













简介
Kafka是基于发布订阅的消息系统。最初起源于LinkedIn,于2011年成为开源Apache项目,然后于2012年成为Apache顶级项目。Kafka用Scala和Java编写,因其分布式可扩展架构及可持久化、高吞吐率特征而被广泛使用。
消息队列
通常在项目中,我们会因为如下需求而引入消息队列模块:
1.解耦:消息系统相当于在处理过程中间插入了一个隐含的、基于数据的接口层。无需预先定义不同的接口地址和请求应答规范,这允许数据上下游独立决定双方的处理过程,只需要约定数据格式即可任意扩展服务类型和业务需求。
2.缓冲:消息系统作为一个缓冲池,应对常见的访问量不均衡情形。比如特殊节假日的流量剧增和每日不同时段的访问量差异。以及处理不同数据类型所需的不同实时性。使整个业务处理架构以较低成本获得一定灵活性。
3. 异步:很多时候,用户不想也不需要立即处理消息。消息队列提供了异步处理机制,允许用户把一个消息放入队列,但并不立即处理它。想向队列中放入多少消息就放多少,然后在需要的时候再去处理它们。
Kafka的特点
作为一种分布式的,基于发布/订阅的消息系统。Kafka的主要设计目标如下:
1.以时间复杂度为O(1)的方式提供消息持久化能力,即使对TB级以上数据也能保证常数时间复杂度的访问性能。
2.高吞吐率。即使在非常廉价的商用机器上也能做到单机支持每秒100K条以上消息的传输。
3.支持Kafka Server间的消息分区,及分布式消费,同时保证每个Partition内的消息顺序传输。
4.同时支持离线数据处理和实时数据处理。
5.支持在线水平扩展。
Kafka体系架构
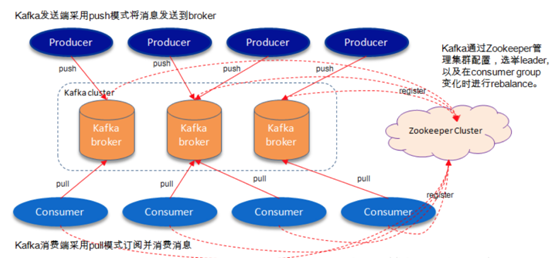
如上图所示,一个典型的Kafka体系架构包括若干Producer(可以是服务器日志,业 务数据,页面前端产生的page view等等),若干Broker(Kafka支持水平扩展,一般Broker数量越多,集群吞吐率越高),若干Consumer (Group),以及一个Zookeeper集群。Kafka通过Zookeeper管理集群配置,选举leader,以及在Consumer Group发生变化时进行rebalance。Producer使用push模式将消息发布到Broker,Consumer使用pull模式从Broker订阅并消费消息。
名词解释:

Topic & Partition
一个topic可以认为一个一类消息,每个topic将被分成多个partition,每个partition在存储层面是append log文件。任何发布到此partition的消息都会被追加到log文件的尾部,每条消息在文件中的位置称为offset(偏移量),offset为一个long型的数字,它唯一标记一条消息。每条消息都被append到partition中,顺序写磁盘因此效率非常高。这是Kafka高吞吐率的重要基础。
Producer发送消息到Broker时,会根据Paritition机制选择将其存储到哪一个Partition。如果Partition机制设置合理,所有消息可以均匀分布到不同的Partition里,这样就实现了负载均衡。如果一个Topic对应一个文件,那这个文件所在的机器I/O将会成为这个Topic的性能瓶颈,而有了Partition后,不同的消息可以并行写入不同Broker的不同Partition里,极大的提高了吞吐率。可以通过配置项num.partitions来指定新建Topic的默认Partition数量,也可在创建Topic时通过参数指定,同时也可以在Topic创建之后通过Kafka提供的工具修改。
Kafka的复制机制
Kafka 中的每个主题分区都被复制了 n 次,其中的 n 是主题的复制因子(replication factor)。这允许 Kafka 在集群服务器发生故障时自动切换到这些副本,以便在出现故障时消息仍然可用。Kafka 的复制是以分区为粒度的,分区的预写日志被复制到 n 个服务器。 在 n 个副本中,一个副本作为 leader,其他副本成为 followers。顾名思义,producer 只能往 leader 分区上写数据(读也只能从 leader 分区上进行),followers 只按顺序从 leader 上复制日志。
