近日,Netflix宣布开源Polynote,Polynote是Netflix自家使用的多语言笔记本环境,Polynote为数据科学家和机器学习研究人员提供了一个笔记本环境,允许他们将基于JVM的ML平台(此类平台大多使用Scala构建)与Python生态系统中流行的机器学习和可视化库无缝集成。

它已经在Netflix内部广泛使用,而且Netflix正在研究如何将Polynote和其他平台集成,下面一起详细来看看Polynote有哪些牛掰的功能特性:
功能概述
可重复性
Polynote的两个指导原则是可复制性和可见性。为了实现这两大特性,我们最早的设计决策之一是从头开始构建Polynote的代码解释,而不是像传统笔记本一样依赖REPL。
我们认为,尽管REPL总体上不错,但它们根本不适合笔记本电脑。为了了解REPL和笔记本的问题,让我们看一下典型笔记本环境的设计。
笔记本是单元格的有序集合,每个单元格可以保存代码或文本。每个单元格的内容可以独立修改和执行。单元格可以重新排列,插入和删除。这还可以取决于笔记本电脑中其他单元的输出。
将此与REPL环境进行对比会发现。在REPL会话中,用户把表达式一次一个地输入提示符。一旦求值,表达式及其求值结果是不可变的,求值结果将附加到下一个表达式可用的全局状态。
不幸的是,这两个模型之间的脱节意味着一个典型的notebook环境,它使用一个REPL会话来评估单元代码,当用户与notebook交互时,会导致隐藏状态积累。单元可以按任何顺序执行,从而改变这种全局隐藏状态,从而影响其他单元的执行。通常情况下,笔记本无法从顶部可靠地重新运行,这使得它们很难复制并与他人共享。这种隐藏状态也让用户很难推断笔记本上运行了什么。
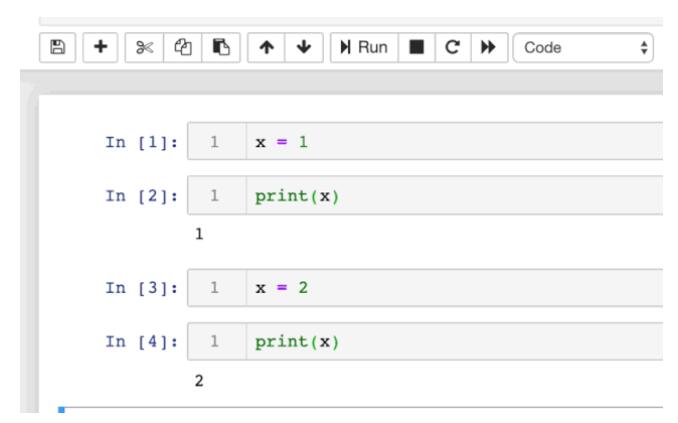
在其他笔记本中,隐藏状态意味着一个变量在其单元格被删除后仍然可用。
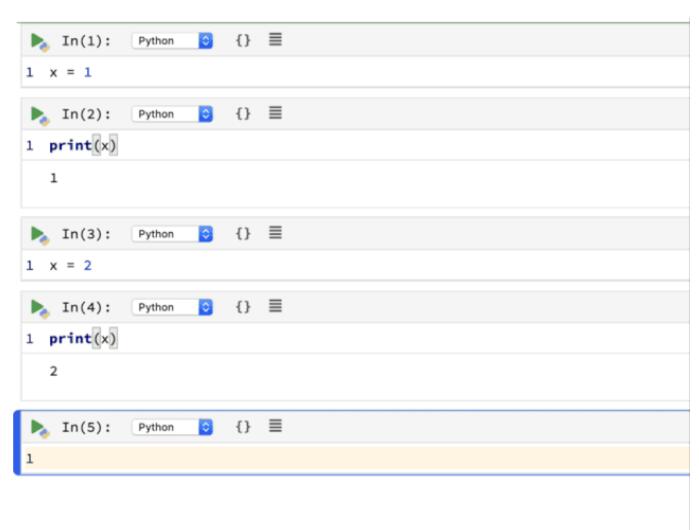
在 Polynote 笔记本中,没有隐藏状态,被删除的单元格变量不再可用。
从头编写Polynote的代码解释允许我们消除这种全局的、可变的状态。通过跟踪每个单元中定义的变量,Polynote根据在其上运行的单元构建给定单元的输入状态。使单元格的位置在其执行语义中变得重要,这也加强了最小惊奇原则,允许用户从上到下阅读笔记本。它通过让笔记本持续运行,从而确保其可重复性。
编辑改进
Polynote提供了诸如交互式自动完成和参数提示、错误高亮显示以及支持LaTeX富文本编辑器等类似ide的特性。
可见性
Polynote UI通过显示内核状态、突出显示当前正在运行的单元代码和当前正在执行的任务,从而让用户对内核状态的直观了解。
多语言
笔记本中的每个单元格都可以用不同的语言编写,变量可以在它们之间共享。目前支持Scala、Python和SQL语言类型。
依赖项和配置管理
Polynote 将配置和依赖项信息直接存入笔记本,而不依赖于外部文件或集群 / 服务器级别的配置。
数据可视化
本机数据探索和可视化帮助用户了解更多关于他们的数据,而不会弄乱他们的笔记本。与matplotlib和Vega的集成允许高级用户通过漂亮的可视化效果进行交互。
接下来,我们将更深入地了解Polynote的功能:
安装
安装过程是按照它的指南文档进行的,我还安装了matplotlib
- pip3 install matplotlib
如果你打算尝试它的多语言功能,则需要再添加一个环境变量:
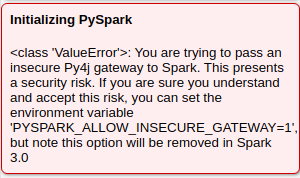
- export PYSPARK_ALLOW_INSECURE_GATEWAY=1
如果没有,你就会收到以下提示:
编辑体验
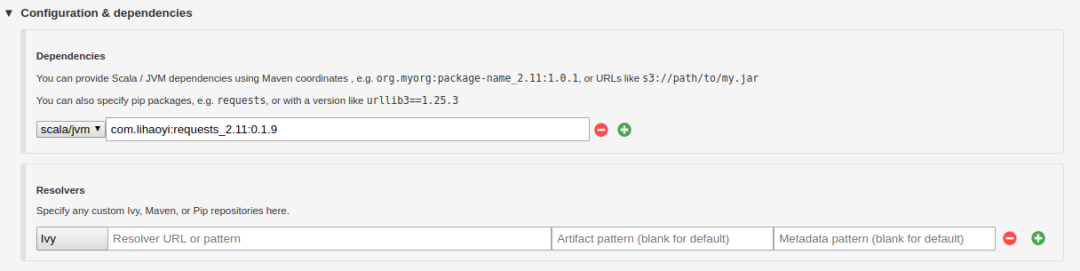
使用笔记本级别的“配置和依赖项”设置可以轻松地从maven存储库中提取依赖项,包括使用HTTP get从Netflix博客获取文本的请求:
自动完成功能适用于从Maven存储库中提取的库:

