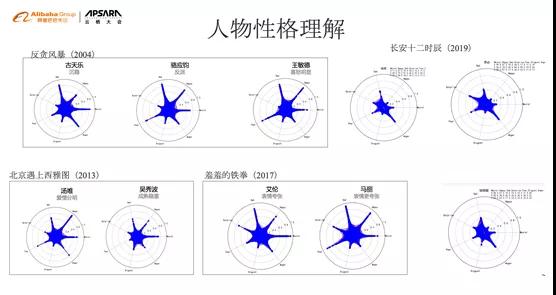
如上所讲,内容产业有强延迟满足的问题,我们通过两层分析来解决长短期满足的问题,除用户情绪分析,我们也做内容角色的情绪识别。通过图片表情识别模型,识别不同题材类型的影片,可以获得不同角色刻画的人物性格。如2004年的《反贪风暴》,时隔十多年,主创人物形象的脸谱还是正向的。上图显示的负面角色情绪以开心、害怕为主,正面形象以悲伤、生气为主,与负面反派的开心正好相对,正面的人一直很沮丧,是一个有些压抑角色形象。
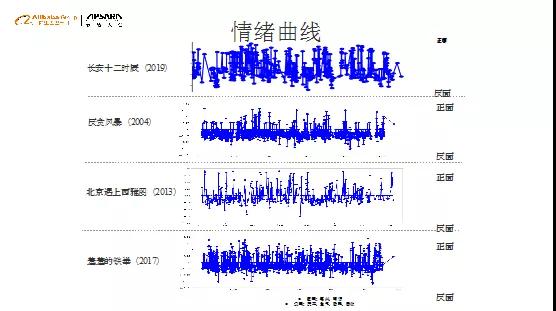
同样,我们分析角色的每秒情绪,形成角色的正负情绪曲线,部分影片的分析结果曲线如上图,不同题材类型的节目会有不同的情绪密度。所以,你想放松的时候,要看的不一定是喜剧,喜剧其实不一定会放松,因为角色的正负向情绪不停交替,由于延迟满足,大脑负荷非常大,需要做长短记忆,反而很多爱情片对大脑的占用相对低。
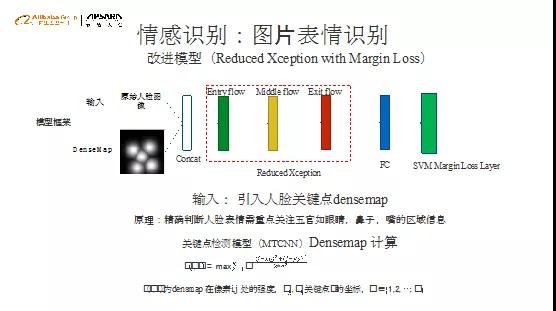

角色情绪检测是一个分类问题,所以利用人脸landmark对初始图像做识别,生成densemap作为附加通道,和原始图片RGB三通道拼接合并后作为模型输入,这样可以使densemap对应的关键区域权重更大,更容易让模型捕捉关键区域特征;合成的输入送入到Reduced Xception 网络进行特征提取;在loss方面,我们引入了基于SVM的marge loss,提升各情绪类别的类间差距,提升情绪识别的效果,具体如上图。
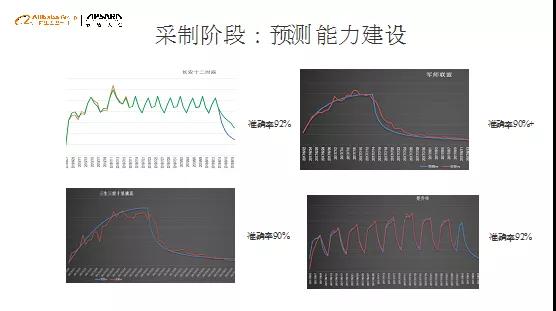
基于前面对内容的各种理解产生的各种纬度的内容的量化纬度,我们构建了预测模型,可以提前预测出节目的流量走势,如内容认知框架中所讲的,首先对内容进行量化,然后对内容相应的量化纬度进行提前的预测,为业务决策提供辅助支撑。 最后,分享我对未来趋势的一些见解。在强人工智能尚遥远的情形下,如何结合机器AI和人工经验将是个永恒主题。一是结合符号学派智能和链接学派智能,建设和完善决策引擎,包括结合人工逻辑规则和可学习数据AI,不确定性分析框架和经久不衰的贝叶斯因果决策,以及神经元化的混合智能计算框架。二是量化的心理学研究也越来越重要,如何结合大数据应用价值非常大。这也是阿里文娱大脑探索的方向。