日志复制算法(log replication algorithm)必须提供的基本保证是,如果它告诉客户端消息已被提交,而当前 leader 出现故障,新选出的 leader 也必须具有该消息。在出现故障时,Kafka 会从失去 leader 的 ISR 里面选择一个 follower 作为这个分区新的 leader ;换句话说,是因为这个 follower 是跟上 leader 写进度的。
每个分区的 leader 会维护一个 ISR。当 producer 往 Broker 发送消息,消息先写入到对应 leader 分区上,然后复制到这个分区的所有副本中。只有将消息成功复制到所有同步副本(ISR)后,这条消息才算被提交。由于消息复制延迟受到最慢同步副本的限制,因此快速检测慢副本并将其从 ISR 中删除非常重要。 Kafka 复制协议的细节会有些细微差别。
Kafka的同步机制
Kafka不是完全同步,也不是完全异步,而是一种ISR(In-Sync Replicas)机制:
1. leader会维护一个与其基本保持同步的Replica列表,该列表称为ISR,每个Partition都会有一个ISR,而且是由leader动态维护 。
2. 如果一个follower比一个leader落后太多,或者超过一定时间未发起数据复制请求,则leader将其从ISR中移除
3. 当ISR中所有Replica都向Leader发送ACK时,leader才commit,这时候producer才能认为一个请求中的消息都commit了。
Kafka提供了数据复制算法保证,如果leader发生故障或挂掉,一个新leader被选举并被接受客户端的消息成功写入。Kafka确保从同步副本列表中选举一个副本为leader,或者说follower追赶leader数据。leader负责维护和跟踪ISR中所有follower滞后的状态。当Producer发送一条消息到Broker后,leader写入消息并复制到所有follower。消息提交之后才被成功复制到所有的同步副本。消息复制延迟受最慢的follower限制,重要的是快速检测慢副本,如果follower“落后”太多或者失效,leader将会把它从ISR中删除。
消息传输保障
前面已经介绍了Kafka如何进行有效的存储,以及了解了Producer和Consumer如何工作。接下来讨论的是Kafka如何确保消息在Producer和Consumer之间传输。有以下三种可能的传输保障(delivery guarantee):
- At most once: 消息可能会丢,但绝不会重复传输
- At least once:消息绝不会丢,但可能会重复传输
- Exactly once:每条消息肯定会被传输一次且仅传输一次
Kafka的消息传输保障机制非常直观。当Producer向Broker发送消息时,一旦这条消息被commit,由于副本机制(replication)的存在,它就不会丢失。但是如果Producer发送数据给Broker后,遇到的网络问题而造成通信中断,那producer就无法判断该条消息是否已经提交(commit)。虽然Kafka无法确定网络故障期间发生了什么,但是Producer可以retry多次,确保消息已经正确传输到Broker中,所以目前Kafka实现的是At least once。
Consumer从Broker中读取消息后,可以选择Commit,该操作会在Zookeeper中存下该Consumer在该Partition下读取的消息的offset。该Consumer下一次再读该Partition时会从下一条开始读取。如未commit,下一次读取的开始位置会跟上一次commit之后的开始位置相同。当然也可以将consumer设置为autocommit,即Consumer一旦读取到数据立即自动commit。如果只讨论这一读取消息的过程,那Kafka是确保了exactly once, 但是如果由于前面Producer与Broker之间的某种原因导致消息的重复,那么这里就是At least once。