但是,lambda函数的自动完成功能似乎不起作用:

Spark示例
在这个字数统计示例中,我们从HTTP获取文本,对其进行标记,并保留所有大于4个字符的标记。
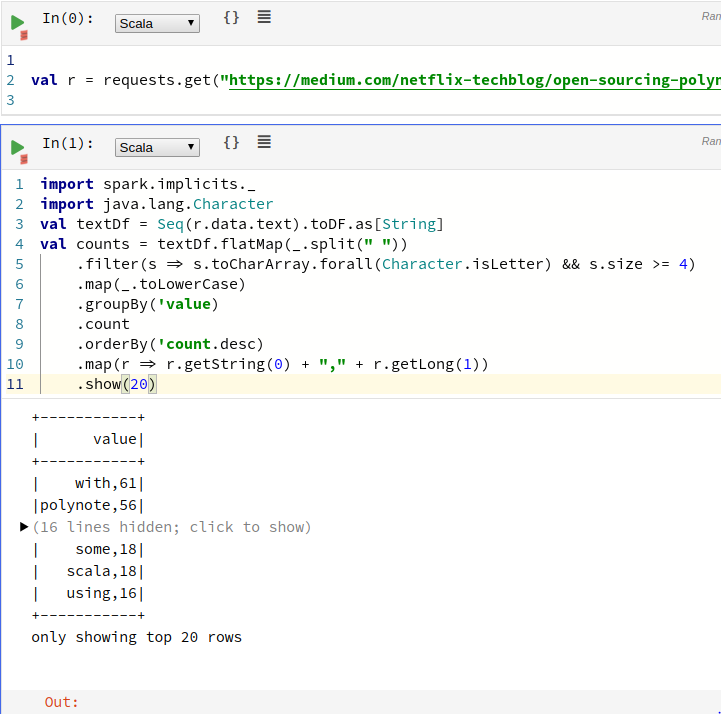
Spark也可以轻松配置“配置和依赖”设置:

切换到Python
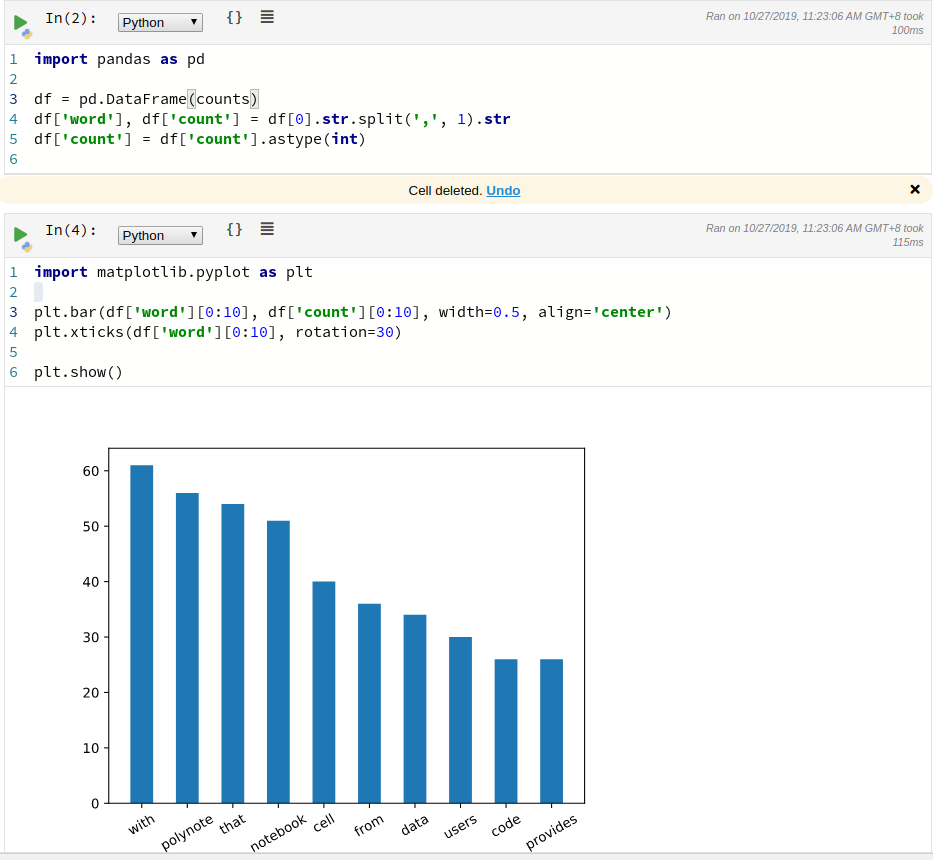
现在,我们切换到python,使用panda和matplotlib来绘制条形图,只选取前10个单词。
运行还算顺利,但是有时候会弹出以下警告:

当这种情况发生时,接口停止工作,惟一的解决方法就是终止Polynote进程并重启。
Polynote是迄今为止我尝试过的Spark和Scala最好的笔记本。虽然有些小故障,但是我相信很快就会修复
目前,Polynote已经在GitHub上标星2.6K,177个Fork(GitHub地址:https://github.com/polynote/polynote)如果对这个项目感兴趣,可以直接访问GitHub的源代码进行尝试。