考虑这样一种情况,当Consumer读完消息之后先commit再处理消息,在这种模式下,如果consumer在commit后还没来得及处理消息就crash了,下次重新开始工作后就无法读到刚刚已提交而未处理的消息,这就对应于At most once了。读完消息先处理再commit。这种模式下,如果处理完了消息在commit之前Consumer crash了,下次重新开始工作时还会处理刚刚未commit的消息,实际上该消息已经被处理过了,这就对应于at least once。
要做到exactly once就需要引入消息去重机制。Kafka文档中提及GUID(Globally Unique Identifier)的概念,通过客户端生成算法得到每个消息的unique id,同时可映射至broker上存储的地址,即通过GUID便可查询提取消息内容,也便于发送方的幂等性保证,需要在broker上提供此去重处理模块,目前版本尚不支持。
针对GUID, 如果从客户端的角度去重,那么需要引入集中式缓存,必然会增加依赖复杂度,另外缓存的大小难以界定。不只是Kafka, 类似RabbitMQ以及RocketMQ这类商业级中间件也只保障at least once, 且也无法从自身去进行消息去重。所以我们建议业务方根据自身的业务特点进行去重,比如业务消息本身具备幂等性,或者借助Redis等其他产品进行去重处理。
Kafka作为消息队列:
传统的消息有两种模式:队列和发布订阅。 在队列模式中,消费者池从服务器读取消息(每个消息只被其中一个读取); 发布订阅模式:消息广播给所有的消费者。这两种模式都有优缺点,队列的优点是允许多个消费者瓜分处理数据,这样可以扩展处理。但是,队列不像多个订阅者,一旦消息者进程读取后故障了,那么消息就丢了。而发布和订阅允许你广播数据到多个消费者,由于每个订阅者都订阅了消息,所以没办法缩放处理。
Kafka中的Consumer Group有两种形式:
a、队列:允许同名的消费者组成员共同处理。
b、发布订阅:广播消息给多个消费者组。
Kafka的每个topic都具有这两种模式。
传统的消息系统按顺序保存数据,如果多个消费者从队列消费,则服务器按存储的顺序发送消息,但是,尽管服务器按顺序发送,多个并行请求将会是异步的,因此消息可能乱序到达。这意味着只要消息存在并行消费的情况,顺序就无法保证。消息系统常常通过仅设1个消费者来解决这个问题,但是这意味着没用到并行处理。
Kafka有比传统的消息系统更强的顺序保证。通过并行Topic的Parition,Kafka提供了顺序保证和负载均衡。每个Partition仅由同一个消费者组中的一个消费者消费到。并确保消费者是该Partition的唯一消费者,并按顺序消费数据。每个topic有多个分区,则需要对多个消费者做负载均衡,但请注意,相同的消费者组中不能有比分区更多的消费者,否则多出的消费者一直处于空等待,不会收到消息。
Kafka作为存储系统
所有发布消息到消息队列和消费分离的系统,实际上都充当了一个临时存储系统。Kafka还是一个非常高性能的存储系统。写入到Kafka的数据将写到磁盘并复制到集群中保证容错性。并允许生产者等待消息应答,直到消息完全写入。Kafka的存储结构保证无论服务器上有50KB或50TB数据,执行效率是相似的,因此可达到水平扩展的目标。还可以认为Kafka是一种专用于高性能,低延迟,提交日志存储,复制,和传播特殊用途的分布式文件系统。
Kafka流处理
Kafka的更高目标是实时流处理。在Kafka中,流处理持续获取输入topic的数据,进行处理加工,然后写入输出topic。例如,一个零售APP,接收销售和出货的输入流,统计数量或调整价格后输出。
简单的需求可以直接使用Producer和Consumer API进行处理。对于复杂的转换,Kafka提供了更强大的Streams API,可构建聚合计算或连接流到一起的复杂应用程序。
综上所述,Kafka 的设计可以帮助我们解决很多架构上的问题。但是想要用好 Kafka 的高性能、低耦合、高可靠性等特性,我们需要非常了解 Kafka,以及我们自身的业务需求,综合考虑应用场景。
【本文是51CTO专栏机构“AiChinaTech”的原创文章,微信公众号( id: tech-AI)”】





















